By Franck Pachot
.
Next Tuesday in Geneva I’m presenting Oracle In-Memory Column Store to Business Intelligence people at the Swiss BI Day
After defining what is an analytic query, I show the different approaches to optimize that in Oracle, IMCS being the latest one. Here are some details about that slide.
What is an analytic query?
First definition – what it is not?
Analytic queries are the not the OLTP queries that makes the core functions of an ERP for example. The queries that get all columns for a row defined by it primary key are typically what OLTP is doing. It was the case 30 years ago, even before relational databases. And it’s still the case today with all those frameworks generating queries for CRUD functions. Which kind of queries are issued by Hibernate when you don’t take the time to design the ORM mapping? select * from table where pk=…
Those queries were already optimized in very old versions: store the rows in blocks so that all column values come with one i/o call, fit in memory or even in L2 cache. There is nothing new about them.
Second definition – what is special about analytic queries?
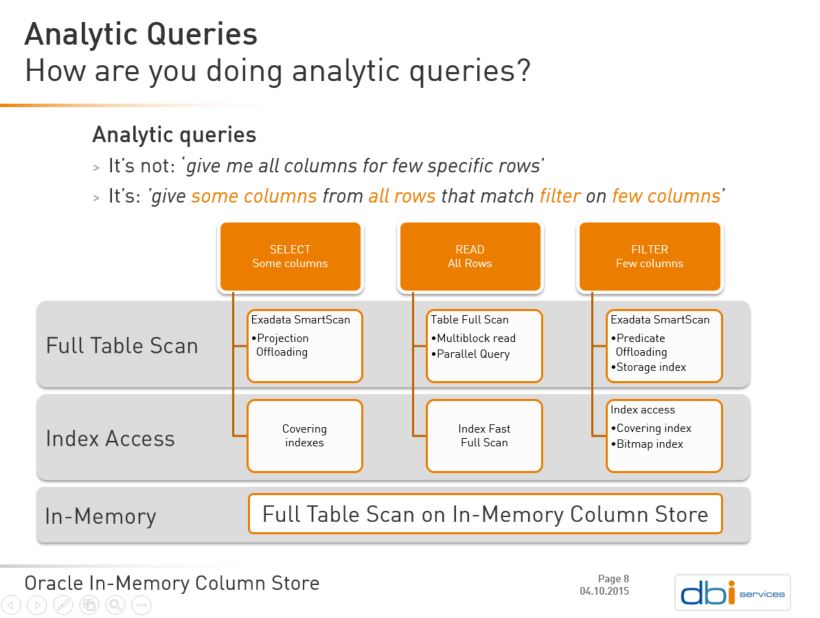
- You need only some columns – not all of them
- You need lot of rows – not only one
- You filter on few columns – the dimensions
Lot of rows and few columns. Of course the row storage is not very good for them: you will retrieve too many columns from rows that are scattered everywhere. Finally you read lot of data that you don’t need.
Columnar storage makes sense here and this is why Oracle designed In-Memory Column Store for it.
But let’s take a look at the other features that can optimize Analytic Queries.
Index access
Index access it rather used by OLTP queries because when you need a lot of rows the access to the table makes it sub-optimal. However there are several choices that can improve index access for analytic queries.
Covering indexes: If you have an index that contains not only the columns that are used to filter but also the columns that are in the ‘select’ part – the projection – then the index access can give good performance even for lot of rows.
Index Fast Full Scan: If the filtering is not selective enough to benefit from range scan, and we need a lot of rows, an Index Fast Full Scan can be optimal. It’s the same mechanism as Full Table Scan (large multiblock i/o) but on a smaller structure that have fewer columns.
Bitmap Indexes: The previous solutions are optimal only when all the columns you filter on are in the index. But you don’t know in advance which combination of columns will be used to filter. And you can’t build optimal indexes for all those combinations. The solution is then bitmap indexes: one on each column and the result can be efficiently combined. Very close to a columnar approach. There are only two drawbacks: you can’t use them in OLTP because there are very bad for row-by-row DML, and the access to the table is still a problem if you need a lot of rows.
Full Table Scan
Because of the ‘lot of rows’ part of the analytic queries, a Full Table Scan can make sense because it reads rows with large i/o calls, direct-path read, parallel query, etc. You don’t have the latency problem of index access (going to the table for each index entry) but you may have a bandwidth problem. When tables are large, with lot of columns, you have to transfer a large amount of data from disk to CPU. And you reach the limits somewhere. A few years ago, to workaround the bottleneck between memory and CPU in Intel processors (at that time) Oracle introduced SmartScan. In Exadata storage cells some column filtering and projection is done upstream. Again, it was a columnar idea: process only the columns you need. And they also introduced columnar compression available on Exadata as well.
In-Memory Column Store
Those optimization techniques have to be designed because they have pros and cons depending on the application behavior (updates and queries). Another way to optimize is to keep the row storage and put it on low latency storage (All Flash Array for example) so that index access is still possible.
But then, when releasing 12.1.0.2, Oracle came with a real columnar solution: In-Memory Columns Store.
With in-Memory option (Enterprise Edition + 50%) you can:
- Activate it without changing hardware (you need lot of memory though…)
- Keep your current design. It even allows analytic queries on the OLTP database
- Get rid of indexes, materialized views, ETL processes, etc. you set up to maintain the BI database
Of course, Enterprise Edition is expensive and it’s another option. But when you think about it, and compare to other options, that one is not so expensive. Try to evaluate the cost to build and maintain a real-time BI database, with specific design optimized for analytic queries and compare with the In-Memory option. If you have enough memory in your servers to keep the most used table (and remember that they are compressed there) then the option can make sense.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/CHC_web-min-min-scaled.jpg)