SQL Server 2017 is available on multiple platforms: Windows, Linux and Docker. The latter provides containerization features with no lengthy setup and special prerequisites before running your SQL Server databases which are probably the key success of adoption for developers.
It was my case as developer for our DMK management kit which provide to our customers a SQL Server database maintenance solution on all editions from SQL Server 2005 to SQL Server 2017 (including Linux). In the context of our DMK, we have to develop for different versions of SQL Server, including cumulative updates and service packs that may provide new database maintenance features and it may be challenging when we often have to release a new development / fix or and to perform unit tests on different SQL Server versions or platforms. At this stage you may certainly claim that virtualization already addresses those requirements and you’re right because we used a lot of provisioned virtual machines on Hyper-V so far.
The obvious question is why to switch to Docker container technologies? Well, for different reasons in reality. Firstly, sharing my SQL Server containers and test databases with my team is pretty straightforward. We may use a Docker registry and use docker push / pull commands. Then, provisioning a new SQL Server instance is quicker with containers than virtual machines and generally lead to lower CPU / Memory / Disk footprint on my laptop. I talked a little bit about it in the last SQL Pass meetup in Geneva by the way.
But in this blog post I would like to take another step with Docker and to go beyond the development area. As DBA we may have to deal with container management in production in the near future (unless it is already done for you 🙂 ) and we need to get a more global picture of the Docker echosystem. I remembered a discussion with an attendee during my SQL Server Docker and Microservices session in the last TugaIT 2017 Lisbon who told me Docker and containers are only for developers and not suitable for production. At the time of this discussion, I had to admit he was not entirely wrong. Firstly, let’s say that as virtualization before, based-container application adoption will probably take time. This is at least what I may concluded from my experience and from what I may notice around me, even if DevOps and microservices architectures seem to contribute to improve the situation. This is probably because production environments introduce other challenges and key factors than those we may have on development area as service availability, patching or upgrading stuff, monitoring and alerting, performance …. In the same time, Docker and more generally speaking container technologies are constantly maturing as well as tools to manage such infrastructures and in production area, as you know, we prefer to be safe and there is no room to no stable and non-established products that may compromise the core business.
So, we may wonder what’s the part of the DBAs in all of this? Well, regardless the underlying infrastructure we still have the same responsibilities as to provide configuration stuff, to ensure databases are backed up, to manage and to maintain data including performance, to prevent security threats and finally to guarantee data availability. In fact, looking back to last decade, we already faced exactly the same situation with the emergence of virtualization paradigm where we had to install our SQL Server instance in such infrastructures. I still remember some reluctance and heated discussions from DBAs.
From my side, I always keep in mind high availability and performance because it is the most concern of my customers when it comes to production environments. So, I was curious to dig further on container technologies in this area and with a first start on how to deal with different orchestration tools. The main leaders on the market are probably Docker Swarm, Kubernetes, Mesosphere, CoreOS fleet (recently acquired by RedHat), RedHat OpenShift, Amazon ECS and Azure Container Services.
In this first blog, I decided to write about Docker Swarm orchestrator probably because I was already comfortable with native Docker commands and Docker Swarm offers additional set of docker commands. When going into details, the interesting point is that I discovered a plenty of other concepts which lead me to realize I was reaching another world … a production world. This time it is not just about pulling / pushing containers for sure 🙂 Before to keep reading this blog post, it is important to precise that it is not intended to learn about how to implement Docker Swarm. Docker web site is well-designed for that. My intention is just to highlight some important key features I think DBAs should to be aware before starting managing container infrastructures.
Firstly, implementing a Docker Swarm requires to be familiar with some key architecture concepts. Fortunately, most of them are easy to understand if you are already comfortable with SQL Server and cluster-based architectures including SQL FCIs or availability groups.
Let’s have a look at the main components:
- Nodes: A node is just an instance of docker engine participating in swarm
- Manager nodes: They are firstly designed to dispatch units of works (called tasks tied to containers) to worker nodes according your service definition
- Worker nodes: Receive and execute tasks dispatched from manager nodes
Here was my first implementation of my Docker lab infrastructure:

It was composed of 3 docker nodes and one of them acted as a both worker and manager. Obviously, this is not an ideal scenario to implement on production because this architecture lacks of fault-tolerance design. But anyway, that was enough to start with my basic container labs.
I use a Docker Server version 17.12.0 CE and as shown below swarm mode is enabled.
