MongoDB is an open source NoSQL database management system document-oriented. MongoDB allows the manipulation of structured and unstructured data. It is schema-less and can be used to store a large data volume. This blog is explaining the main principle of the DBMS.
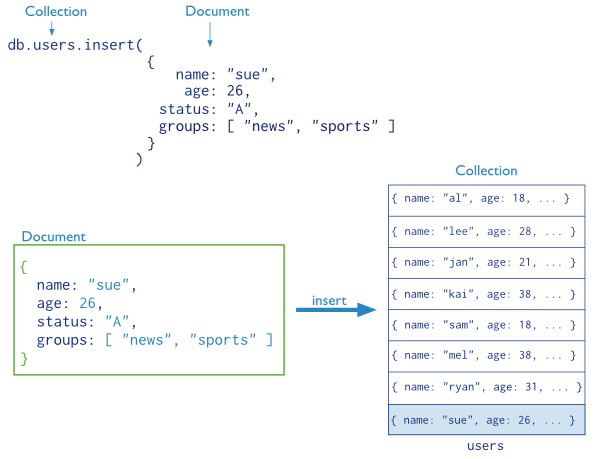
MongoDB stores data in documents. These documents are stored in BSON types, the JSON binary format. Actually, we manipulate the JSON documents in the MongoDB shell where they are encapsulated into collections. A document is composed of key-value pairs.
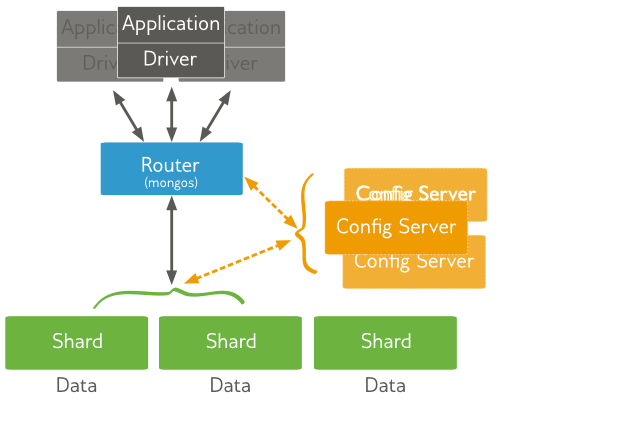
MongoDB architecture
Basically, MongoDB is designed to work on a cluster which distributes data across multiple servers of your architecture. You also can use MongoDB as a standalone server, without clustering. Furthermore, you can replicate your data through multiple servers. By the way, the concept of replication will be explained in an upcoming blog. MongoDB provides features and concepts, however it is important to deploy an adapted architecture which best suits your business needs.
Why using MongoDB?
MongoDB provides some interesting features for your application and your architecture:
- Horizontal Scalability (sharding): adding more machines of increasing the performance of machines.
- High availability (replication): data durability, disaster recovery.
- Flexibility of the data model, no predictive schema, the design of data models can be tailored for applications .
- Unstructured data can be handled
MongoDB Data format
{
"_id" : ObjectId("56951380c9b9fd993a4dc4ab"),
"city" : "Delémont",
"zip" : "2800",
"loc" : {
"y" : 47.3667,
"x" : 7.3333
},
"state" : "Jura"
}
Documents are encapsulated between two braces, and composed of key-value pairs. Every document has a unique and mandatory “_id”, a 12 bytes field hexadecimal number. The first 4 bytes represent the current timestamp, the next 3 bytes for the machine id, next 2 bytes for the process id (mongod) and the 3 remaining are an incremental value. This document is very interesting, aswe have a second document under the main document, which is an embedded document (there is no “_id”). We are going to see how to model your data in MongoDB and explain which are the differences between embedded and linked documents in the next blog. All documents are grouped into collections.
Terminology is important, especially to have a broader understanding of the system. Below you find a small comparison between the MongoDB and RDBMS technologies:
MongoDB |
RDBMS |
| Collection | Table |
| Document | Row |
| Field | Column |
| Default _id field | Primary key |
| Embedded documents or linked documents | Joins |
In conclusion, it appears that the advantages of using MongoDB over RDBMS are multiple. To me, the design of the database schema is the most important point. With the rise of agile software development and continuous integration, the structures and data types have evolved, to the point of not being in agreement with the basic principles of relational databases. The responsibility of the data schema comes now to the software developer and not to the database management system. Compared to RDBMS classic pattern, this new storage mode allows developers to have more flexibility when it comes to evolve data schemas over time.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)