
A couple of weeks ago, I worked for a customer that wanted to implement SQL Server 2012 (and not SQL Server 214) AlwaysOn with availability groups. During our tests we performed a bunch of failover tests and the customer tried to perform a failover of one of the installed availability group by using the failover cluster manager (FCM). Of course, I told him this is not best practice because the failover cluster manager is not aware of the synchronization state of the availability group. But with SQL Server 2014, the story has changed because I noticed a different behavior. I would like to share this information with you in this posting.
But let me first demonstrate the SQL Server 2012 behavior with the following example:
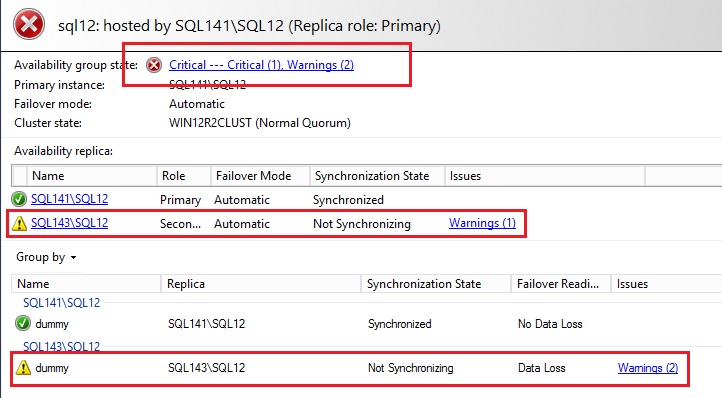
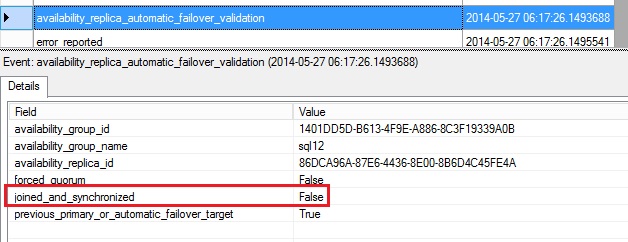
I have an availability group named SQL12 configured with 2 synchronous replicas and automatic failover. However, as you can see, the synchronization state of my availability database is not healthy as shown below:

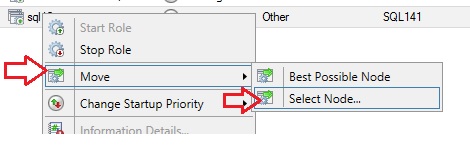
Now, if I try to failover my availability group using the failover cluster manager …


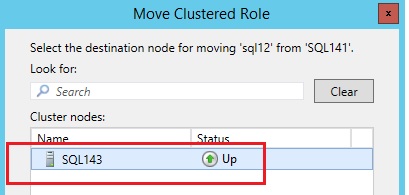
…. the next available node is SQL143 …


… and we can notice the failover did not occur as expected because the SQL12 resource is still on the SQL141 node as shown in the following picture:

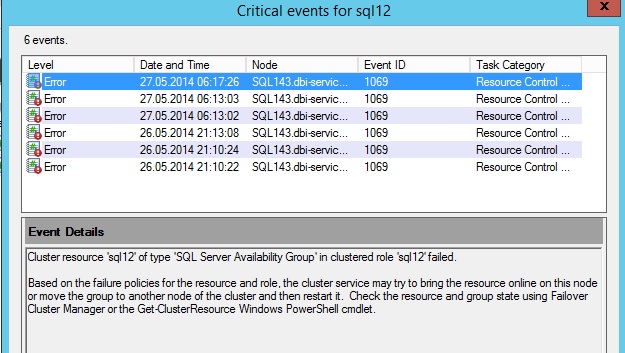
Having a look at the cluster error log does not help us in this case because we have a classic 1069 error number without helpful information:

Generating detailed cluster error logs could help us but I prefer to directly look at the SQL Server side for the moment. The AlwaysOn_health extended event is a good start to check for some existing records associated to the problem.

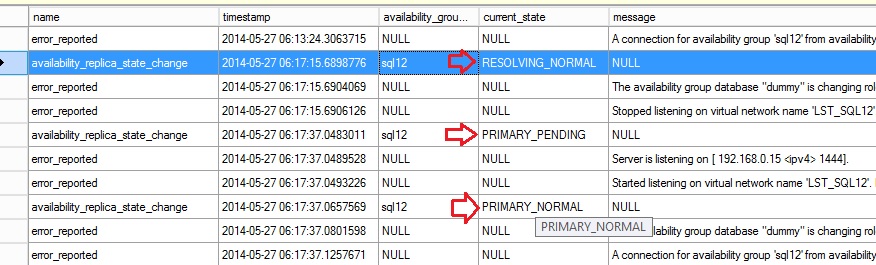
We have indeed some information about the failover attempt. First the SQL141SQL12 replica state changed from PRIMARY_NORMAL to RESOLVING_NORMAL due to the manual failover issued by the FCM.