$sudo docker info Containers: 13 Running: 4 Paused: 0 Stopped: 9 Images: 37 Server Version: 17.12.0-ce Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Native Overlay Diff: true Logging Driver: json-file Cgroup Driver: cgroupfs Plugins: Volume: local Network: bridge host macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog Swarm: active NodeID: 7a9v6uv6jur5cf8x3bi6ggpiz Is Manager: true ClusterID: 63pdntf40nzav9barmsnk91hb Managers: 1 Nodes: 3 Orchestration: Task History Retention Limit: 5 The IP address of the manager is reachable from the host operation system … $ sudo docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS s6pu7x3htoxjqvg9vilkoffj1 sqllinux2.dbi-services.test Ready Active ptcay2nq4uprqb8732u8k451a sqllinux3.dbi-services.test Ready Active 7a9v6uv6jur5cf8x3bi6ggpiz * sqllinux.dbi-services.test Ready Active Leader
Here the IP address of the manager (sqllinux node) used during the swarm initialization with –advertise-addr parameter. Tu put it simply, this is the address used by other nodes to connect into this node during the joining phase.
There are a plenty of options to configure and to change the behavior of the swarm. Some of them concern resource and placement management and as DBA it makes sense to know how such infrastructures behave on your database environments regarding these settings. Maybe in a next blog post.
$ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:15:5d:00:13:4b brd ff:ff:ff:ff:ff:ff
inet 192.168.40.20/24 brd 192.168.40.255 scope global eth0
I also opened the required ports on each node
- TCP port 2376 for secure docker client communication (Docker machine)
- TCP port 2377 for cluster management communications
- TCP and UDP port 7946 for communication among nodes
- UDP port 4789 for overlay network traffic (container ingress networking)
$ sudo firewall-cmd --list-all public (active) target: default icmp-block-inversion: no interfaces: eth0 sources: services: dhcpv6-client ssh nfs mountd rpc-bind ports: 2376/tcp 2377/tcp 7946/tcp 7946/udp 4789/udp 80/tcp 1433/tcp 8080/tcp protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:
After initializing the swarm, the next step will consist in deploying the containers on it. The point here is the swarm mode changes a little bit the game because you have to deal with service or stacks (collection of services) deployment rather than using container deployment. It does mean you cannot deploy directly containers but you won’t benefit from swarm features in this case.
Let’s continue with stack / service model on docker. Because a picture is often worth a thousand words I put an overview of relationship between stacks, services and tasks.
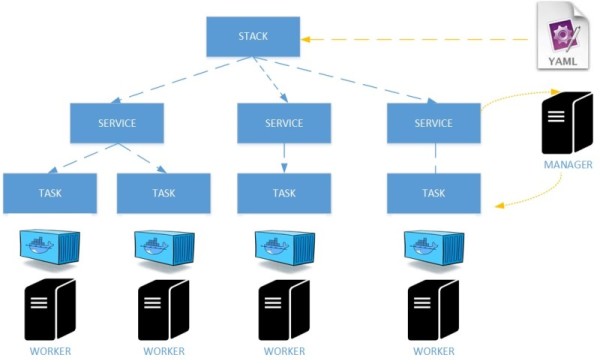
You may find the definition of each component in the docker documentation but let’s make a brief summary of important things: services are the primary location of interactions with the swarm and includes the definition of tasks to execute on the manager or worker nodes. Then tasks carry Docker containers and commands to run inside. Maybe the most important thing to keep in mind here: /!\Once a task is assigned to a node, it cannot move to another node. It can only run on the assigned node or fail /!\. This is a different behavior from virtualized architectures when you may go through different features to move manually one virtual machine from one host to another one (VMotion, DRS for VMware …). Finally, a stack is just a collection of services (1-N) that make up an application on a specific environment.
From a user perspective, you may deploy directly a service or to go through a stack definition if you have to deal with an application composed of several services and relationships between them. For the latter, you may probably guess that this model is pretty suitable with microservices architectures. These concepts may seem obscure but with practice they become clearer.
