Sie haben es vielleicht noch nicht gesehen, aber mit den Service Pack 2 von SQL Server 2014 gibt es einen neuen DBCC Befehl: CLONEDATABASE.
„DBCC CLONEDATABASE sollte Kopien eines Schemas und den Statistiken einer Produktionsdatenbank erstellen, um bei Leistungsproblemen Abfragen zu untersuchen.“ MSDN Quelle finden wir hier.
Dieser Befehl kann nur Benutzedatenbanken klonen.
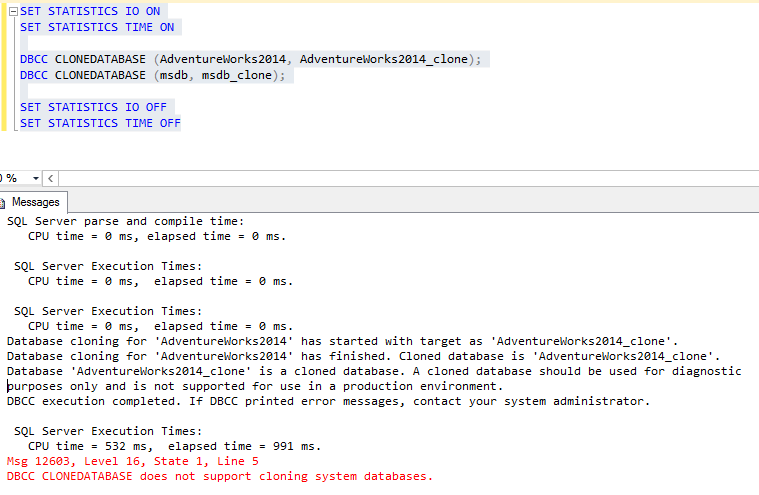
Wie Sie sehen, für die Systemdatenbanken ist es nicht möglich, denn es treten Fehlermeldungen auf:
Msg 12603, Level 16, State 1, Line 5
DBCC CLONEDATABASE does not support cloning system databases.
Mit DBCC CLONEDATABASE wird eine neue Datenbank erstellet. Es ist ein interner Snapshot der die Systemmetadaten, alle Schemas und alle Statistiken für alle Indizes kopiert. Deswegen, ist die Datenbank leer und ist im Read-Only Modus.
