Did you miss aggregate pushdown capability shipped with columnstore index? Well, I remember the first time I heard about it is was when I read the very interesting blog post of Niko Neugebauer here with a very good covering of the topic (principle, advantages and limitations).
So why to write a new blog post here? Well because since the last Niko’s blog article, this feature has been improved and I wanted to test it with real (and simplified) cases scenarios. Furthermore, I did not mention this feature in my last presentation about SQL Server 2016 In-memory technologies and operation analytics with Frederic Pichaut (Microsoft support Engineer) and this is a great opportunity to catch up in this blog post.
First of all, let’s say that this capability has been extended to the nonclustered columnstore indexes (and implicitly to operational analytic area) and it was almost virtually transparent (at least from my part) because it was implemented since the CTP3.0 releases. I finally found out a microsoft link that talk about it here regardless the last documentation about the RC0 release. So feel free to correct me if I’m wrong or to point me on the other references. What is certain is that I got a confirmation from Sunil Agarwal – Principle Program Manager on the SQL Server team when I was surprised to notice the same behavior between the SQL Server 2016 CTP32 and RC0 releases.
So, during my presentation in the last Journées SQL Server event, I used a real customer database that included a table named dbo.inquiry that contained technician intervention related data. This table had roughly 53 million of rows and represents approximatively 10 GB of data with both recent and archive data that starts from year 2002 until 2015 (in fact I virtually increased the amount of data for the demo in a random fashion by script).

I also implemented a nonclustered columnstore index filtered on the open_dt column as following:
CREATE NONCLUSTERED COLUMNSTORE INDEX [idx_cc_inquiry_reporting_management] ON [dbo].[inquiry] ( [inquiry_id], [priority], [open_dt], [assign_dt], [transfer_dt], [should_respond_dt], [should_close_dt], [closed_dt], [RemiseEnService_dt], [owner_rep], [owner_grp], [transfer_rep], [transfer_grp], [inq_gel], [close_in_time], [customer_id], [materiel_id], [year_inter], [month_inter], [duration_inter] ) WHERE ([open_dt] < '20150101') WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY] GO
You many notice that I included a WHERE clause filter based on the reporting workload from my customer. So basically, records older than year 2015 are considered archive data although some few updates may be performed on it.
First scenario
Let’s execute the following query against the dbo.inquiry table. It was an usual reporting query used by my old management team to get a quick trend about the amount of interventions performed by year
use GestionCom; go select year_inter as year_inter, count(*) as nb_inter from dbo.inquiry where open_dt between '20110101' and '20130201' group by year_inter go
How about that aggregate pushdown in this scenario? Let’s say that we have a new available property (Actual Number of Locally Aggregated Rows) to see the aggregate pushdown feature in action. This property is directly accessible from the columnstore scan node operator into the execution plan as shown below:
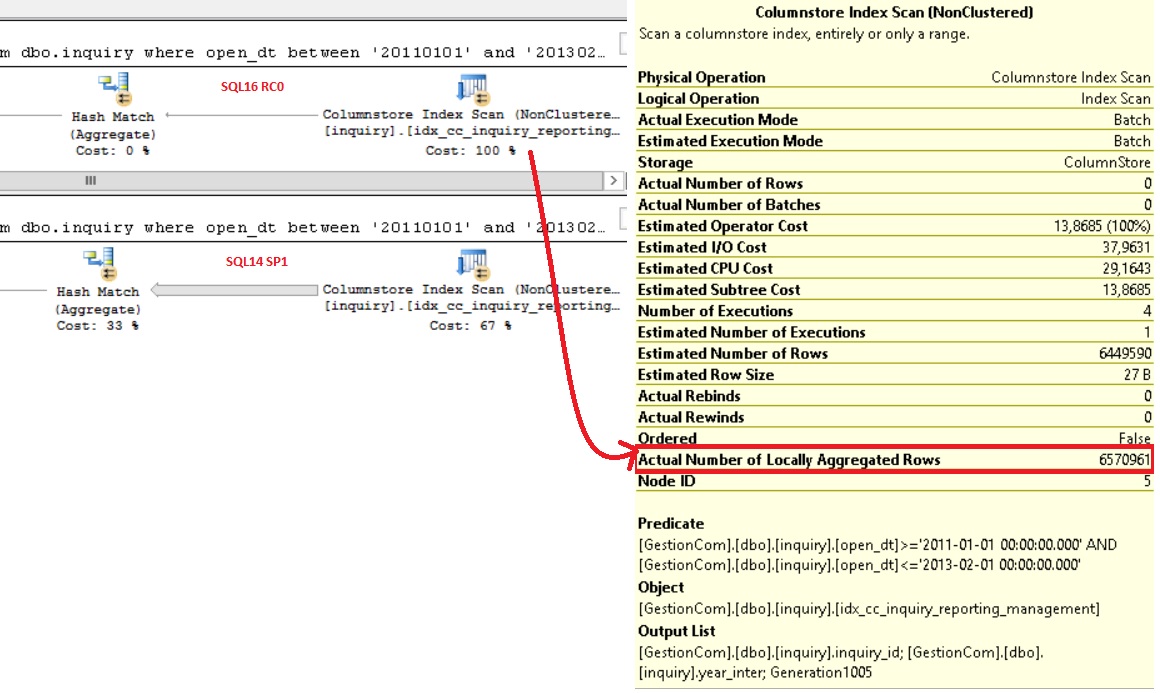
