Often, when I’m in charge to implement an SQL Server AlwaysOn infrastructure with availability groups, customers ask me if it exists some best practices and recommendations about the maximum number of databases in an availability group planning. In fact, we have to keep in mind the relation between databases and the SQL Server worker pool in this architecture. Remember that the SQL Server AlwaysOn and availability group feature is an extension of the SQL Server mirroring and we retrieve the same concept of worker thread usage with a different architecture: Mirroring feature dedicates worker threads for each database compared to SQL Server AlwaysOn that uses requests queue and worker pool (aka HADR pool). Let’s see how the HADR worker pool behaves and its tight relationship with the databases.
First of all, let’s take a look at the Microsoft documentation here – “Prerequisites, Restrictions, and Recommendations for AlwaysOn Availability Groups – and let’s have a focus on the “Thread Usage by Availability Groups” section. After reading the content we can notice that the number of databases is an important part of the minimum hadr pool size calculation among others factors. Others factors are the following:
- Number of replicas
- Log capture thread
- Log send queue thread
- Message handler thread
Another point to keep in mind is that the size of the HADR worker pool is capped by the “max worker thread” parameter as shown below:
Hadr pool size max = max worker threads – 40
I also encourage you to read the excellent article of Bob Dorr that provides a formula to estimate the minimum size of the HADR worker pool. Once again we can notice that the number of databases is still relevant here. As explained by Bob Dorr, the max databases parameter concerns only the “active” databases where “active”.
Let’s perform a quick calculation of the min pool size in the worst case (all databases are active) required on the primary replica with several configurations based on the Bob Dorr’s formula:
Min Pool Size = Max Databases * (Log Capture Thread + (Log Send Thread * Nb secondary replicas)) + Message Handler Thread
| One secondary replica | Two secondary replicas | |
| 100 databases | 100 * 2 + 1 = 201 | 100 * 3 + 1 = 301 |
| 500 databases | 500 * 2 + 1 = 1001 | 500 * 3 + 1 = 1501 |
| 1000 databases | 1000 * 2 + 1 = 2001 | 1000 * 3 + 1 = 3001 |
Then let me show you a more real picture with my lab that includes a SQL Server AlwaysOn 2014 (64 bits) with one availability group and two replicas (basically one primary and one secondary). Each replica is configured with 4 VCPU and no affinity mask, so all the CPU are visible from each replica.
Next, according to the Microsoft documentation here, we will be capped by the “max worker threads” parameters equal to 512 in my case. Thus, the maximum size of the HADR worker pool size will be 512 – 40 = 472.
Now let’s play with different scenarios:
1- First scenario (no availability groups)
The first scenario includes an environment with no availability groups. The global number of worker threads is as following:
select scheduler_id,current_tasks_count, current_workers_count,active_workers_count,work_queue_count from sys.dm_os_schedulers where status = 'VISIBLE ONLINE' go
This view is not perfect in our case because it includes all the worker threads of the SQL Server instance (hadr worker threads are included to this number). But we will use it as a starting point because there is no activity on my lab and we can admit that the active_workers_count column value will be relatively close than the number of HADR worker threads.

2 – Second scenario (availability group with 100 idle databases)
The second scenario consists in adding 100 databases to my newly availability group but there is no activity. Let’s have a look at the global number of worker threads:

