SQL Server 2014 introduces hash indexes with in-memory optimized tables. I described some of their aspects in a previous blog post. These indexes are very efficient with lookup search operations but have some limitations with operations like range scans, inequality predicates or scan order operations. These limitations are linked to hash index design that stores rows in the index in a random order. Fortunately, nonclustered indexes for in-memory optimized tables (aka range indexes or Bw-Tree) solve this issue and, like hash indexes, involve a data row chain at their own structure in the leaf level.
In this blog post I would like to share with you an interesting consideration about the Bw-Tree storage. Like a traditional b-tree index structure, accessing in-memory table data rows themselves requires first to go through the Bw-Tree structure prior to retrieve the corresponding row data in the chain. At the leaf level of the Bw-Tree we have different pointers to the first concerned data in the row chain. Pages in the index are linked together by logical pointers (called page identifiers or PID). This PID is then translated to a physical address or a flash offset of a page in memory or to a stable media storage. The Bw-Tree layer interacts with the cache layer that abstracts physical page by using a mapping table that maps logical pages to physical pages. Beside, others non-leaf pages in the Bw-Tree structure use the same mechanism. Here a simplified schema for retrieving the data through the Bw-Tree structure :
Bw-Tree –> Mapping Table –> Physical Page
Abstracting the physical layer has some advantages. Indeed, changing the physical location of a page requires only to change to corresponding mapping to the mapping table. The Bw-Tree path will not be affected by this change because each page is logical with their own PID.
Now let’s demonstrate an interesting behaviour of Bw-Tree (range indexes) with several extreme tests. We create an in-memory optimized table named hekaton_table with the following definition:
This table contains a hash index as a primary key on the id column and a nonclustered range index idx_hekaton_table_col1 that concerns the col1 column. We will use the DMVs sys.dm_db_xtp_nonclustered_index_stats, sys.dm_db_xtp_memory_consumers and sys.dm_db_xtp_xtp_memory_stats during the test.
The first DMV sys.dm_db_xtp_nonclustered_index_stats includes statistics about operations on nonclustered indexes in memory-optimized tables.
![]()
The second DMV sys.dm_db_xtp_memory_consumers provides useful information about the memory consumers. We are concerned by the Range index heap consumer for this example.
![]()
The third DMV sys.dm_db_xtp_table_memory_stats provides information about the size of an in-memory table into the memory.
For the first test we will introduce 200K rows of data in the col1 column with a high cardinality. All rows will have a distinct value.
Then we take a look to result of the all DMVs:
- sys.dm_db_xtp_nonclustered_index_stats
![]()
- sys.dm_db_xtp_memory_consumers
![]()
- sys.dm_db_xtp_xtp_memory_stats
![]()
With the second test we will introduce the same number of data rows in the col1 column with a low cardinality. All rows will have the same value. Here the results of the second test:
- sys.dm_db_xtp_nonclustered_index_stats
![]()
- sys.dm_db_xtp_memory_consumers
![]()
- sys.dm_db_xtp_xtp_memory_stats
![]()
Wow! Only one leaf pages with 400 bytes used during the second test versus 5363 pages allocated with 26485848 bytes during the first test. We retrieve the same total size for the in-memory data itself (29687 KB). What’s the matter? In fact, there is a big difference between traditional nonclustered indexes and Bw-Tree. Indeed, unlike a traditional nonclustered indexes where there is a pointer per row regardless the uniqueness of the index key the Bw-Tree has only one pointer per unique index value thus change the amount of storage used. For a table stored in memory that’s an interesting optimization 😀
How about the data inserted during the second test? : Rows with the same value are grouped in the same row chain as showed below :
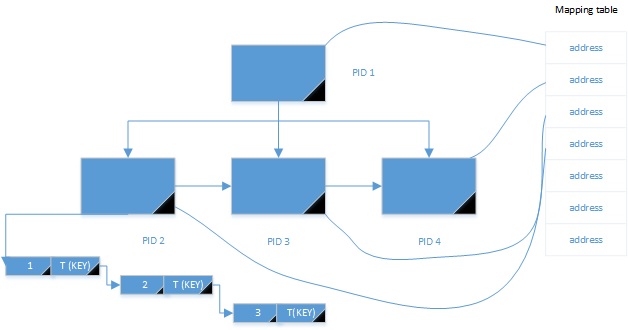
The use of the sys.dm_db_xtp_nonclustered_index_stats DMV also introduces new pages concepts. I advice you the reading of the Microsoft research about Bw-Tree . As seen above there is two others pages type columns: the internal pages that represent the top level of the Bw-Tree (root and nonleaf pages in a classic B-Tree structure) and delta pages that are “special pages” that contains an operation code (insert, delete) and a memory value which is the memory address in the first row in a chain of records. These pages are part of a special mechanism that allow to incrementally update page state in a latch-free manner. Remember with in-memory tables locks and latchs does not exist anymore! I will prepare a future blog post dedicated to this interesting mechanism !
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)