The first plan came from SQL Server 2014 and at the first glance we may notice an obvious difference by looking at the number of rows returned by the scan node operator. In addition the new available property provided useful information about locally aggregated rows. In other words, the number of rows directly aggregated at the storage level. How about performance metrics? Let’s take a look at the execution time for the both queries:
| Environment | CPU Time (ms) | Elapsed Time |
| SQL14 SP1 | 94 | 40 |
| SQL16 RC0 | 251 | 536 |
The performance result is a little bit surprising. Indeed, I expected to get a noticeable improvement with this new feature but this first test tends to be in contradiction with my assumption. I performed many times the same test to exclude external factors but same result. I will go back if I get more information on this topic. Just keep in mind that we are still in RC release so we may notice some weird behaviors.
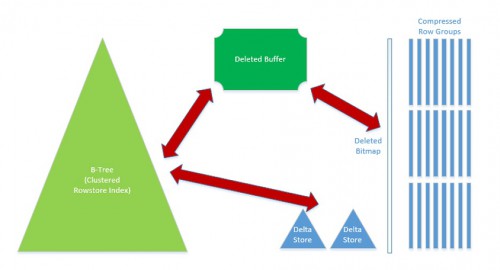
Edit 15.03.2016: it just slipped my mind but we have to remember that there is a noticable difference between SQL14 and SQL16. I tried a comparison between reading a clustered columnstore index with SQL14 against a nonclustered columnstore index with SQL16 and this can make the difference. Indeed, the nonclustered columnstore index is now updatable and it comes with a price (and overhead): a hidden join that filters out old versions of recently modified rows. Let’s remind the implied structure for nonclustered columnstore indexes on disk-based tables (from the Niko’s blog post here). It could explain this difference I noticed for this first test. Many thanks to Vassilis Papadimos (programer at Microsoft to remind me this important detail. Cf comments at the bottom of this blog post).
Ok this is a pretty basic first test but in the real life, reporting queries are not always so simple. So let’s test with other real customer case scenarios.
Second scenario
Let’s focus now exclusively on the RC0 release by executing the next query. This is the same query than previously with one exception: year(open_dt) replaces the year_inter column.
select year(open_dt), count(*) as nb_inter from dbo.inquiry where open_dt between '20110101' and '20150201' group by year(open_dt) order by year(open_dt) desc option (maxdop 4) go
You probably noticed that in the previous query I used a columned named year_inter to group data. In fact this column contains pre-computed year value for each intervention and I added it to my OLTP table in order to take advantage of the aggregate pushdown feature. But let’s say that in a real scenario, you probably will not be able to add new columns on an existing table and you will be forced to use functions as YEAR to meet the same requirements. I may see a lot of reporting queries based on this group by clause. Let’s see the new execution plan:
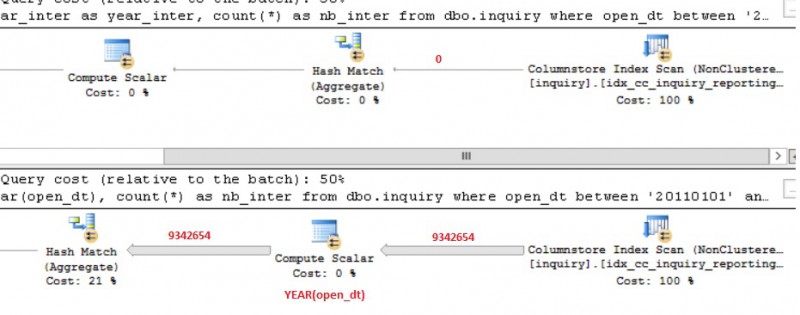
We may clearly notice that using the YEAR function in the group by clause inhibits the aggregate pushdown feature. To be honest, this is a result I expected because at this point, we force the optimizer to retrieve all concerned records related from the WHERE clause (note that segment elimination still works here), then compute and extract the corresponding year information and finally aggregate data. I don’t know if it is technically possible but it could be a good point to leverage this functionality in the future that would address a lot of reporting scenarios. Of course, a potential workaround is to add a column that will contain the year information but working with computed columns doesn’t work yet with columnstore indexes. So adding a new column may have a huge impact here because we have to find out another process to fill up the column with corresponding values.
