Let’s continue with this third post about SQL Server AlwaysOn and availability groups.
Others studies are available here:
- New database issue level detection for automatic failover
- Potential features in standard edition
- Automatic failover enhancements
This time I’ll talk about read-only secondaries and the new load-balancing support that will be introduced by SQL Server 2016.
First of all, SQL Server 2014 improved the read-only secondary availability by solving the issue related to secondary accessibility when the primary is offline. However, the redirection to a readable secondary was still basic because it concerned only the first secondary replica defined in the configured priority list. So, unless using a third-party tool it was not possible to use very efficiently all of the resources available from secondaries. Fortunately, the next SQL Server version will change the game by introducing native load-balancing capabilities.
In order to be able to use this new feature, you must define:
- The list of possible secondary replicas
- A read-only route for each concerned replica
- A routing list that include read-only replicas and load-balancing rules
At this point I admit to expect a GUI for configuring both read-only routes and the routing list rules in a user friendly fashion even if I prefer using T-SQL to be honest. But anyway, let’s try to configure secondary replicas in round-robin fashion as follows:
My test lab includes 3 replicas (SQL161, SQL162 and SQL163). The secondaries will be used as read-only replicas with the new load-balancing feature.
Note the double brackets around the replicas list that defines the load-balancing mechanism for the concerned replicas. In my context, I have only two read-only replicas but rules are defined as follows:
- (replica1, replica2, replica3): no load-balancing capabilities in this case. The first replica will be used, then the second and finally the third.
- ((replica1, replica2), replica3): replica1 and replica will be used in a round-robin fashion. The replica3 will be used only if both replica1 and replica2 are not available.
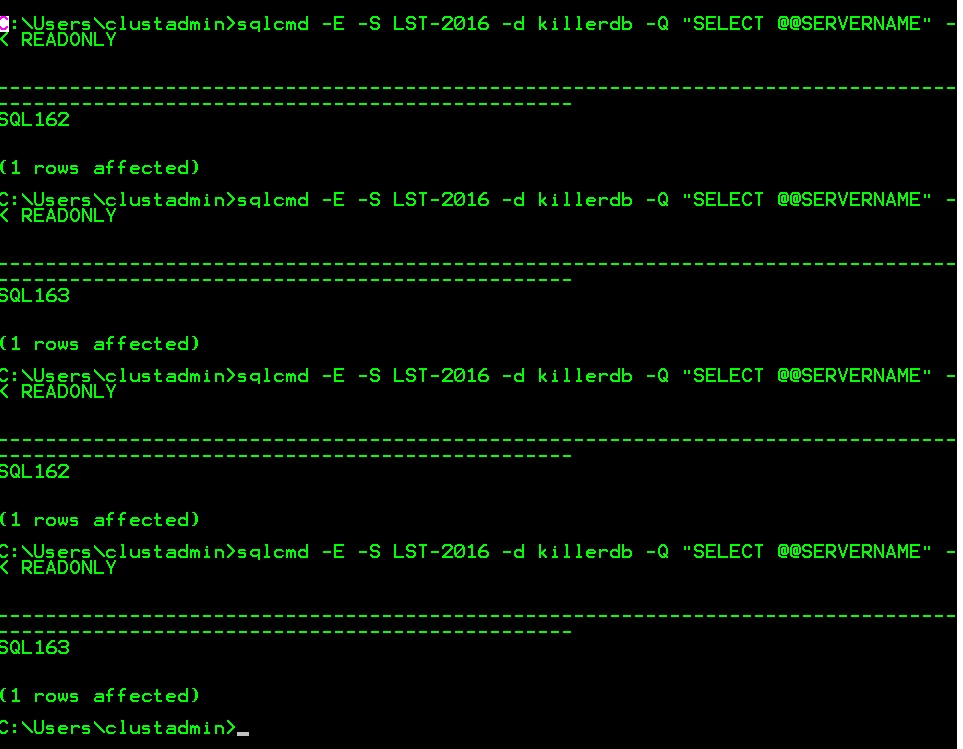
Now let’s play with this new infrastructure by using sqlcmd command as follows:
![]()
As reminder, you have to meet some others requirements in order to use correctly the transparent redirection to a secondary replica as using TCP protocol, referencing directly the availability group listener and the concerned database as well and setting the application intent attribute as readonly. So in my case, I reference directly the LST-2016 listener and the killerdb. I use also the –K parameter with READONLY attribute. Finally, I run the query SELECT @@SERVERNAME in order to know which replica I am after login.
I ran this command several times and I can state that the load-balancing feature plays its full role.
However, let’s play now with the following PowerShell script:
The result is not the same. The redirection to a read-only replica works perfectly but there was not load-balancing mechanism in action this time as shown below:
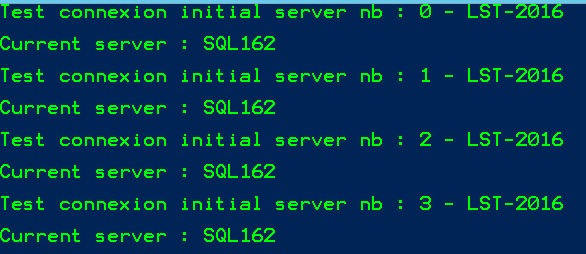
What’s going on in the case? In fact and to be honest, I didn’t remember that PowerShell uses connection pooling by default (thanks to Brent Ozar – @BrentO to put me on the right track).
Let’s take a look at the output of an extended event session that includes the following events:
- sqlserver.login
- sqlserver.logout
- sqlserver.read_only_route_complete
- sqlserver.rpc_completed

You can notice that sqlcmd tool doesn’t use connection pooling (is_cached column = false). In this case for each run, SQL Server will calculate the read-only route.
However for my PowerShell script the story is not the same as shown below:
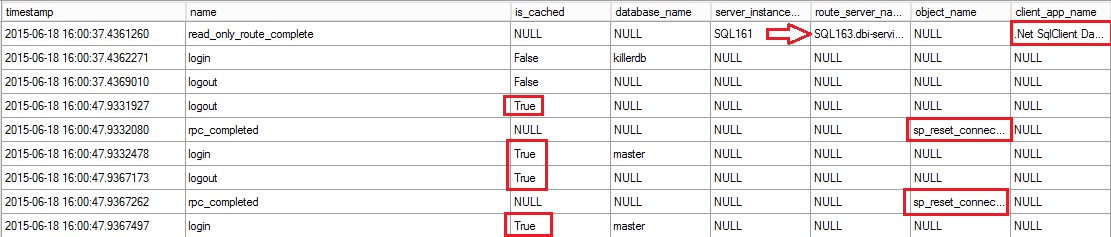
The first connection is not pooled and we can noticed only one read-only route calculation from SQL Server. All of the next connections are pooled and technically they are still alive on the SQL Server instance. This is why the load balancing mechanism is not performed in this case. So this is an important point to keep in mind if you want to plan to benefit to this new feature.
I also had a dream: Having a real load-balancing feature based on resource scheduling algorithm… maybe the next step? 🙂
See you
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JDU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JOC_web-scaled.jpg)