But just before introducing services deployment models, one aspect we did not cover so far is the storage layout. Docker has long been considered as designed for stateless applications and storage persistence a weakness in the database world. Furthermore, from a container perspective, it is always recommended to isolate the data from a container to retain the benefits of adopting containerization. Data management should be separate from the container lifecycle. Docker has managed to overcome this issue by providing different ways to persist data outside containers since the version 1.9 including the capabilities to share volumes between containers on the same host (aka data volumes). But thinking about production environments, customers will certainly deploy docker clusters rending these options useless and the containers non-portables as well. In my context, I want to be able to share data containers on different hosts and the good news is Docker provide distributed filesystem capabilities. I picked up NFS for convenience but it exists other solutions like Ceph or GluterFS for instance. A direct mapping between my host directory and the directory inside my SQL Server container over a distributed storage based on a NFS share seems to work well in my case. From a SQL Server perspective this is not an issue as long as you deploy the service with a maximum of one replica at time to avoid data corruption. My updated architecture is as following:
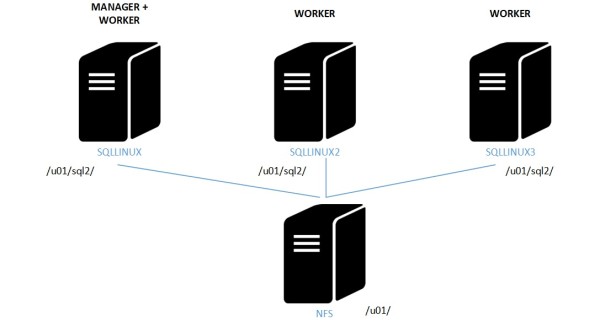
Here the configuration from one node concerning the mount point based on NFS share. Database files will be stored on /u01/sql2 in my case.
$ cat /etc/fstab /dev/mapper/cl-root / xfs defaults 0 0 UUID=eccbc689-88c6-4e5a-ad91-6b47b60557f6 /boot xfs defaults 0 0 /dev/mapper/cl-swap swap swap defaults 0 0 /dev/sdb1 /u99 xfs defaults 0 0 192.168.40.14:/u01 /u01 nfs nfsvers=4.2,timeo=14,intr 0 0 $ sudo showmount -e 192.168.40.14 Export list for 192.168.40.14: /u01 192.168.40.22,192.168.40.21,192.168.40.20
My storage is in-place and let’s continue with network considerations. As virtualization products, you have different option to configure network:
- Bridge: Allows internal communication between containers on the same host
- docker_gwbridge : Network created when the swarm is installed and it is dedicated for the communication between nodes
- Ingress: All nodes by default participate to ingress routing mesh. I will probably introduce this feature in my next blog post but let’s say that the routing mesh enables each node in the swarm to accept connections on published ports for any service running in the swarm, even if there’s no task running on the node
- Overlay: The manager node automatically extends the overlay network to nodes that run service tasks to allow communication between host containers. Not available if you deploy containers directly
Let’s add that Docker includes an embedded DNS server which provides DNS resolution among containers connected to the same user defined network. Pretty useful feature when you deploy applications with dependent services!
So, I created 2 isolated networks. One is dedicated for back-end server’s communication (backend-server) and the other one for the front-end server’s communication (frontend-server).
$sudo docker network create \ --driver overlay \ --subnet 172.20.0.0/16 \ --gateway 172.20.0.1 \ backend-server $sudo docker network create \ --driver overlay \ --subnet 172.19.0.0/16 \ --gateway 172.19.0.1 \ frontend-server $ sudo docker network ls NETWORK ID NAME DRIVER SCOPE oab2ck3lsj2o backend-server overlay swarm 1372e2d1c92f bridge bridge local aeb179876301 docker_gwbridge bridge local qmlsfg6vjdsb frontend-server overlay swarm 8f834d49873e host host local 2dz9wi4npgjw ingress overlay swarm
we are finally able to deploy our first service based on SQL Server on Linux image:
$ sudo docker service create \ --name "sql2" \ --mount 'type=bind,src=/u01/sql2,dst=/var/opt/mssql' \ --replicas 1 \ --network backend-server \ --env "ACCEPT_EULA=Y" --env "MSSQL_SA_PASSWORD=P@$w0rd1" \ --publish published=1500,target=1433 \ microsoft/mssql-server-linux:2017-latest
Important settings are:
- –name “sql2” = Name of the service to deploy
- –replicas 1 = We tell to the manage to deploy only on one replica of the SQL Server container at time on docker workers
- — mount ‘type=bind,src=…,dst=…’ = Here we define the data persistence strategy. It will map the /u01/02 folder directory on the host with /var/opt/mssql directory within the container. If we shutdown or remove the container the data is persisted. If container moves to another docker node, data is still available thank to the distributed storage over NFS.
