As you certainly know, the SQL Server 2014 SP2 has been released by Microsoft with some interesting improvements that concern SQL Server AlwaysOn and availability groups feature. In fact, all of them are also included into SQL Server 2012 SP3 and SQL Server 2016 (update 24.09.2016: not yet released with SQL Server 2016). Among all fixes and improvements that concern AlwaysOn, I would like to focus on those described in the Microsoft KB3173156 and KB3112363. But in this first blog post, I will just cover those who concern the lease timeout which is part of the AlwaysOn health model.
Did you already face lease timeout issue ? If yes, you have certainly noticed it is an good indicator of system wide problem and figure out what is the root cause could be a burden task because we missed diagnostic information and we had to correlate different performance metrics as well. Fortunately, the release of new service packs provide enhancements in this area.
Let’s take an example with a 100% CPU utilization scenario that leads to make the primary replica unresponsive and unable to respond to cluster isAlive() routine. This is typically a situation where we may face a lease timeout issue. After simulating this scenario on my lab environment,here what I found in the SQL Server error log from my primary replica. (I have voluntary filtered to include only the sample we want to focus on).

Firstly, we may see different new messages related to lease timeout issues between the range interval 12:39:54 – 12:43:22. For example, the WSFC did not receive a process event signal from SQL Server within the lease timeout period or the lease between AG and the WSFC has expired. Diagnostic messages have been enhanced to give us a better understanding of the lease issue. But at this point we know we are facing lease timeout but we don’t know the root cause yet. Improvements have also been extented to the cluster log in order to provide more insights to the system behavior at the moment of the lease timeout issue as we may see below:
00000644.00000768::2016/07/15-12:40:06.575 ERR [RCM] rcm::RcmResource::HandleFailure: (TestGrp)
00000644.00000c84::2016/07/15-12:40:06.768 INFO [GEM] Node 2: Sending 1 messages as a batched GEM message
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] resource TestGrp: failure count: 0, restartAction: 0 persistentState: 1.
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] numDependents is zero, auto-returning true
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] Will queue immediate restart (500 milliseconds) of TestGrp after terminate is complete.
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] Res TestGrp: ProcessingFailure -> WaitingToTerminate( DelayRestartingResource )
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] TransitionToState(TestGrp) ProcessingFailure–>[WaitingToTerminate to DelayRestartingResource].
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] Res TestGrp: [WaitingToTerminate to DelayRestartingResource] -> Terminating( DelayRestartingResource )
00000644.00000768::2016/07/15-12:40:06.768 INFO [RCM] TransitionToState(TestGrp) [WaitingToTerminate to DelayRestartingResource]–>[Terminating to DelayRestartingResource].
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] 7/15/2016 10:39:24.0, 8.866394, 912523264.000000, 0.000450, 0.000904
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] 7/15/2016 10:39:34.0, 25.287347, 919531520.000000, 0.001000, 0.000594
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] 7/15/2016 10:39:44.0, 25.360508, 921534464.000000, 0.000000, 0.001408
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] 7/15/2016 10:39:55.0, 81.225454, 921903104.000000, 0.000513, 0.000640
00000cc0.00001350::2016/07/15-12:40:12.452 WARN [RES] SQL Server Availability Group: [hadrag] 7/15/2016 10:40:5.0, 100.000000, 922415104.000000, 0.002800, 0.002619
00000cc0.00001350::2016/07/15-12:40:12.452 INFO [RES] SQL Server Availability Group: [hadrag] Stopping Health Worker Thread
According to the SQL Server error log time range we may notice similar messages that concern the detection of lease timeout with some additional information that came from the perfmon counters (Concerned lines are underlined in the sample above). If we reformat the concerned portion into the table below we may get a better identification of our issue
| Date/Time | Processor time (%) | Availability memory(bytes) | Avg disk read(secs) | Avg disk write(secs) |
| 10:39:24.0 | 8.866394 | 912523264 | 912523264 | 0.000904 |
| 10:39:34.0 | 25.287347 | 919531520 | 0.001000 | 0.000594 |
| 10:39:44.0 | 25.360508 | 921534464 | 0.000000 | 0.001408 |
| 10:39:55.0 | 81.225454 | 921903104 | 0.000513 | 0.000640 |
| 10:40:5.0 | 100.000000 | 922415104 | 0.002800 | 0.002619 |
CPU utilization is what we must focus on here. So getting this valuable information directly to the cluster.log when we troubleshoot lease timeout issue will help us a lot. But just to clarify, this doesn’t mean that it was not possible with older versions but we have to retrieve them in a more complicated way (by using the AlwaysOn_health extended event for example).
