Let’s start this new week by going back to a discussion with one of my customers a couple of days ago about moving several tables into different filegroups. Let’s say that some of them contained LOB data. Let’s add to the game another customer requirement: moving all of them ONLINE to avoid impacting the data availability during the migration process. The concerned tables had schema constraints as primary key and foreign keys and non-clustered indexes as well. So a pretty common schema we may deal with daily at customer shops.
Firstly, let’s say that the first topic of the discussion didn’t focus on moving non-clustered indexes on a different filegroup (pretty well-known from my customer) but on how to manage moving constraints online without integrity issues. The main reason of that came from different pointers found by my customer on the internet where we have to first drop such constraints and then to recreate them (by using TO MOVE clause) and that’s whay he was not very confident to move such constraints without introducing integrity issues.
Let’s illustrate this scenario with the following demonstration. I will use a dbo.TransactionHistory2 table that I want to move ONLINE from the primary to the FG1 filegroup. There is a primary key constraint on the TransactionID column as well as foreign key on the ProductID column that refers to dbo.bigProduct table and the ProductID column.
EXEC sp_helpconstraint 'dbo.bigTransactionHistory2';

Here a picture of indexes existing on the dbo.bigTransactionHistory2 table:
EXEC sp_helpindex 'dbo.bigTransactionHistory2';

Let’s say that the pk_big_TranactionHistory_TransactionID unique clustered index is tied to the primary key constraint.
Let’s start by using the first approach based on the WITH MOVE clause .
ALTER TABLE dbo.bigTransactionHistory2 DROP CONSTRAINT pk_bigTransactionHistory_TransactionID WITH (MOVE TO FG1, ONLINE = ON); --> No constraint to avoid duplicates ALTER TABLE dbo.bigTransactionHistory2 ADD CONSTRAINT pk_bigTransactionHistory_TransactionID PRIMARY KEY(TransactionDate, TransactionID) WITH (ONLINE = ON);
By looking further at the script performed we may quickly figure out that this approach may lead to introduce duplicate entries between the drop constraint step and the move table on the FG1 filegroup and create constraint step.
We might address this issue by encapsulating the above command within a transaction. But obviously this method has cost: we have good chance to create a long blocking scenario – depending on the amount of data – and leading temporary to data unavailability. The second drawback concerns the performance. Indeed, we first drop the primary key constraint meaning we are dropping the underlying clustered index structure in the background. Going this way implies to rebuild also related non-clustered indexes to update the leaf level with row ids and to rebuild them again when re-adding the primary key constraint in the second step.
From my point of view there is a better way to go through if we want all the steps to be performed efficiently and ONLINE including the guarantee that constraints will continue to ensure checks during all the moving process.
Firstly, let’s move the primary key by using a one-step command. The same applies to the UNIQUE constraints. In fact, moving such constraint requires only to rebuild the corresponding index with the parameters DROP_EXISTING and ONLINE parameters to preserve the constraint functionality. In this case, my non-clustered indexes are not touched by the operation because we don’t have to update the leaf level as the previous method.
CREATE UNIQUE CLUSTERED INDEX pk_bigTransactionHistory_TransactionID ON dbo.bigTransactionHistory2 ( [TransactionDate] ASC, [TransactionID] ASC ) WITH (ONLINE = ON, DROP_EXISTING = ON) ON [FG1];
In addition, the good news is if we try to introduce a duplicate key while the index is rebuilding on the FG1 filegroup we will face the following error as expected:
Msg 2627, Level 14, State 1, Line 3
Violation of PRIMARY KEY constraint ‘pk_bigTransactionHistory_TransactionID’.
Cannot insert duplicate key in object ‘dbo.bigTransactionHistory2’. The duplicate key value is (Jan 1 2005 12:00AM, 1).
So now we may safely move the additional structures represented by the non-clustered index. We just have to execute the following command to move ONLINE the corresponding physical structure:
CREATE INDEX [idx_bigTransactionHistory2_ProductID] ON dbo.bigTransactionHistory2 ( ProductID ) WITH (DROP_EXISTING = ON, ONLINE = ON) ON [FG1]
Le’ts continue with the second scenario that consisted in moving a table ONLINE on a different filegroup with LOB data. Moving such data may be more complex as we may expect. The good news is SQL Server 2012 has introduced ONLINE operation capabilities and my customer run on SQL Server 2014.
For the demonstration let’s going back to the previous demo and let’s introduce a new [other infos] column with VARCHAR(MAX) data. Here the new definition of the dbo.bigTransactionHistory2 table:
CREATE TABLE [dbo].[bigTransactionHistory2]( [TransactionID] [bigint] NOT NULL, [ProductID] [int] NOT NULL, [TransactionDate] [datetime] NOT NULL, [Quantity] [int] NULL, [ActualCost] [money] NULL, [other infos] [varchar](max) NULL, CONSTRAINT [pk_bigTransactionHistory_TransactionID] PRIMARY KEY CLUSTERED ( [TransactionID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY], ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO
Let’s take a look at the table’s underlying structure:
SELECT
OBJECT_NAME(p.object_id) AS table_name,
p.index_id,
p.rows,
au.type_desc AS alloc_unit_type,
au.used_pages,
fg.name AS fg_name
FROM
sys.partitions as p
JOIN
sys.allocation_units AS au on p.hobt_id = au.container_id
JOIN
sys.filegroups AS fg on fg.data_space_id = au.data_space_id
WHERE
p.object_id = OBJECT_ID('bigTransactionHistory2')
ORDER BY
table_name, index_id, alloc_unit_type