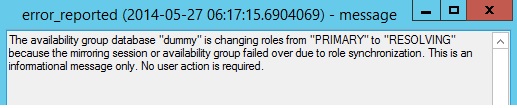
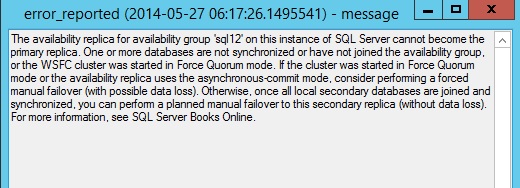
Then we can see an error message that explains that the dummy database is changing its role from PRIMARY to RESOLVING because there is a problem with a role synchronization. This error is issued by the forced failover of the availability group resource that I used.

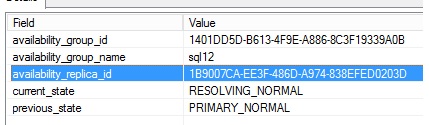
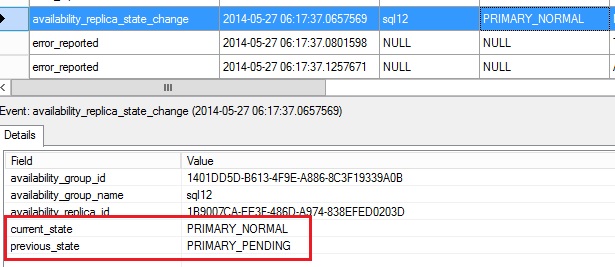
Finally, we notice the failover process did not complete succesfully and the dummy database failbacks on the SQL141SQL12 replica (availability_replica_id 1B9007CA-EE3F-486D-A974-838EFED0203D associated to the SQL141SQL12 replica in my case)

On the other side, the SQL143SQL12 secondary replica also features a lot of useful information:


To summarize, this test demonstrates clearly that the FCM is not aware of the availability databases synchronization state inside an availability group. Using FCM may result in unintended outcomes, including unexpected downtime!
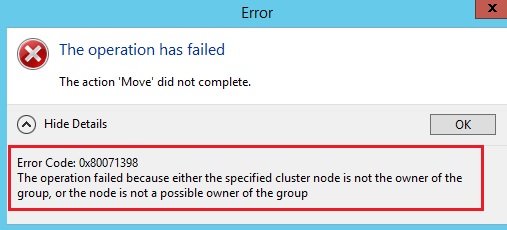
Now, it’s time to test the same scenario with SQL Server 2014 and a configured availability group. During the failover attempt, I get the following error message:


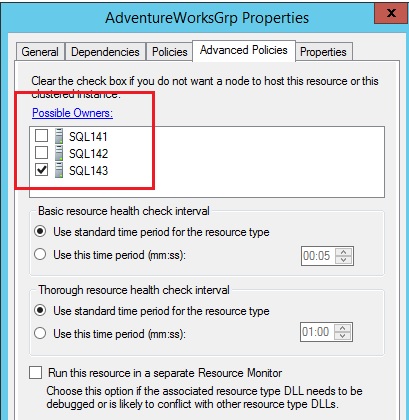
If we take a look at the possible owners of the corresponding availability group resource, we can see that the current cluster node that hosts the availability group is the only possible owner – unlike SQL Server 2012.