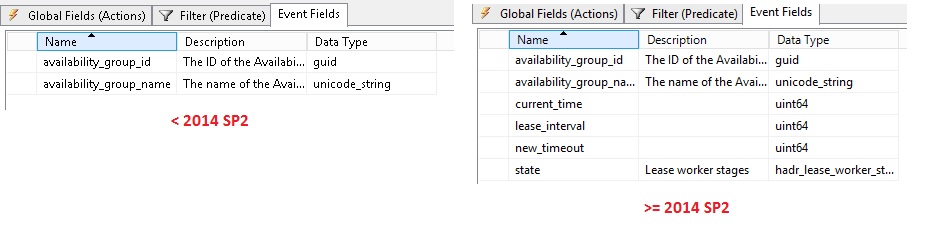
Next, other improvements concern existing extended events like availability_group_lease_expired and hadr_ag_lease_renewal. The next picture points out new available fields like current_time, new_timeout and state as well.
Let me show you their interest with another example. This time, I voluntary hang my sqlserver.exe process related to the primary replica in order to trigger an unresponsive lease scenario. I got interesting outputs from the extended event trace on both sides.
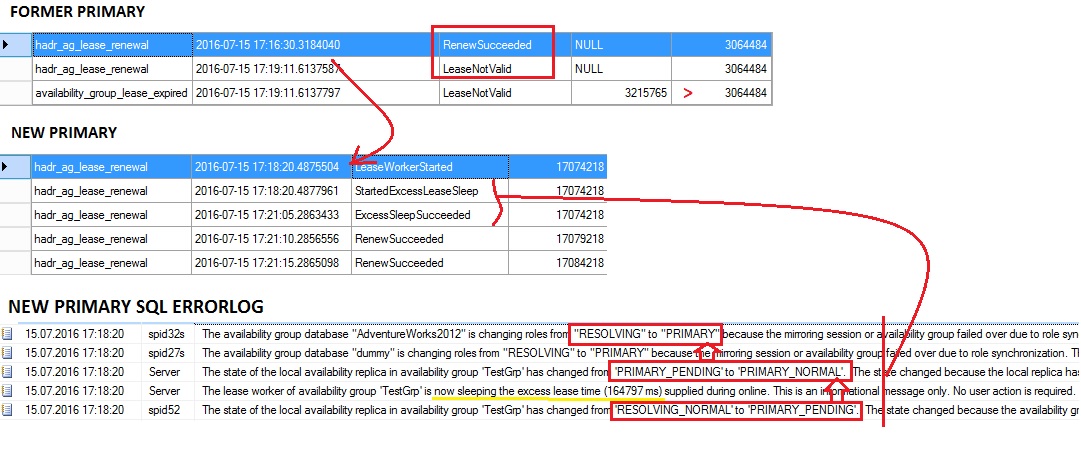
From the former primary, there are no related records during the period of the SQL Server process responsiveness but we may see a record at 17:19:11. The lease renewal process fails and we get a better picture of the problem by looking at the corresponding state (LeaseNotValid) followed by the availability_group_lease_expired event. Note that the current_time (time at which the lease expired) value is greater than the new_timeout (time out time, when availability_group_lease_expired is raised) value here – 3215765 > 3064484 – which confirms that we experienced a timeout issue in this case.
On the new primary, we may notice the start of the lease worker thread but until the concerned replica stabilizes the PRIMARY ONLINE state, it voluntary postpones the lease check process (materialized by StartedExcessLeaseSleep / ExcessSleepSucceeded state values).
In the next blog I will talk about improvements in the detection of the availability group replication latency.
Stay tuned!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)