The number of worker threads has increased but this is not a big deal here because the availability databases are not very active. At this point I want to introduce another way to get the number of hadr worker threads by using the extended events and the hadr_thread_pool_worker_start event:
The extended event session I used during my test …
create event session HadrThreadPoolWorkerStart on server add event sqlserver.hadr_thread_pool_worker_start add target package0.event_file ( set filename = N'E:\SQLSERVER\SQL14\backup\HadrThreadPoolWorkerStart.xel' ) with ( max_memory = 4096 KB, event_retention_mode = allow_single_event_loss, max_dispatch_latency = 30 seconds, max_event_size = 0 KB, memory_partition_mode = none, track_causality = off, startup_state = on ); go
… the data extraction script:
declare @top_count int;
set @top_count = 100;
;with xe_cte as
(
select
object_name,
cast(event_data as xml) as event_data
from sys.fn_xe_file_target_read_file ( 'E:\SQLSERVER\SQL14\backup\HadrThreadPoolWorkerStart*.xel', null, null, null)
)
select top (@top_count)
DATEADD(hh, DATEDIFF(hh, GETUTCDATE(), CURRENT_TIMESTAMP), event_data.value('(/event/@timestamp)[1]', 'datetime2')) AS [timestamp],
event_data.value('(/event/data/value)[3]', 'int') as active_workers,
event_data.value('(/event/data/value)[2]', 'int') as idle_workers,
event_data.value('(/event/data/value)[1]', 'int') as worker_limit,
event_data.value('(/event/data/value)[4]', 'varchar(5)') as worker_start_success
from xe_cte
order by [timestamp] desc;
… and the result:
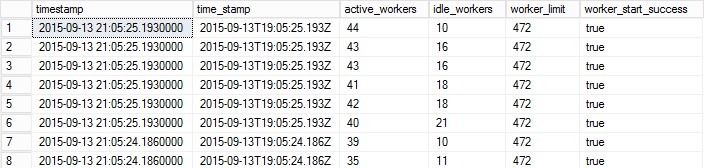
3- Third scenario (availability group with 200 idle databases)
Let’s add 100 additional databases and let’s have a look at the sys.dm_os_schedulers DMV:

Here, the result from the extended event session:
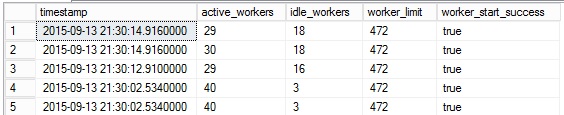
As the previous scenario, the number of active worker threads is still low because there is no activity on the availability databases.
4- Fourth scenario (availability group with 300 “active” databases)
In this scenario, let’s add 100 additional databases (for a total of 300 databases) but this time we will simulate a workload that will perform randomly on different availability databases.
Let’s take a look at the extended event session to see the number of active workers:
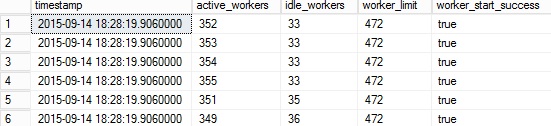
As you can notice, the story is not the same. A big increase of the number of HADR active workers (roughly 258) can be noticed here. However, if I refer to Bob Dorr’s formula in his article, we may be disappointed by the number of threads that we get from the extended event session that is theoretically lower than we can expect for a total number of 300 databases (300 *2 + 1 = 601). At this point, my guess is that my workload and my lab configuration didn’t allow to reach out the HADR worker thread starvation scenario but in fact, this is not so important here because the goal was simply to highlight the difference between the number of active worker threads between an idle and active situation.
5- Fifth scenario : case of a worker threads exhaustion scenario
In the previous scenarios, we saw that increasing the number of databases can have an impact on an availability group. From my point of view, facing this situation is probably the worst scenario but we have to take into account in your design regarding your context.
In this scenario, I will voluntary increase the number of databases up to 500 to reach out more quickly the number of allowed active worker threads.
Here’s a picture of such scenario from the extended event session:
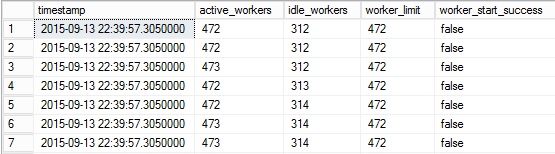
We are in a situation of HADR worker pool starvation (active workers = work limit = 472). Moreover, the work_start_success column value (= false) indicates the SQL Server’s inability to start a new HADR worker.
After a big coffee break, here what I saw from the SQL Server error log. This message indicates an excessive worker thread contention after 15 minutes.

If you see this error message in your availability groups environment, it’s time to check the number of availability databases. You may face this situation more often than you may think. I can see a lot of customer situations where availability groups are tied to consolidated databases environments. In such situation, adding a database can become a semi-automatic process and the number of HADR worker threads can be out quickly of the control.
What is the solution in this case? Add more worker threads? More processors? Reduce the number of databases? I guess you know what I will answer: it depends on your context.
So, in this blog post we’ve seen that the number of databases in an availability group may be a problem regarding your infrastructure and the number of databases hosted in your availability group. Therefore, this topic can be probably one of your concern if you plan to consolidate a lot of databases in your availability groups. In this case, I would probably recommend to my customers to include the hadr worker pool in his monitoring tool.
Hope this helps.
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)