As a reminder, possible and preferred owners are resetted during the availability group creation and failover based on the primary replica and its secondaries. For fun, I decided to compare the two processes issued by the both versions of SQL Server and availability groups (SQL Server 2012 and SQL Server 2014) after having triggered an availability group failover and generating the associated cluster logs:
Get-ClusterLog -UseLocalTime -Span 5
Result with SQL Server 2012
000005d4.00000778::2014/05/26-22:10:55.088 INFO [RCM] rcm::RcmApi::AddPossibleOwner: (sql12, 1)
000005d4.00000778::2014/05/26-22:10:55.088 INFO [GUM] Node 1: executing request locally, gumId:215, my action: /rcm/gum/AddPossibleOwner, # of updates: 1
000005d4.00000778::2014/05/26-22:10:55.088 INFO [RCM] rcm::RcmGum::AddPossibleOwner(sql12,1)
000005d4.00000778::2014/05/26-22:10:55.103 ERR mscs::GumAgent::ExecuteHandlerLocally: (5010)’ because of ‘The specified node is already a possible owner.’
000005d4.00000778::2014/05/26-22:10:55.103 WARN [DM] Aborting group transaction 29:29:613+1
000005d4.00000778::2014/05/26-22:10:55.103 ERR [RCM] rcm::RcmApi::AddPossibleOwner: (5010)’ because of ‘Gum handler completed as failed’
000005d4.00000778::2014/05/26-22:10:55.103 WARN [RCM] sql12 cannot be hosted on node 3
000005d4.00000778::2014/05/26-22:10:55.103 WARN [RCM] Possible owners:
000005d4.00000778::2014/05/26-22:10:55.103 WARN 2
000005d4.00000778::2014/05/26-22:10:55.103 WARN 1
000005d4.00000778::2014/05/26-22:10:55.103 WARN
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] rcm::RcmApi::RemovePossibleOwner: (sql12, 2)
000005d4.00000778::2014/05/26-22:10:55.103 INFO [GUM] Node 1: executing request locally, gumId:215, my action: /rcm/gum/RemovePossibleOwner, # of updates: 1
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] rcm::RcmGum::RemovePossibleOwner(sql12,2)
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] Removing node 2 from resource ‘sql12’.
000005d4.00000778::2014/05/26-22:10:55.103 INFO [GEM] Node 1: Sending 1 messages as a batched GEM message
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] rcm::RcmApi::AddPossibleOwner: (sql12, 2)
000005d4.00000778::2014/05/26-22:10:55.103 INFO [GUM] Node 1: executing request locally, gumId:216, my action: /rcm/gum/AddPossibleOwner, # of updates: 1
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] rcm::RcmGum::AddPossibleOwner(sql12,2)
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] Adding node 2 to resource ‘sql12’.
000005d4.00000778::2014/05/26-22:10:55.103 INFO [GEM] Node 1: Sending 1 messages as a batched GEM message
000005d4.00000778::2014/05/26-22:10:55.103 INFO [GUM] Node 1: executing request locally, gumId:217, my action: /rcm/gum/SetGroupPreferredOwners, # of updates: 1
000005d4.00000778::2014/05/26-22:10:55.103 INFO [RCM] rcm::RcmGum::SetGroupPreferredOwners(sql12,
000005d4.00000778::2014/05/26-22:10:55.103 INFO 1
000005d4.00000778::2014/05/26-22:10:55.103 INFO 2
000005d4.00000778::2014/05/26-22:10:55.103 INFO
Result with SQL Server 2014
000005d4.00000bb0::2014/05/26-22:14:54.578 INFO [RCM] rcm::RcmApi::AddPossibleOwner: (AdventureWorksGrp, 1)
000005d4.00000bb0::2014/05/26-22:14:54.578 INFO [GUM] Node 1: executing request locally, gumId:230, my action: /rcm/gum/AddPossibleOwner, # of updates: 1
000005d4.00000bb0::2014/05/26-22:14:54.578 INFO [RCM] rcm::RcmGum::AddPossibleOwner(AdventureWorksGrp,1)
000005d4.00000bb0::2014/05/26-22:14:54.578 ERR mscs::GumAgent::ExecuteHandlerLocally: (5010)’ because of ‘The specified node is already a possible owner.’
000005d4.00000bb0::2014/05/26-22:14:54.578 WARN [DM] Aborting group transaction 29:29:627+1
000005d4.00000bb0::2014/05/26-22:14:54.578 ERR [RCM] rcm::RcmApi::AddPossibleOwner: (5010)’ because of ‘Gum handler completed as failed’
000005d4.00000bb0::2014/05/26-22:14:54.578 WARN [RCM] AdventureWorksGrp cannot be hosted on node 3
000005d4.00000bb0::2014/05/26-22:14:54.578 WARN [RCM] Possible owners:
000005d4.00000bb0::2014/05/26-22:14:54.578 WARN 2
000005d4.00000bb0::2014/05/26-22:14:54.578 WARN 1
000005d4.00000bb0::2014/05/26-22:14:54.578 WARN
000005d4.00000c34::2014/05/26-22:14:54.578 INFO [RCM] rcm::RcmApi::RemovePossibleOwner: (AdventureWorksGrp, 2)
000005d4.00000c34::2014/05/26-22:14:54.578 INFO [GUM] Node 1: executing request locally, gumId:230, my action: /rcm/gum/RemovePossibleOwner, # of updates: 1
000005d4.00000c34::2014/05/26-22:14:54.578 INFO [RCM] rcm::RcmGum::RemovePossibleOwner(AdventureWorksGrp,2)
000005d4.00000c34::2014/05/26-22:14:54.578 INFO [RCM] Removing node 2 from resource ‘AdventureWorksGrp’.
000005d4.00000c34::2014/05/26-22:14:54.578 INFO [GEM] Node 1: Sending 1 messages as a batched GEM message
000005d4.000011f4::2014/05/26-22:14:54.578 INFO [GUM] Node 1: executing request locally, gumId:231, my action: /rcm/gum/SetGroupPreferredOwners, # of updates: 1
000005d4.000011f4::2014/05/26-22:14:54.578 INFO [RCM] rcm::RcmGum::SetGroupPreferredOwners(AdventureWorksGrp,
000005d4.000011f4::2014/05/26-22:14:54.578 INFO 1
000005d4.000011f4::2014/05/26-22:14:54.578 INFO
As I said earlier, possible and preferred owners properties are managed automatically by SQL Server AlwaysOn. We can see here this is done by the cluster resource control manager and the following functions:
rcm::RcmApi::AddPossibleOwner(), rcm::RcmApi::RemovePossibleOwner() and rcm::RcmApi::SetGroupPreferredOwners () .
You can notice that two nodes are added as possible owners with SQL Server 12. However, with SQL Server 2014 only one node is added as possible owner of the concerned availability group resource. Interesting change isn’t it?
By David Barbarin
Post Views: 1,859



![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JDU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JOC_web-scaled.jpg)