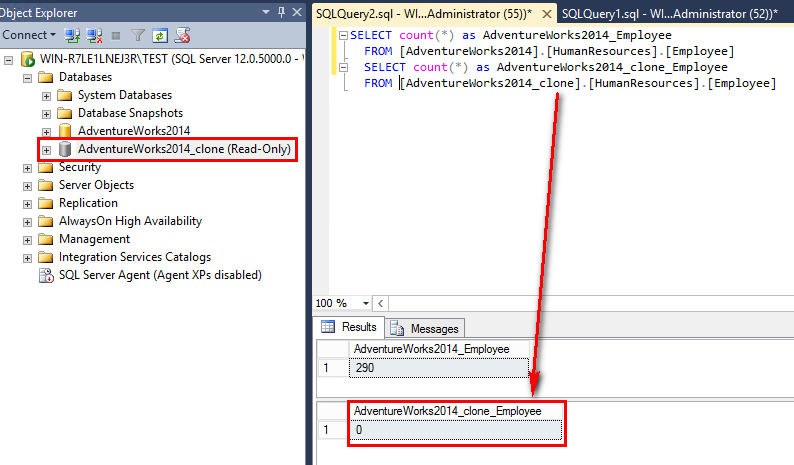
Die Schemas sind kopiert… Ok, ich werde jetzt mit SQL Server Data Tools (SSDT) ein «Schemavergleich» durchführen:
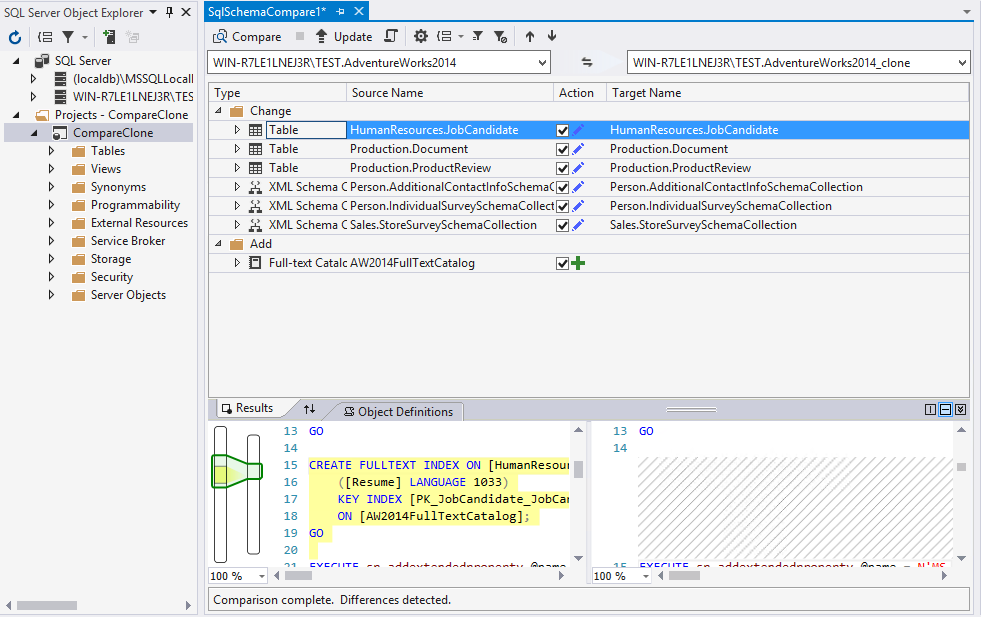
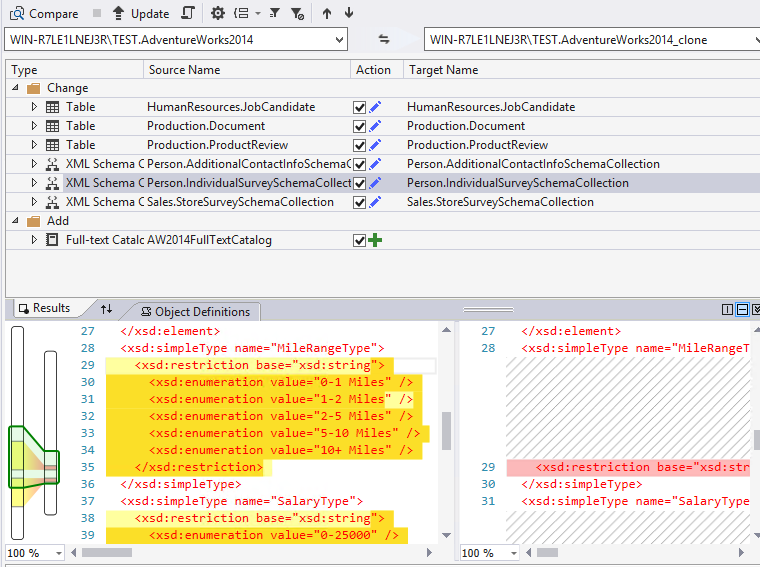
Alle Schemas sind in der geklonten Databank. Die Änderungen sind für den Fulltext und die Daten im XML Schema, wie zum Beispiel der MileRangeType mit seiner Bedeutung.
Ich habe mit meinem Freund Michel über diese Funktionalität gesprochen und er hat mir gefragt wie verhaltet es sich mit den Daten?
Mein erster Schritt ist es die Betrachtung der Dateistruktur nach dem Klonen :
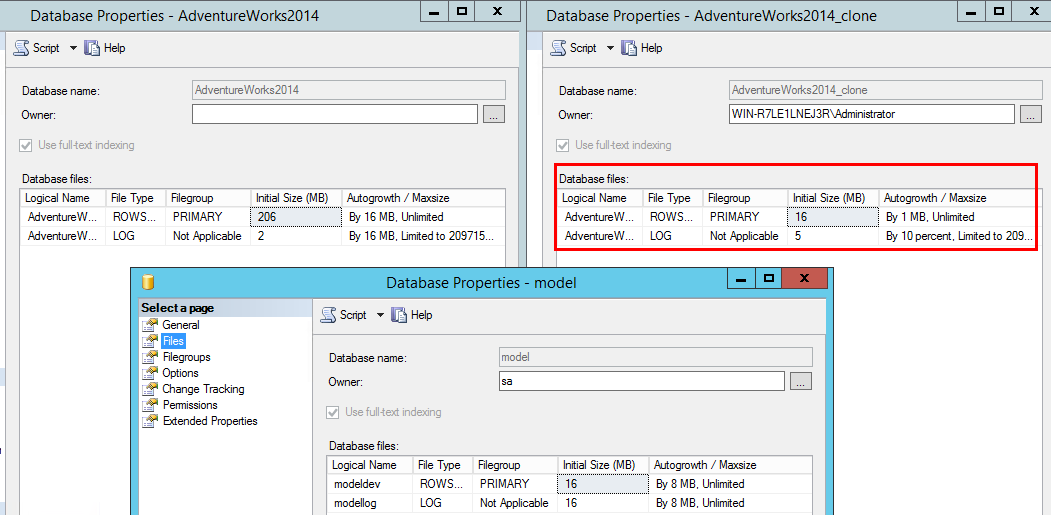
Sie können feststellen, dass meine geklonte Datenbank weder die Benutzerdatenbank noch die Modeldatenbank übernommen hat.