- –network back-endserver = we will attach the sql2 service to the back-endserver user network
- microsoft/mssql-server-linux:2017-latest = The container based-image used in this case (Latest image available for SQL Server 2017 on Linux)
After deploying the sql2 service, let’s have a look at services installed from the manager. We get interesting output including the service name, the replication mode and the listen port as well. You may notice replication mode is set to replicated. In this service model, the swarm distributes a specific number of replicas among nodes. In my context I capped the number of maximum task to 1 as discussed previously.
$ sudo docker service ls ID NAME MODE REPLICAS IMAGE PORTS ih4e2acqm2dm registry replicated 1/1 registry:2 *:5000->5000/tcp bqx1u9lc8dni sql2 replicated 1/1 microsoft/mssql-server-linux:2017-latest *:1433->1433/tcp
Maybe you have noticed one additional service registry. Depending on the context, when you deploy services the correspond based-images must be available from all the nodes to be deployed. You may use images stored in public docker registry and to use a private one if you deploy internal images.
Let’s dig further by looking at the tasks associated to the sql2 service. We get other useful information as the desired state, current state and the node where the task is running.
$ sudo docker service ls ID NAME MODE REPLICAS IMAGE PORTS ih4e2acqm2dm registry replicated 1/1 registry:2 *:5000->5000/tcp bqx1u9lc8dni sql2 replicated 1/1 microsoft/mssql-server-linux:2017-latest *:1433->1433/tcp
Maybe you have noticed one additional service registry. Depending on the context, when you deploy services the correspond based-images must be available from all the nodes to be deployed. You may use images stored in public docker registry and to use a private one if you deploy internal images.
Let’s dig further by looking at the tasks associated to the sql2 service. We get other useful information as the desired state, current state and the node where the task is running.
$ sudo docker service ps sql2 ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS zybtgztgavsd sql2.1 microsoft/mssql-server-linux:2017-latest sqllinux3.dbi-services.test Running Running 11 minutes ago
In the previous example I deployed a service that concerned only my SQL Server instance. For some scenarios it is ok but generally speaking a back-end service doesn’t come alone on container world and it is often part of a more global application service architecture. This is where stack deployment comes into play.
As stated to the Docker documentation stacks are a convenient way to automatically deploy multiple services that are linked to each other, without needing to define each one separately. Stack files include environment variables, deployment tags, the number of services and dependencies, number of tasks to deploy, related environment-specific configuration etc… If you already dealt with docker-compose files to deploy containers and dependencies you will be comfortable with stack files. The stack file is nothing more than a docker-compose file adjusted for stack deployments. I used one to deploy the app-voting application here. This application is composed to 5 services including Python, NodeJS, Java Worker, Redis Cache and of course SQL Server.
Here the result on my lab environment. My SQL Server instance is just a service that composes the stack related to my application. Once again you may use docker commands to get a picture of the stack hierarchy.
$ sudo docker stack ls NAME SERVICES myapp 5 $ sudo docker stack services myapp ID NAME MODE REPLICAS IMAGE PORTS fo2g822czblu myapp_worker replicated 1/1 127.0.0.1:5000/examplevotingapp_worker:latest o4wj3gn5sqd2 myapp_result-app replicated 1/1 127.0.0.1:5000/examplevotingapp_result-app:latest *:8081->80/tcp q13e25byovdr myapp_db replicated 1/1 microsoft/mssql-server-linux:2017-latest *:1433->1433/tcp rugcve5o6i7g myapp_redis replicated 1/1 redis:alpine *:30000->6379/tcp tybmrowq258s myapp_voting-app replicated 1/1 127.0.0.1:5000/examplevotingapp_voting-app:latest *:8080->80/tcp
So, let’s finish with the following question: what is the role of DBAs in such infrastructure as code? I don’t pretend to hold the truth but here my opinion:
From an installation and configuration perspective, database images (from official editors) are often released without neither any standard nor best practices. I believe very strongly (and it seems I’m aligned with the dbi services philosophy on this point) that the responsibility of the DBA team here is to prepare, to build and to provide well-configured images as well as related deployment files (at least the database service section(s)) related to their context – simple containers and more complex environments with built-in high availability for instance.
In addition, from a management perspective, containers will not really change the game concerning the DBA daily job. They are still responsible of the core data business regardless the underlying infrastructure where database systems are running on.
In this blog post we just surfaced the Docker Swarm principles and over the time I will try to cover other important aspects DBAs may have to be aware with such infrastructures.
See you!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)