In this blog post, we will see how to create a Big Data cluster through the Oracle Cloud Services. If you want more details about the Oracle Big Data cloud services offering, you can refer to my previous blog Introduction to Oracle Big Data.
First, you need to create your trial account through the following link: https://cloud.oracle.com/tryit. Note that, when you create your trial account, all information (phone number, address, credit card…), must be from the same country. Otherwise, you will get an error message.
Then you will get an email from Oracle with your connection information. The 4 main connection information are:
- Service URL: https://myservices.us.oraclecloud.com … (Depending on the region you will be affected)
- Identity domaine
- Username (email address)
- Temporal password
During the first connection you need to change your password and answer to 3 secret questions.
You are now login into the Oracle Cloud Services Dashboard. Select the “Big Data – Compute Edition” service to create your cluster.
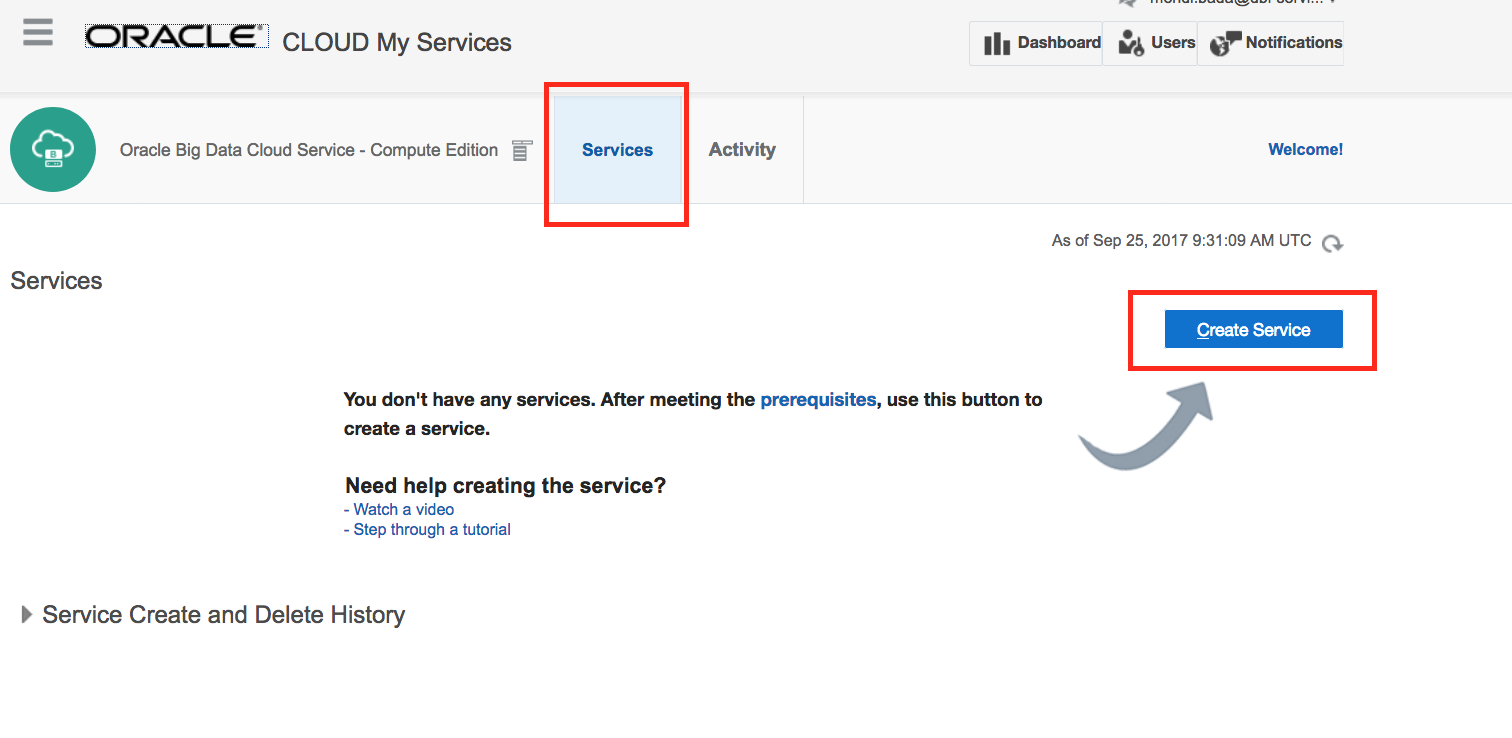
Click on “Service” and “Create Service”.