Third scenario
Let’s try with the following query. This time, we add another analysis axis by introducing the person who made the intervention. Once again, it is a common query that my old management team potentially wanted to use.
select i.year_inter, e.name as technician, count(*) as nb_inter from dbo.inquiry as i join dbo.employees as e on i.transfer_rep = e.id where open_dt between '20110101' and '20131231' group by i.year_inter, e.name order by i.year_inter desc, nb_inter asc option (maxdop 4) go
By using the above query, I wanted to test the aggregate pushdown support for multi-column in the group by clause and great news it seems to work referring to the produced execution plan below:
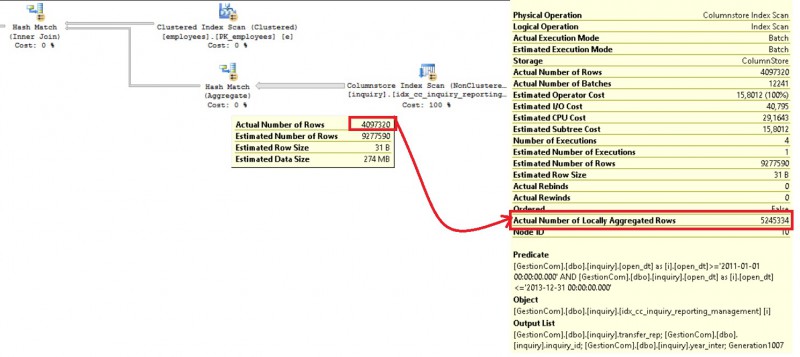
But wait … we don’t get the exactly the same result than the first query in terms of returned rows. Indeed, the aggregate pushdown feature aggregates 5245334 rows. A good ratio but, all the rows seem to not be considered by the feature. Moreover, let’s take a look at the number of rows handled by the scan node operator. My guess is that the number of estimated rows in this context is the number of rows before the aggregation process and if we perform some math with 9277590 – 5245334 = 4032256, we are pretty close to the actual number of rows at the scan operator’s output. At this point, I don’t have any idea of which pre-aggregation is performed by the storage engine (is it really a pre-aggregation?). The hash match (aggregate) operator will finalize the aggregation work by applying the scalar function COUNT here to its input for sure. I will probably come back to this specific point when if I will get further details.
Fourth scenario
Another interesting scenario is represented by the following query. We have replaced the analysis axis by the owner_grp colum column that contains VARCHAR data.
select owner_grp, count(*) as nb_inter from dbo.inquiry where open_dt between '20110101' and '20131231' group by owner_grp order by count(*) desc option (maxdop 4) go
Let’s execute the query and let’s have a look at the execution plan.
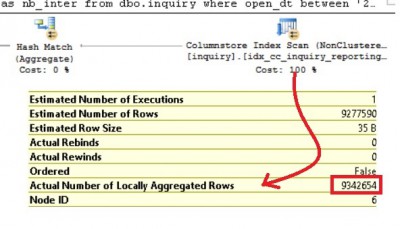
Suprise! The aggregate pushdown feature seems to work even with string characters unlike what we may see from the Microsoft documentation here.
To improve performance, SQL Server computes the aggregate functions MIN, MAX, SUM, COUNT, AVG during table scans when the data type uses no more than eight bytes, and is not of a string type
Fifth scenario
Let’s continue with the following query. This time we want the number of interventions by customer identifier.
select i1.customer_id, count(*) as nb_inter from dbo.inquiry as i1 where open_dt between '20030110' and '20031231' group by i1.customer_id option (maxdop 4)
This time, the aggregate pushdown feature seems to not be used “optimally” according to the following query plan.
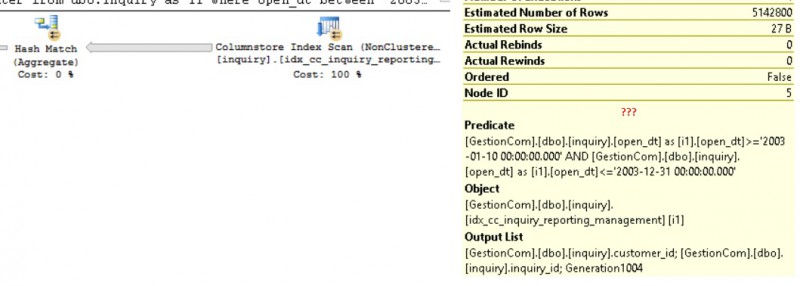
Why aggregating only 67 rows and not all concerned rows? At this point, my guess is that the number of aggregated rows is relied on the statistics used by the optimizer because aggregate pushdown is used differently regarding the WHERE clause predicates. I tried different date intervals and noticed different behaviors. Well, another point to keep in mind and I will come back with additional information about this topic.