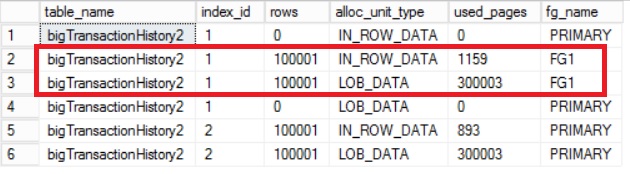
A new LOB_DATA allocation unit type is there and indicates the table contains LOB data for all the index structures. At this stage, we may think that going to the previous way to move online the unique clustered index is sufficient but it is not according the output below:
CREATE UNIQUE CLUSTERED INDEX pk_bigTransactionHistory_TransactionID ON dbo.bigTransactionHistory2 ( [TransactionID] ) WITH (ONLINE = ON, DROP_EXISTING = ON) ON [FG1];

In fact, only data in IN_ROW_DATA allocation units moved from the PRIMARY to FG1 filegroup. In this context, moving LOB data is a non-trivial operation and I had to use a solution based on one proposed here by Kimberly L. Tripp from SQLSkills (definitely one of my favorite sources for tricky scenarios). So partitioning is the way to go. In respect of the solution fom SQLSkills I created a temporary partition function and scheme as shown below:
SELECT MAX([TransactionID]) FROM dbo.bigTransactionHistory2 -- 6910883 GO CREATE PARTITION FUNCTION pf_bigTransaction_history2_temp (BIGINT) AS RANGE RIGHT FOR VALUES (6920000) GO CREATE PARTITION SCHEME ps_bigTransaction_history2_temp AS PARTITION pf_bigTransaction_history2_temp TO ( [FG1], [PRIMARY] ) GO
Applying the scheme to the dbo.bigTransactionHistory2 table will allow us to move all data (IN_ROW_DATA and LOB_DATA) from the PRIMARY to FG1 filegroup as shown below:
CREATE UNIQUE CLUSTERED INDEX pk_bigTransactionHistory_TransactionID ON dbo.bigTransactionHistory2 ( [TransactionID] ASC ) WITH (ONLINE = ON, DROP_EXISTING = ON) ON ps_bigTransaction_history2_temp ([TransactionID])
Looking quickly at the storage configuration confirms this time all data moved to the right FG1.
Let’s finally remove the temporary partitioning configuration from the table (remember that all operations are performed ONLINE)
CREATE UNIQUE CLUSTERED INDEX pk_bigTransactionHistory_TransactionID ON dbo.bigTransactionHistory2 ( [TransactionID] ASC ) WITH (ONLINE = ON, DROP_EXISTING = ON) ON [FG1] -- Remove underlying partition configuration DROP PARTITION SCHEME ps_bigTransaction_history2_temp; DROP PARTITION FUNCTION pf_bigTransaction_history2_temp; GO

Finally, you can apply the same method for all non-clustered indexes that contain LOB data …
Cheers
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)