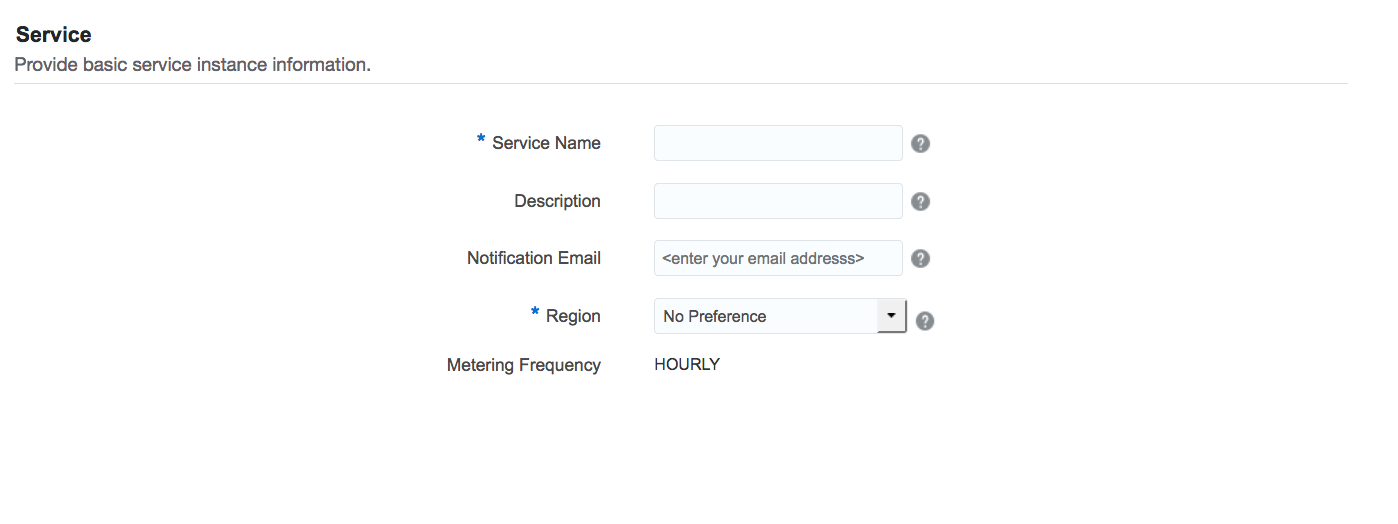
First, complete the service information. Cluster name, description… and click on “Next”.
Then, you enter the details of your Big Data cluster (configuration, credentials, storage…).
Cluster configuration:
Use the “full” deployment. It will provision a cluster with Spark, MapReduce, Zeppelin, Hive, Spark Thrift, Big Data File System.
Credentials:
Generate an ssh public key and insert it (see screenshot below). Update or keep the current Administrative user / password which is very important for the next operations.
Storage:
Oracle Public Cloud is working with Object storage container. Which means that, a storage container can be used by all cloud services. For the Big Data Service you need to use an existing storage container or create one. The storage container name must follow a specific syntax.
https://<identity_domaine>.storage.oraclecloud.com/v1/Storage-<identity_domaine>/<container_name>
Example: https://axxxxxx.storage.oraclecloud.com/v1/Storage-axxxxxx/dbistorage
You can find the complete configuration below.
