My colleague Hervé Schweitzer reported a very interesting issue to me. It is about the usage of Grid Control 11g while monitoring the available space on an Oracle database – in our case a 10.2.0.3 target database. This post continues my last post about the free space management in a tablespace in relation to the recycle bin management.
While using Grid Control 11g (with PSU 3 – April 2011) we would like to check the free space in the tablespaces. Let’s focus on the tablespace CADP_DATA:
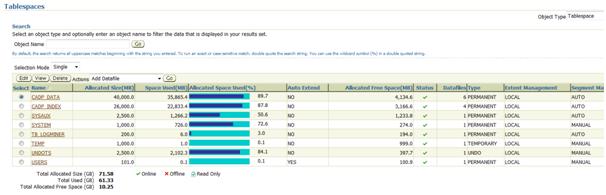
This tablespace has 89.7 % of the space allocated (extents used by any object). Just to make the things clear, no recycle bin objects (dropped objects, see my previous post) do allocate any space in a tablespace:
SQL> select * from dba_recyclebin; no rows selected
Now, let’s drill down to the datafile level of the tablespace – just click on the “CADP_DATA” link.
Obviously, something appears to be very strange: it seems that only between 1865 MB and 2865 MB of space is used in each datafile (each datafile is between 6 GB and 7 GB big):
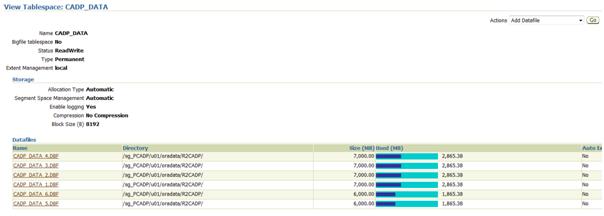
While performing the sum of the real used space we have about 15190 MB (15,19 GB) from a total of 40 GB of available datafiles. This is far away from the 89.7 % of reported allocated space.
We focus on the “datafile” view (click on → Server → Storage / Datafiles):
Here is what we see:
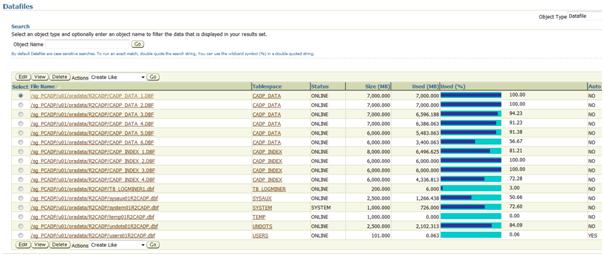
All the datafiles of the CADP_DATA tablespace have between 90% and 100% of used space. The last one has 2600 MB of remaining free space. This view is again coherent with the “tablespace” view (89.7% of the space is allocated).
So let’s try to identify why the datafile drill down view is somehow “buggy”. Honestly, my first thinking was that the package “dbms_space.free_space()” procedure was used in the calculation in order to provide the real used space (not the allocated one) for each datafile. However, with a database featuring thousands of objects, such a procedure would never come to an end!
So what can be the reason of this mystery? Hopefully this datafile space information is not reported by the agent but directly retrieved by the user you used to connect with on the target database. Therefore it becomes easy to identify the session and the SQL statement through the views v$session and v$sql. That’s exactly what I did once I clicked on the tablespace name to drill down to the datafile view (the statement was cached in v$sql):
SQL> r 1 select sid,serial#,program,username,status,sq.sql_text 2 from v$session ses, v$sql sq 3 where username = 'SYS' 4 and program = 'OMS' 5* and sq.address = ses.sql_address SID SERIAL# PROGRAM USERNAME STATUS ---------- ---------- ------------------------------------------------ ---------------------------- ------- SQL_TEXT ------------------------------------------------------------------------------------------------------------- 251 18403 OMS SYS INACTIVE
SELECT d.file_name, TO_CHAR((d.bytes / 1024 / 1024), ‘99999990.000’), NVL(TO_CHAR(((d.bytes – s.bytes) / 1024 / 1024), ‘99999990.000’), TO_CHAR((d.bytes / 1024 / 1024), ‘99999990.000’)), d.file_id, d.autoextensible, d.increment_by, d.maxblocks FROM sys.dba_data_files d, (SELECT ts.name tablespace_name, SUM(e.length * ts.blocksize) bytes FROM sys.fet$ e, sys.ts$ ts WHERE ts.ts# = e.ts# GROUP BY ts.name UNION ALL SELECT ts.name tablespace_name, SUM(e.blocks * ts.blocksize) bytes FROM sys.dba_lmt_free_space e, sys.ts$ ts WHERE ts.ts# = e.tablespace_id GROUP BY ts.name) s WHERE (s.tablespace_name = d.tablespace_name) AND (d.tablespace_name = :1)
It then became very easy to start this statement with the following condition “d.tablespace_name = ‘CADP_DATA’” in order to get the following result:
SQL> r 1 SELECT d.file_name, 2 TO_CHAR((d.bytes / 1024 / 1024), '99999990.000'), 3 NVL(TO_CHAR(((d.bytes - s.bytes) / 1024 / 1024), '99999990.000'), 4 TO_CHAR((d.bytes / 1024 / 1024), '99999990.000')), 5 d.file_id, 6 d.autoextensible, 7 d.increment_by, 8 d.maxblocks 9 FROM sys.dba_data_files d,(SELECT ts.name tablespace_name, SUM(e.length * ts.blocksize) bytes 10 FROM sys.fet$ e, sys.ts$ ts WHERE ts.ts# = e.ts# GROUP BY ts.name 11 UNION ALL SELECT ts.name tablespace_name, SUM(e.blocks * ts.blocksize) bytes 12 FROM sys.dba_lmt_free_space e, sys.ts$ ts WHERE ts.ts# = e.tablespace_id GROUP BY ts.name) s 13* WHERE (s.tablespace_name = d.tablespace_name) AND (d.tablespace_name = 'CADP_DATA') FILE_NAME TO_CHAR((D.BY NVL(TO_CHAR(( FILE_ID AUT INCREMENT_BY MAXBLOCKS -------------------------------------------------- ------------- ------------- ---------- --- ------------ ---------- /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_4.DBF 7000.000 2863.375 10 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_3.DBF 7000.000 2863.375 9 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_2.DBF 7000.000 2863.375 8 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_1.DBF 7000.000 2863.375 7 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_6.DBF 6000.000 1863.375 15 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_5.DBF 6000.000 1863.375 13 NO 0 0 6 rows selected.
Hopefully, we get exactly the same result as the buggy view in Grid Control:
Let’s have a deeper look at the SQL statement itself. The sub-select identified with the “s” alias (in bold) accesses on the fet$ table (for dictionary managed tablespaces) and dba_lmt_free_space view (for locally managed tablespaces). However it is strange to decrement the free space of the TABLESPACE from the size of the DATAFILE! And that’s exactly what this query is doing: there is a mix up between the datafile sizes and the tablespace sizes – therefore this error.
With some minor engineering we can fix this select statement to get the correct information. Do not forget the outer join for the FILE_ID, in order to also retrieve the files without free space:
SQL> r 1 SELECT d.file_name, 2 TO_CHAR((d.bytes / 1024 / 1024), '99999990.000'), 3 NVL(TO_CHAR(((d.bytes - s.bytes) / 1024 / 1024), '99999990.000'), 4 TO_CHAR((d.bytes / 1024 / 1024), '99999990.000')), 5 d.file_id, 6 d.autoextensible, 7 d.increment_by, 8 d.maxblocks 9 FROM sys.dba_data_files d, ( SELECT e.file# s_file_id, sum(e.length * ts.blocksize) bytes 10 FROM sys.fet$ e, sys.ts$ ts 11 WHERE ts.ts# = e.ts# 12 GROUP BY e.file# 13 UNION ALL SELECT e.file_id s_file_id, sum(e.blocks * ts.blocksize) bytes 14 FROM sys.dba_lmt_free_space e, sys.ts$ ts 15 WHERE ts.ts# = e.tablespace_id 16 GROUP BY e.file_id) s 17 WHERE (s.s_file_id (+) = d.file_id) AND (d.tablespace_name = 'CADP_DATA') 18* order by 1 FILE_NAME TO_CHAR((D.BY NVL(TO_CHAR(( FILE_ID AUT INCREMENT_BY MAXBLOCKS -------------------------------------------------- ------------- ------------- ---------- --- ------------ ---------- /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_1.DBF 7000.000 7000.000 7 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_2.DBF 7000.000 7000.000 8 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_3.DBF 7000.000 6596.188 9 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_4.DBF 7000.000 6386.063 10 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_5.DBF 6000.000 5484.063 13 NO 0 0 /sg_PCADP/u01/oradata/R2CADP/CADP_DATA_6.DBF 6000.000 3401.063 15 NO 0 0
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/YAN_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)