This blog is about an interesting partitioning story and curious data movements during merge operation. I was at my one of my customer uses intensively partitioning for various reasons including archiving and manageability. A couple of days ago, we decided to test the new fresh developed script, which will carry out the automatic archiving stuff against the concerned database in quality environment.
Let’s describe a little bit the context.
We used a range-based data distribution model. Boundary are number-based and are incremented monolithically with identity values.
We defined a partition function with range right values strategy as follows:
CREATE PARTITION FUNCTION pfOrderID (INT) AS RANGE RIGHT FOR VALUES(@boundary_archive, @boundary_current) go
The first implementation of the partition scheme consisted in storing all partitioned data inside the same filegroup.
CREATE PARTITION SCHEME psOrderID AS PARTITION pfOrderID ALL TO ([PRIMARY]) go
Well, the initial configuration was as follows. We applied page compression to the archive partition because it contained cold data which is not supposed to be updated very frequently.


As you may expect, the next step will consist in merging ARCHIVE and CURRENT partitions by using the MERGE command as follows:
ALTER PARTITION FUNCTION pfOrderID() MERGE RANGE (@b_archive);
Basically, we achieve a merge operation according to Microsoft documentation:
The filegroup that originally held boundary_value is removed from the partition scheme unless it is used by a remaining partition, or is marked with the NEXT USED property.

At this point we may expect SQL Server has moved data from the middle partition to the left partition and according to this other Microsoft pointer
When two partitions are merged, the resultant partition inherits the data compression attribute of the destination partition.
But the results come as a little surprise because I expected to see a page compression value from my archive partition.

At this point, my assumption was either compression value doesn’t inherit correctly as mentioned in the Microsoft documentation or data movement is not performed as expected. The latter may be checked very quickly by looking at the corresponding records inside the transaction log file.
SELECT
[AllocUnitName],
Operation,
COUNT(*) as nb_ops
FROM ::fn_dblog(NULL,NULL)
WHERE [Transaction ID] = (
SELECT TOP 1 [Transaction ID]
FROM ::fn_dblog(NULL,NULL)
WHERE [Xact ID] = 164670)
GROUP BY [AllocUnitName], Operation
ORDER BY nb_ops DESC
GO
I put only the relevant sample here
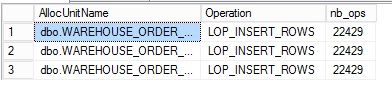
Referring to what I saw above, I noticed data movement was not performed as expected but rather as shown below:

So, this strange behavior seems to explain why compression state switched from PAGE to NONE in my case. Another strange thing is when we changed the partition scheme to include an archive filegroup, we returned to normality.
CREATE PARTITION SCHEME psOrderID AS PARTITION pfOrderID TO ([ARCHIVE], [PRIMARY], [PRIMARY]) go
I doubled checked the Microsoft documentation to see if it exists one section to figure out the behavior I experienced in this case but without success. After further investigations I found out an interesting blog post from Sunil Agarwal (Microsoft) about partition merging and some performance improvements shipped with SQL Server 2008 R2. In short, I was in the specific context described in the blog post (same filegroup) and merging optimization came into action transparently because number of rows in the archive partition was lower than the one in the current partition at the moment of the MERGE operation.
Let me introduce another relevant information – the number of lines for each partition – to the following picture:
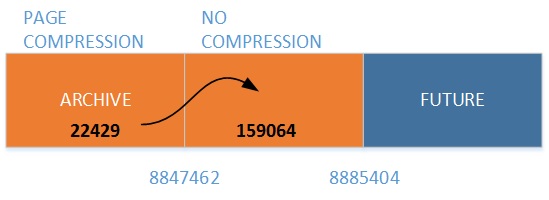
Just to be clear, this is an interesting and smart mechanism provided by Microsoft but it may be a little bit confusing when you’re not aware of this optimization. In my case, we finally decided with my customer to dedicate an archiving partition to store cold data that will be rarely accessed in this context and keep up the possibility to store cold data on cheaper storage when archiving partition will grow to a critical size. But in other cases, if storing data is the same filegroup is a still relevant scenario, keep in mind this optimization to not experience unexpected behaviors.
Happy partitioning!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)