Sixth scenario
This time this is a query that focus on the technician payload per year. In this context, the payload is not accessible directly as a column value and we have first to compute it. The payload corresponds to the duration time related to each intervention done by a technician on site or in remote. So we need to compute the duration time by making the difference between the two columns: open_dt and closed_dt as well. However, according to the defined SLA, we have to stop the duration time counter when a technician arrives on site introducing by the RemiseEnService_dt column value. If for any reason this column is not filled up we need to consider the closed_dt column instead of the RemiseEnService_dt column and in the last resort if no values exist in these two columns, we have to compute a virtual duration time for the concerned intervention. As you may see, getting the intervention duration time is a complicated process and this is one example among many others I may face at different customer places. So the query that meets our requirement is the following:
select year_inter, count(*) as nb_inter, sum(cast(datediff(hh, open_dt, coalesce(RemiseEnService_dt, closed_dt, dateadd(hh, 9, open_dt))) as bigint) / 8) as nb_days from dbo.inquiry as i where open_dt between '20020101' and '20051231' group by year_inter order by year_inter desc
As I may expected, the aggregate pushdown is inhibited in this case (but segment elimination performs well) because we have to compute for each line the intervention duration time before aggregating data.
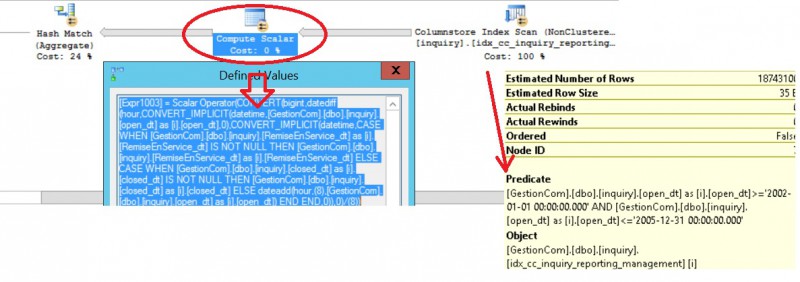
Is there a way to benefit to the aggregate pushdown feature? Well, yes it possible but once again we have to add a corresponding extra column to the table with all impacts previously discussed.
However, adding such column may potentially help to reduce both the CPU and duration time (x9 in my case)
| Method | CPU time (ms) | Elapsed time (ms) |
| Without aggregate pushdown | 1720 | 464 |
| With aggregate pushdown | 188 | 59 |
Last scenario
Finally let’s execute a last query to get an idea of a real improvement we may expect by using both segment elimination, aggregate pushdown feature and the new aggregate windows operator (that uses batch mode for windows functions). The following query was used by my old management team to get statistical data distribution about the owner groups and the number of their interventions. A very common pattern usage for reporting queries in order to know where to focus efforts in terms of investment.
with top_3_inters as ( select year_inter, owner_grp, count(*) as nb_inter, row_number() over (partition by year_inter order by count(*) desc) as num from dbo.inquiry where open_dt between '20020101' and '20101231' group by year_inter, owner_grp ) select year_inter, owner_grp, nb_inter from top_3_inters where num <= 3 order by year_inter, nb_inter desc
Here the corresponding execution plan:
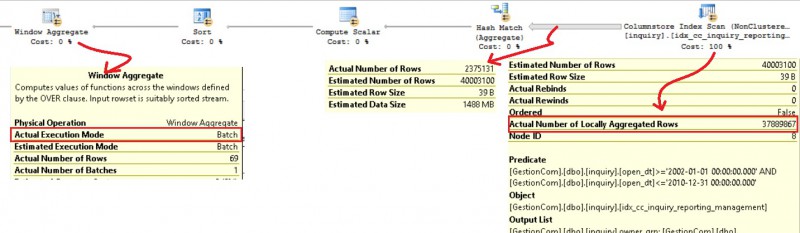
Now let’s compare with the performance of the same query executed against SQL Server 2014
| Environment | CPU Time (ms) | Elapsed Time (ms) |
| SQL14 CTP1 | 18313 | 35464 |
| SQL16 RC0 | 265 | 78 |
Performance results are relevant here 🙂
Bottom line
Aggregate pushdown will certainly help for reporting query performance. I just noticed some limitations that I would like to be dropped in the future. We may address these limitations by some workarounds but depending on the context it will not be always obvisous. What is certain is that I’m pretty sure to not examine this topic from all sides and new columnstore features shipped with SQL Server 2016 tend to think that other nice surprises are waiting to us!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/NME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)