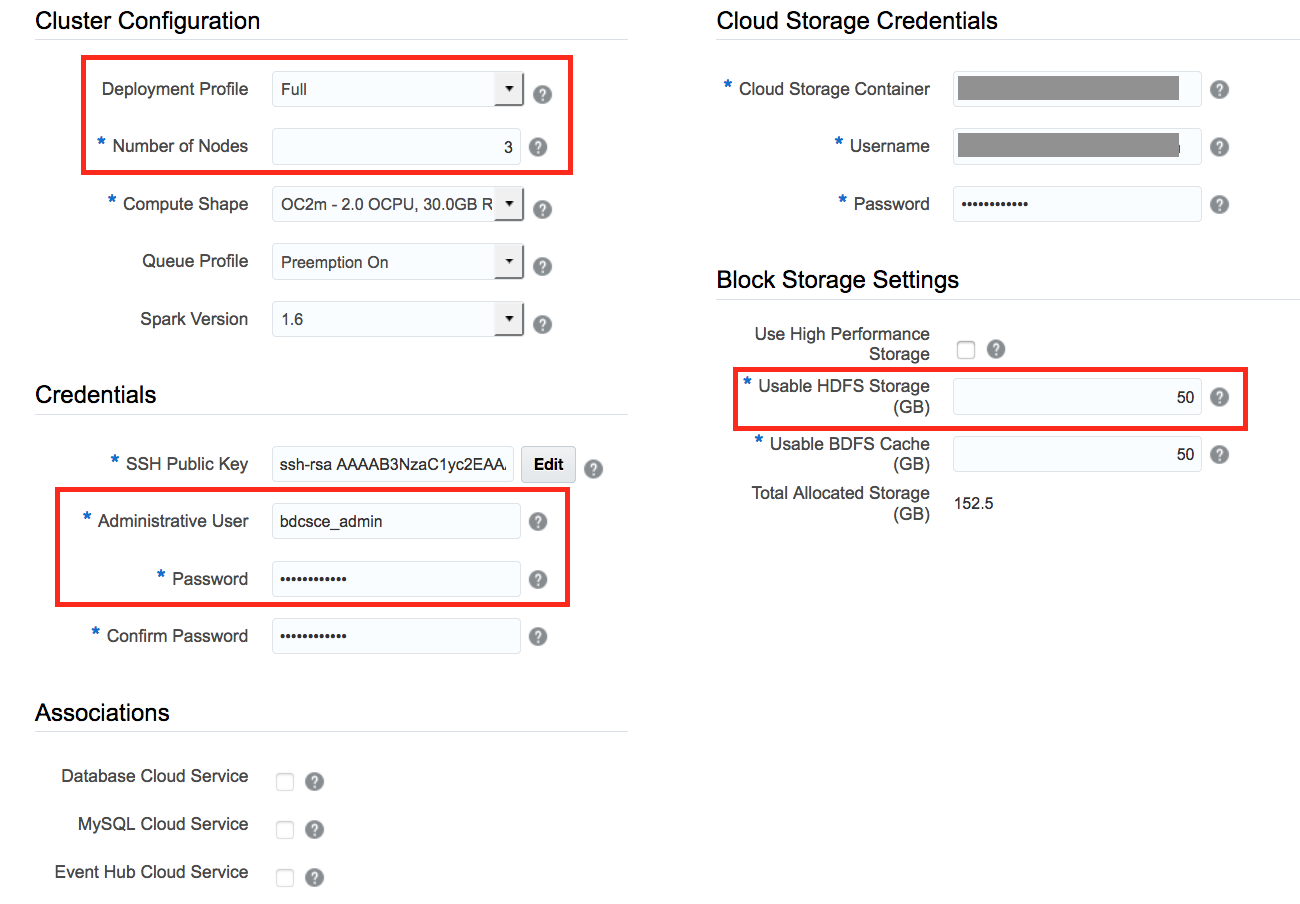
Confirm your cluster configuration and click on “Next”.
During the cluster deployment, you can take the time to read the documentation: https://docs.oracle.com/en/cloud/paas/big-data-cloud/index.html
Once your services has been deployed, you can access to the Big Data Cluster Console, to monitor your cluster and access it.
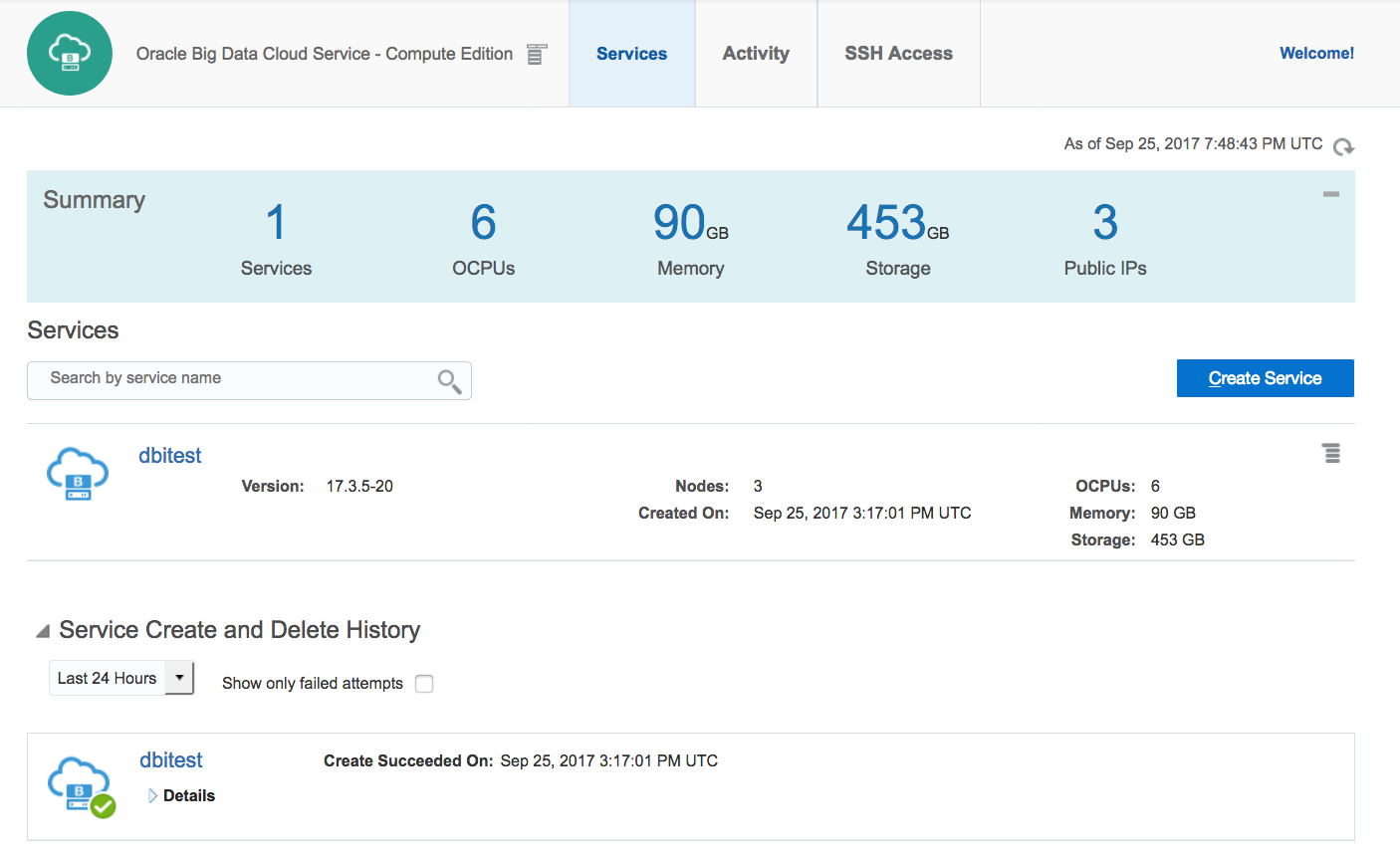
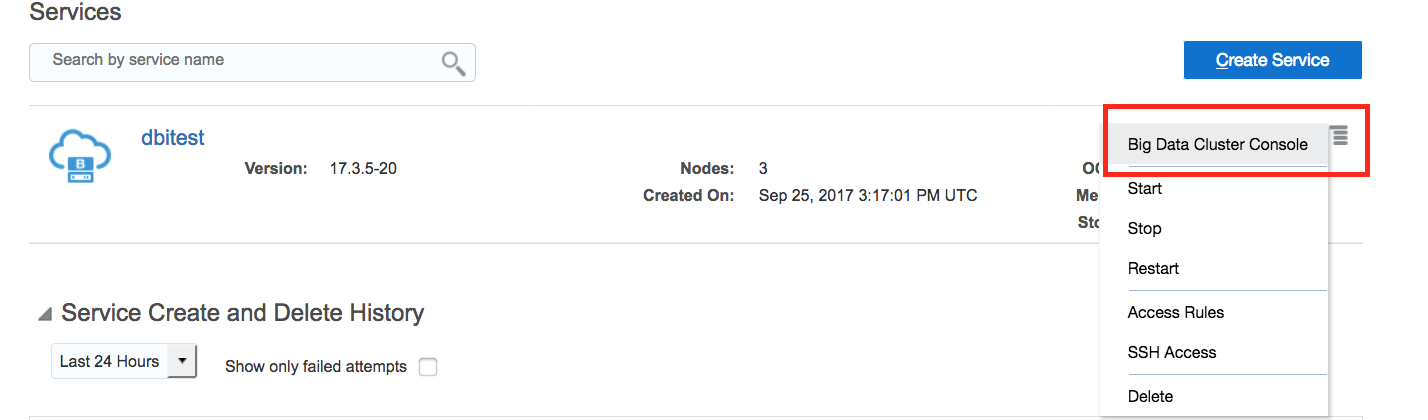
