A couple of weeks ago, I was involved in a discussion on the French forum developpez.com about SQL Server AlwaysOn and availability groups, index strategies and the impact on the readable secondary replicas. During this discussion, one of the forum member stated that rebuilding an index online had less impact than rebuilding an index offline on a readable secondary replica but I disagree with this affirmative. Is it really true? Let’s verify in this blog post.
First of all, let’s talk quickly about readable secondary replicas. Each engaged secondary replica has a dedicated redo thread which is responsible to apply the log records that come from the primary replica to the secondary replica (regardless the synchronization type). However, we can be in a situation where this thread can be blocked and it can leave the secondary replicas far behind (with an effective impact on the RTO defined for the concerned databases / applications). One of the common situation you may face is the following: a long running query on a readable secondary replica and at the same time a rebuild index operation is in progress followed by other DML commands on the primary replica.
In fact, rebuilding an index generates a DDL operation (ALTER INDEX … REBUILD) that must be propagated and applied by the redo thread on each secondary replica. This operation needs to take a Sch-M lock that can block the redo thread while the reporting query is running.
So, let’s begin on the primary replica … What is the difference between rebuilding an index offline and online? Well, the latter is very interesting to reduce the overall lock contention. Indeed, with exception of short-time shared (S) at the beginning and schema-modification (Sch-M) locks at the end of the execution, there are no full table locks held. Other users can access the table, and read, and modify data from there. The former needs to acquire schema modification (Sch-M) lock for the duration of the execution, which blocks entire access to the table even in read uncommitted transaction isolation level.
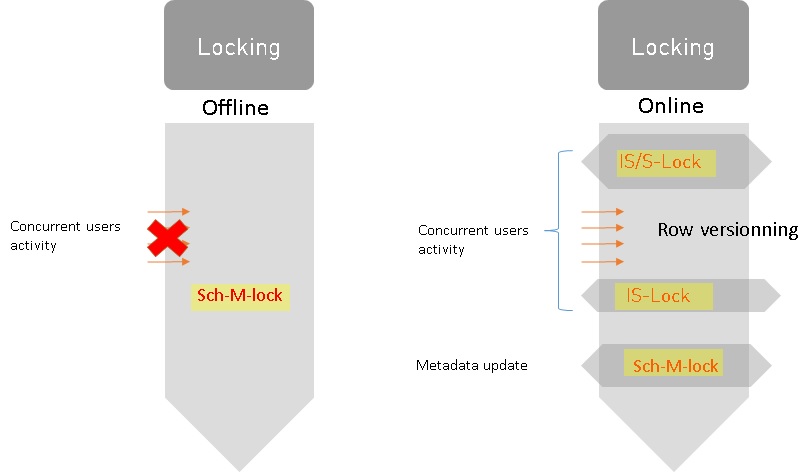
But wait… The above explanation is only valid on the primary replica. What about the secondary replicas? In fact, the story is not the same because the Sch-M lock must be applied by the redo thread which can be blocked while a long reporting query is running as said above. In this case, the blocking point is shifted from the offline / online feature to the total duration of the reporting query itself on each concerned secondary as shown below:
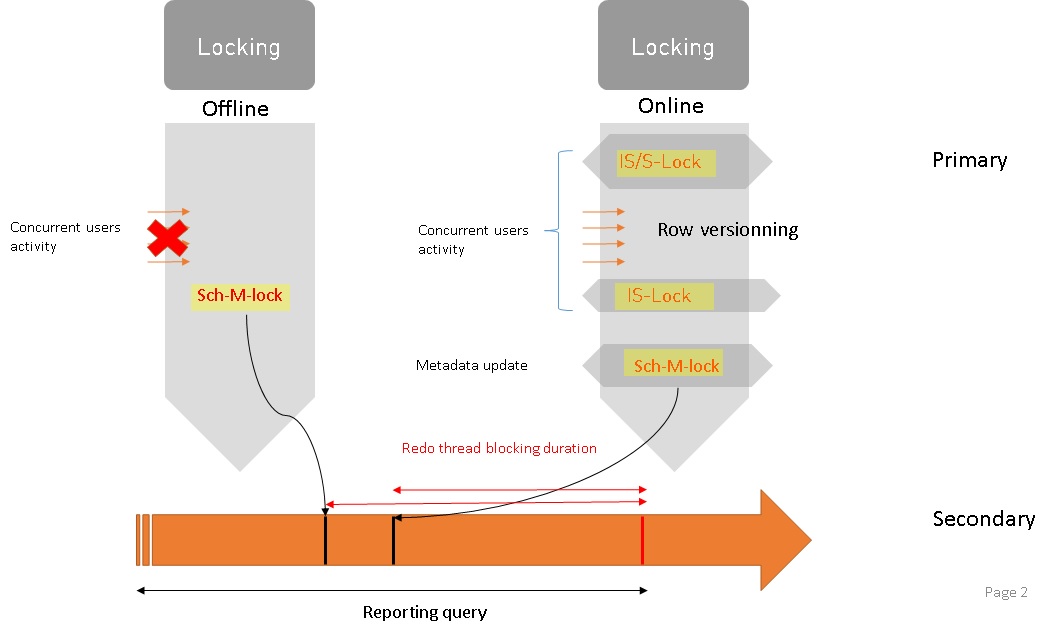
In both cases (rebuild index offline and online), we will be blocked on the secondary until the long running query is finished. Furthermore, generally speaking, rebuilding an index offline is quicker than performing the same operation online especially if there is an important concurrent DML activity at the same period. This is why on the above schema you will see the offline index mark before the online index mark in the timeline.
Let me illustrate this point on my lab environment that consists of a pretty basic configuration:

I will use for my tests the famous bigTransactionHistory table in the AdventureWorks database.
On the primary replica I will rebuild the following index offline or online to compare each scenario:
- The index definition:
CREATE NONCLUSTERED INDEX IX_ProductId_TransactionDate ON bigTransactionHistory ( ProductId, TransactionDate ) INCLUDE ( Quantity, ActualCost ) GO
- The index rebuild statement
alter index IX_ProductId_TransactionDate on bigTransactionHistory rebuild -- with (online = on)
Finally, on my readable secondary replica, I will use the following query to simulate my reporting activity:
dbcc dropcleanbuffers; go select ProductID, sum(cast(Quantity as bigint)) from dbo.bigTransactionHistory cross join (select number from master..spt_values where type = 'P') as t cross join (select number from master..spt_values where type = 'P') as t2 cross join (select number from master..spt_values where type = 'P') as t3 cross join (select number from master..spt_values where type = 'P') as t4 cross join (select number from master..spt_values where type = 'P') as t5 group by ProductID option (maxdop 1) go
On both scenarios, I noticed that the total duration of the blocking state of the redo thread is tightly relied to the total duration of the reporting query execution. We can notice by taking a look at the information provided by sys.dm_exec_requests DMV on the secondary replica the state of the redo thread during the execution of my reporting query on my readable secondary replica:
select session_id, command, blocking_session_id, wait_time, wait_type, wait_resource, total_elapsed_time from sys.dm_exec_requests where command = 'DB STARTUP' or session_id = 56

Session_id = 49 is related to the redo thread and the session_id = 56 to my reporting query. You can notice the related wait type here: LCK_M_SCH_M issued by the ALTER INDEX REBUILD command on the primary replica in a waiting state.
We can also get additional information by taking a look at the redo queue value with the sys.dm_hadr_availability_replica_states DMV.
SELECT ag.name AS ag_name, ar.replica_server_name AS ag_replica_server, dr_state.database_id as database_id, CASE WHEN ar_state.is_local = 1 THEN N'LOCAL' ELSE 'REMOTE' END AS is_ag_replica_local, CASE WHEN ar_state.role_desc IS NULL THEN N'DISCONNECTED' ELSE ar_state.role_desc END AS ag_replica_role, ar_state.connected_state_desc, ar.availability_mode_desc, dr_state.synchronization_state_desc, dr_state.redo_queue_size, dr_state.redo_rate FROM sys.availability_groups AS ag JOIN sys.availability_replicas AS ar ON ag.group_id = ar.group_id JOIN sys.dm_hadr_availability_replica_states AS ar_state ON ar.replica_id = ar_state.replica_id JOIN sys.dm_hadr_database_replica_states dr_state on ag.group_id = dr_state.group_id and dr_state.replica_id = ar_state.replica_id;

The redo queue size suggests also that there is a problem with the redo thread. Then, when I performed some additional updates on the dbo.bigTransactionHistory table the redo queue increased accordingly to my update activity. Finally, once my reporting query finished, the redo thread was unlocked and was able to continue to apply the remaining log records in the redo queue. After a few seconds, the redo queue size dropped quickly to zero as shown below:

In conclusion, we’ve seen that performing index rebuild operations with either online or offline options can effectively have a different impact depending on where the action is performed (primary or secondary replica). However we have to keep in mind that on the secondary replicas, the use of the both options doesn’t matter and has the same effect on the redo thread. Instead, the queries from the read only activity become our main concern in this case.
Hope this helps!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)