This is our first time with Stéphane Haby at this amazing SQLServer community event. At 7:30 am, we were already in the conference center at the registration desk. They gave us a funny badge 🙂
So, after breakfast time, we went to the keynote session.
 |
 |
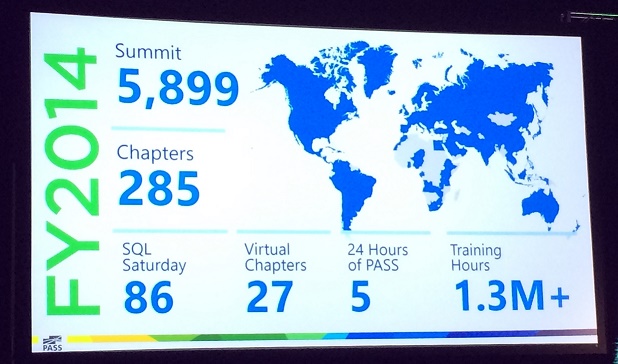
During this session we listened to a speech of SQL Pass President Thomas Larock. The SQLPass community is growing over time. The following picture gives you a good idea of the importance of this community this year:
Then, it was the turn of Microsoft to lay out their vision of the future data market. I won’t hide from you that Microsoft will focus on Microsoft Azure, which will be a main component of the Microsoft data platform.
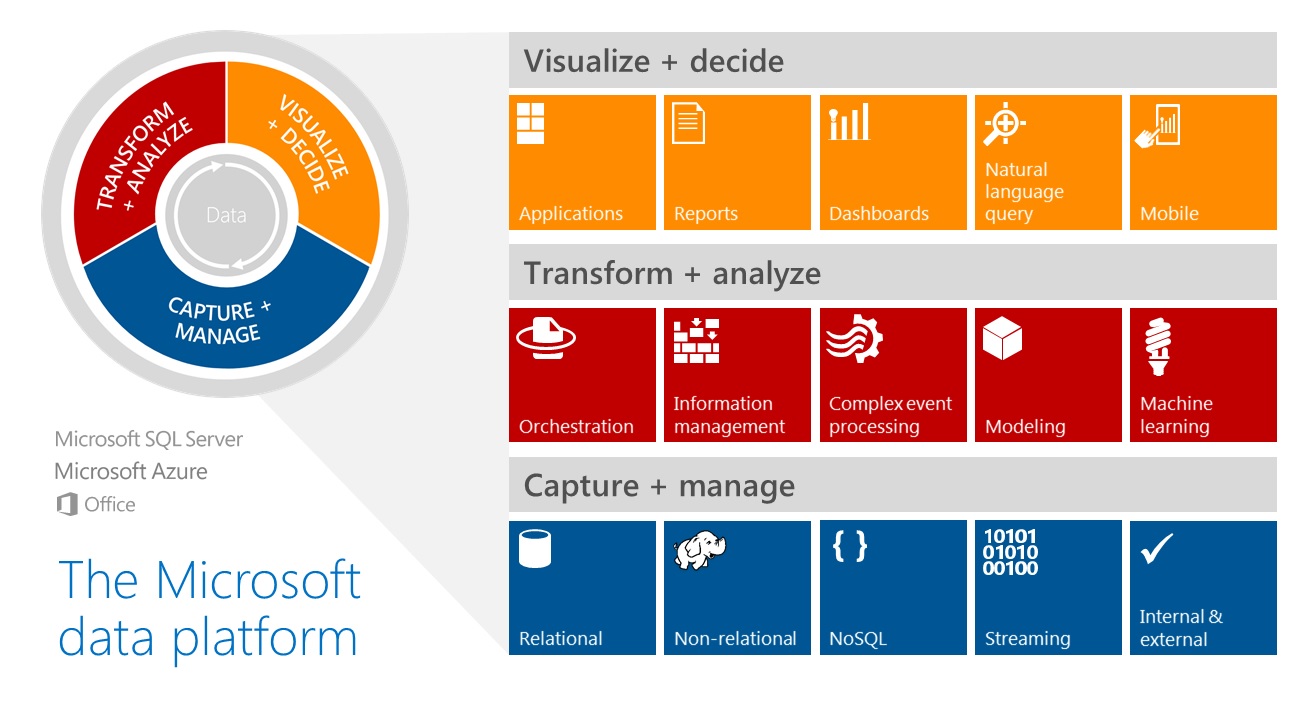
We had a presentation of different services like Azure DocumentDB (NoSQL), Azure HDInsight (with Hadoop), Polybase (bringing the relational world and Hadoop together), Azure search (search as a service in Azure) and the PowerBI stack. So, among all this, what are the news about the SQL Server engine? Microsoft has announced some interesting features like stretch databases and the possibility to add nonclustered columnstore indexes to in-memory tables. The former consists of extending on-premise databases to Azure DBs by storing hot business data on-premise and cold or close business data to Azure DBs. The latter will provide the ability to run analytics queries concurrently with OLTP workload in the same database.
This keynote was a good reminder of the importance of the cloud capabilities and the hybrid perspective in future database architectures. Personally, I don’t think that we can still reject it, but maybe I have to get a good prediction from Azure machine learning 🙂
See you soon for the next sessions!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)