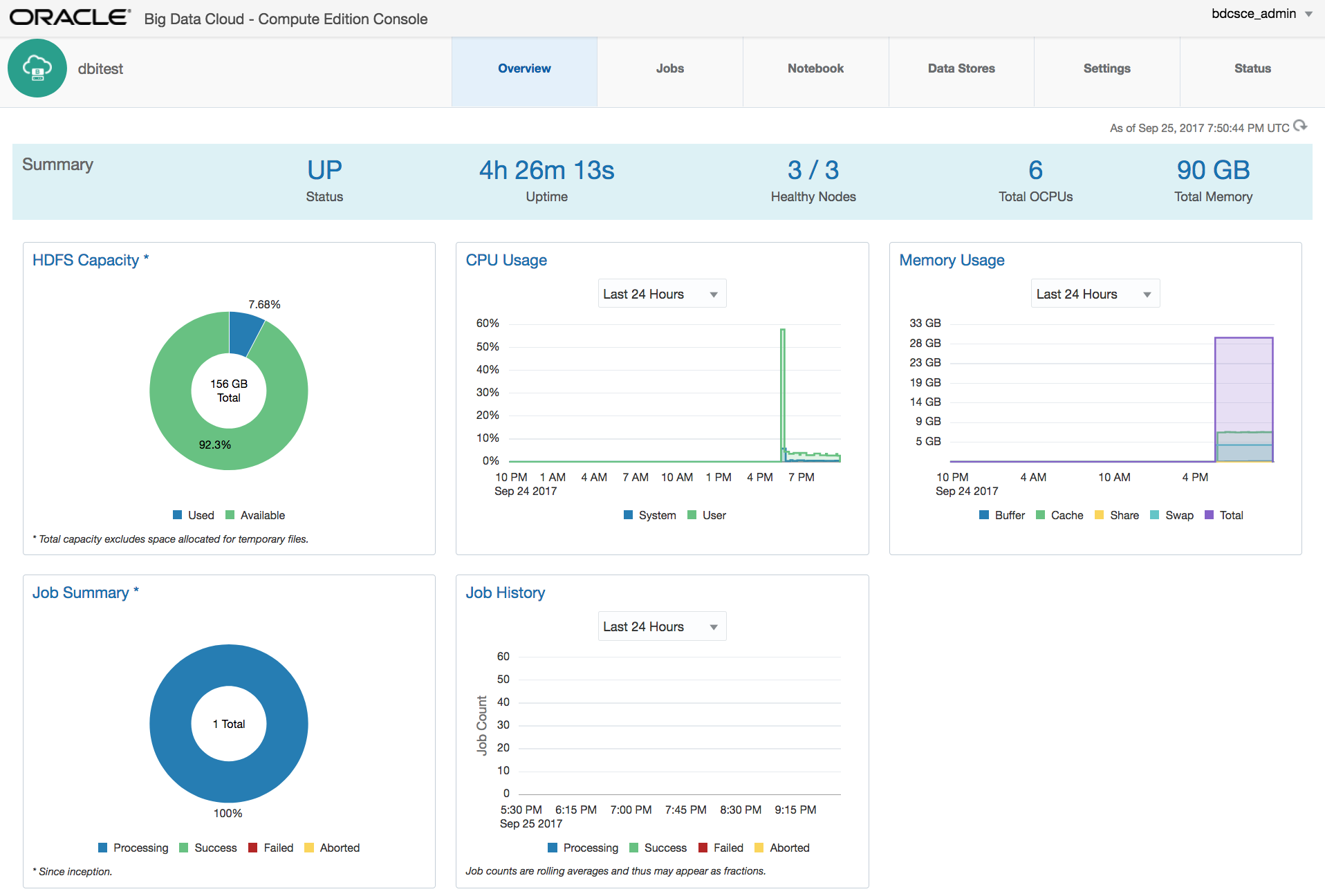
You have now deployed an Big Data cluster composed by 3 nodes, based on HortonWorks distribution with the following tools:
- HDFS = Hadoop Distributed FileSystem
- YARN = Resources management for the cluster
- Hive = Data Warehouse for managing large data sets using SQL
- Spark= Data processing framework
- Pig = High-level platform for creating programs that runs on Hadoop
- ZooKeeper = Hadoop cluster scheduler
- Zeppelin = Data scientist workbench, web based.
- Alluxio = Memory speed virtual distributed storage
- Tez = Framework for YARN-based, Data Processing Applications In Hadoop
Your Oracle Big Data cluster, through Oracle Big Data Cloud Service – Compute Edition is now ready to use.
Enjoy 😉
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ENB_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JDU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ALN_web-min-scaled.jpg)