Ich richte eine neue Filegroup [FG_Employees] ein, mit ein neue File AdventureWorks2014_Employees.ndf
Ich ändere mein Clustered Indize PK_Employee_BusinessEntityID zu dieser neuen Filegroup:
USE [master]
GO
ALTER DATABASE [AdventureWorks2014] ADD FILEGROUP [FG_Employees]
GO
ALTER DATABASE [AdventureWorks2014]
ADD FILE ( NAME = N'AdventureWorks2014_Employees',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.TEST\MSSQL\DATA\AdventureWorks2014_Employees.ndf'
, SIZE = 16384KB , FILEGROWTH = 8192KB ) TO FILEGROUP [FG_Employees]
GO
USE [AdventureWorks2014];
GO
CREATE UNIQUE CLUSTERED INDEX PK_Employee_BusinessEntityID
ON HumanResources.Employee(BusinessEntityID)
WITH (DROP_EXISTING = ON )
ON [FG_Employees]
Und jetzt, klone ich wieder meine Datenbank:
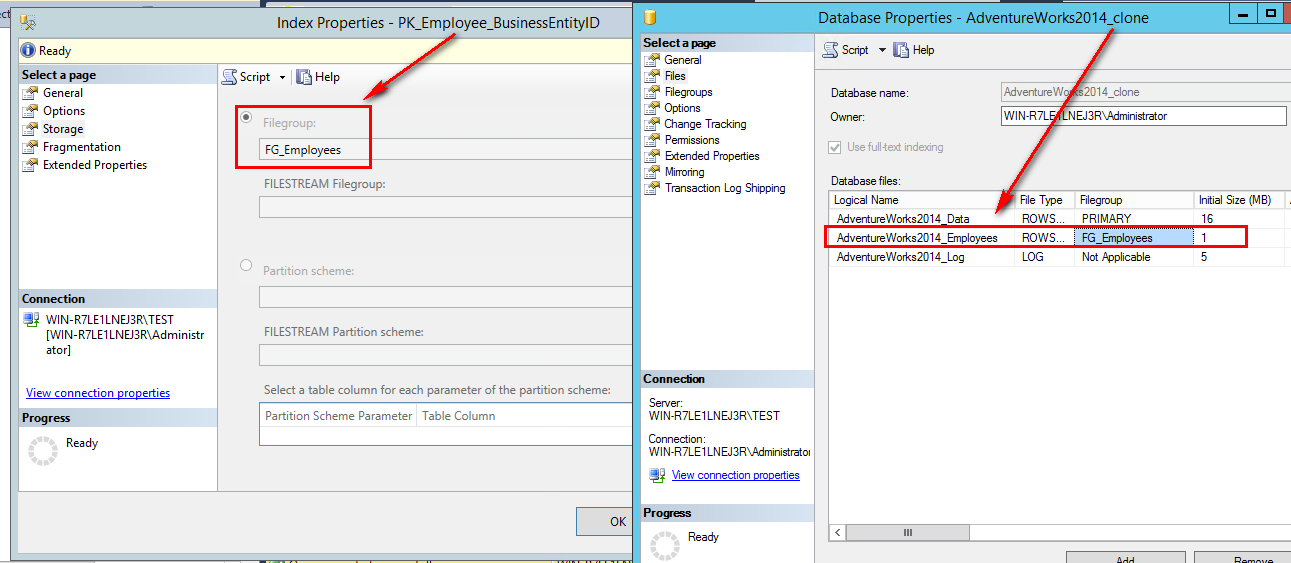
Die Dateistruktur ist kopiert, cool!
Kann ich die Datenbank auf Read-Only ändern und Datei importieren?
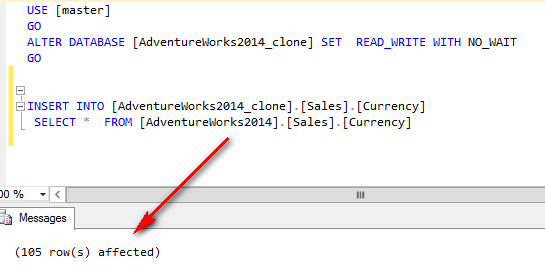
USE [master] GO ALTER DATABASE [AdventureWorks2014_clone] SET READ_WRITE WITH NO_WAIT GO INSERT INTO [AdventureWorks2014_clone].[Sales].[Currency] SELECT * FROM [AdventureWorks2014].[Sales].[Currency]
Kein Problem, die Daten sind direkt kopiert.
Diese neue Funktionalität ist wirklich einfach zu verwenden.
Ich hoffen dass im nächsten Service Pack von SQL Server 2012 und SQL Server 2016 die CLONEDATABASE Funktion auch integriert wird. Für mehr Information, MSDN link hier
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)