
Let’s continue with this study of the new availability group enhancements. Others studies are available here:
This time we’ll talk about the possibility to enrol a third replica for automatic failover. It implies of course to configure synchronous replication between the 2 pairs of replicas and this is at the cost of degrading the overall performance. But it seems that in this area we can expect to have also some improvements. So maybe another future study.
First of all, my feeling is that this enhancement will be very interesting in terms of availability but unfortunately introducing a third replica in this case will not be affordable for some customers in terms of budget. So, the final package is surely not yet defined and this would lead me to draw conclusions based on inaccurate information. So let’s focus only on the technical aspect of this feature for the moment:
I have included a third replica (SQL163) to my existing availability group 2016Grp:

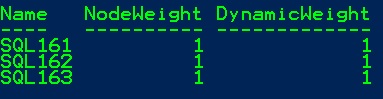
In parallel, my cluster quorum is configured as follows:
…
![]()
…
![]()
Basically, this is a windows failover cluster CLUST-2021 on a single subnet that includes three nodes (SQL161,SQL162 and SQL163) and configured to use a file share witness as well as dynamic quorum capability.
I simulated a lot of test failures in my lab environment (shutdown of a replica, turn off of a replica, lost a database file, disable the network cards and so on) and the automatic failover on 2 pairs of replicas was successful in each case. However, this raised the following question: which secondary replica will be chosen by the system? I didn’t see a configuration setting that controls the “failover priority order list” and I believe it could be a good adding value here. After performing others tests and after discussing with some other MVPS like Christophe Laporte (@Conseilit), I noticed that the failover order seems to be related to the order of the preferred owner of the related availability group cluster role. Moreover, according to this very interesting article from Vijay Rodrigues, this order is set and changed dynamically by SQL Server itself, so changing the order directly from the cluster itself seems to be a very bad idea. Next, I decided to configure directly the order at the creation step of the availability during the adding operation of the replicas and it seems to be the good solution.
To illustrate this point here the initial configuration I wanted to achieve:
- SQL161 primary replica
- SQL163 secondary replica (first failover partner)
- SQL162 secondary replica (second failover partner)
After adding this replica in the correct order from the wizard here the inherited order I get from the related cluster role:
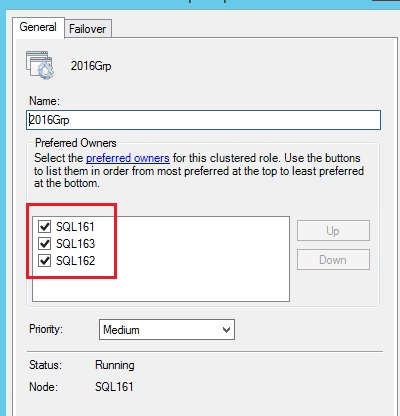
This order seems to be preserved according to the current context of the availability group.
The same test with a different order like:
- SQL163 primary replica
- SQL162 secondary replica (first failover partner)
- SQL161 secondary replica (second failover partner)
… Givesus a different result and once again this order is preserved regardless the context changes:
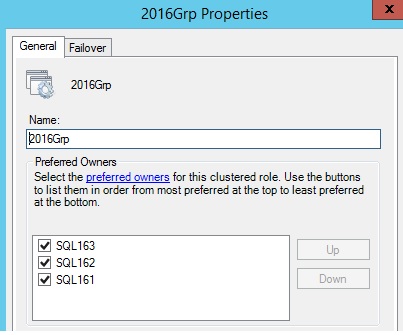
This idea of controlling the failover replicas order comes from a specific scenario where you may have two secondary replicas across multiple sites. You may decide to failover first on the secondary replica on the same datacenter and then the one located on the remote site.
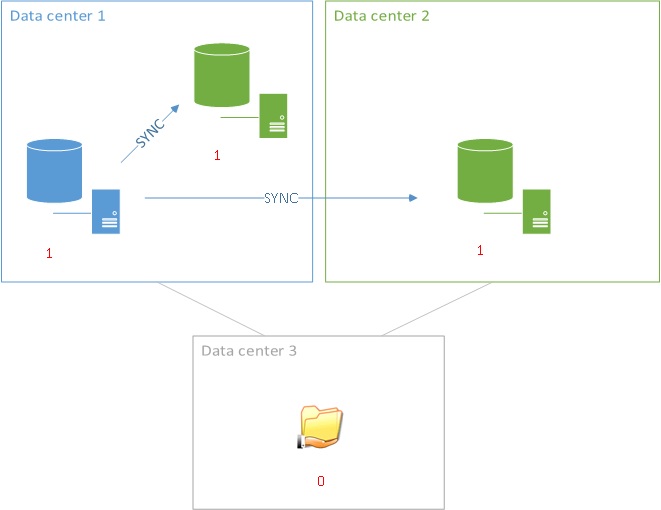
But wait a minute… do you see the weakness in the above architecture? Let’s deal with the node weights (in red). You may noticed that you will have to introduce another replica in order to avoid losing the quorum in case of the datacenter 1 failure. Indeed, you won’t get the majority with the current architecture if it remains nothing but the file share witness and the replica on the datacenter 2. So the new architecture may be the following:
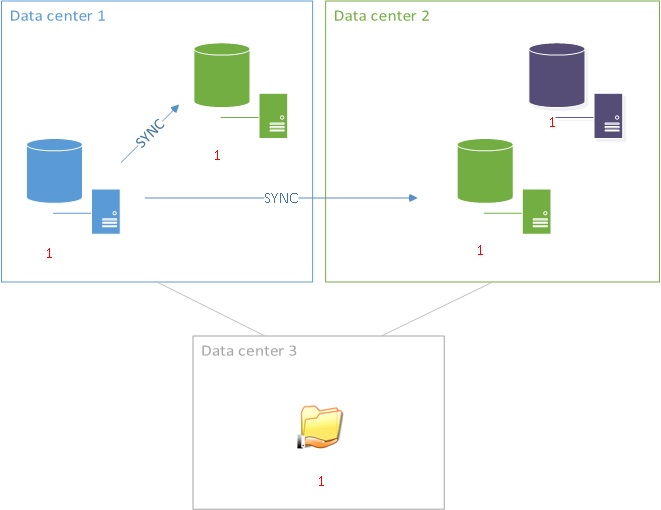
In this case we may or may not decide to use this additional node as a SQL Server replica on the datacenter 2 but it is at least mandatory in the global cluster architecture to provide automatic failover capability for the availability group layer in case of the datacenter 1 failure. This is why I said earlier that introducing this new availability group capability may not be affordable for all of the customers assuming that this additional replica must be licenced.
See you
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JDU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JOC_web-scaled.jpg)