Let’s continue with this series about inserting 1M rows and let’s perform the same test with a new variation by using SQL Server In-Memory features. For this blog post, I will still use a minimal configuration that consists of only 1 virtual hyper-V machine with 1 processor, 512MB of memory. In addition my storage includes VHDx disks placed on 2 separate SSDs (one INTEL SSDC2BW180A3L and one Samsung SSD 840 EVO). No special configuration has been performed on Hyper-V.
Let’s begin by the creation script of my database DEMO:
CREATE DATABASE [demo]
ON PRIMARY
( NAME = N'demo_data', FILENAME = N'E:\SQLSERVER\demo_data.mdf' , SIZE = 1048576KB , MAXSIZE =UNLIMITED, FILEGROWTH = 1024KB ),
FILEGROUP [demo_hk_grp] CONTAINS MEMORY_OPTIMIZED_DATA DEFAULT
( NAME = N'demo_hk', FILENAME = N'E:\SQLSERVER\HK' , MAXSIZE = UNLIMITED)
>LOG ON
( NAME = N'demo_log', FILENAME = N'F:\SQLSERVER\demo_hk_log.ldf' , SIZE = 1395776KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
ALTER DATABASE [demo] SET COMPATIBILITY_LEVEL = 120
GO
ALTER DATABASE [demo] SET RECOVERY SIMPLE;
GO
Next the creation script of all user objects that includes:
- 2 disk-based tables: DEMO_DB_PK (with a clustered primary key) and DEMO_DB_HP (a heap table)
- 2 In-Memory optimized tables: DEMO_HK_SCH_DATA (data arepersisted) and DEMO_HK_SCH (only schema is persisted)
CREATE TABLE [dbo].[DEMO_DB_PK]
(
[id] [int] NOT NULL primary key,
[varchar](15) COLLATE French_CI_AS NULL, [number] [int] NULL, ) CREATE TABLE [dbo].[DEMO_DB_HP] ( [id] [int] NOT NULL,
[varchar](15) COLLATE French_CI_AS NULL,
[number] [int] NULL,
)
CREATE TABLE [dbo].[DEMO_HK_SCH_DATA]
(
[id] [int] NOT NULL,
[varchar](15) COLLATE French_CI_AS NULL, [number] [int] NULL, PRIMARY KEY NONCLUSTERED HASH ( [id] )WITH ( BUCKET_COUNT = 2097152) )WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ) GO CREATE TABLE [dbo].[DEMO_HK_SCH] ( [id] [int] NOT NULL,
[varchar](15) COLLATE French_CI_AS NULL,
[number] [int] NULL,
PRIMARY KEY NONCLUSTERED HASH
[id]
)WITH ( BUCKET_COUNT = 2097152)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_ONLY )
GO
Finally, the last script of creating 7 stored procedures in order to test different cases:
- sp_demo_insert_demo_db_hp: insert 1M rows inside a disk-based heap table
- sp_demo_insert_demo_db_pk: insert 1M rows inside a disk-based clustered table
- sp_demo_insert_demo_hk_sch_data: insert 1M rows inside an In-Memory optimized table in INTEROP with data persisted on disk
- sp_demo_insert_demo_hk_sch: insert 1M rows inside an In-Memory optimized table in INTEROP with only schema persisted on disk
- sp_demo_insert_demo_hk_sch_data_cp: insert 1M rows inside an In-Memory optimized table in NATIVE with data persisted on disk and durability
- sp_demo_insert_demo_hk_sch_data_cp_d: insert 1M rows inside an In-Memory optimized table in NATIVE with data persisted on disk and delayed durability enable
- sp_demo_insert_demo_hk_sch_cp: insert 1M rows inside an In-Memory optimized table in NATIVE with only schema persisted on disk
Just as reminder, INTEROP procedures allow using both disk-based and In-Memory optimized tables whereas the NATIVE (or natively compiled) procedures doesn’t support disk-based tables. However, using the latter is very interesting in performance perspective because it improves drastically the execution time.
CREATE PROCEDURE [dbo].[sp_demo_insert_demo_db_hp]
AS
SET NOCOUNT ON;
DECLARE @i INT = 1;
WHILE @i <= 1000000
BEGIN
INSERT INTO dbo.DEMO_DB_HP VALUES (@i, CASE ROUND(RAND() * 10, 0) WHEN 1 THEN 'Marc' WHEN 2 THEN 'Bill' WHEN 3 THEN 'George' WHEN 4 THEN 'Eliot' WHEN 5 THEN 'Matt' WHEN 6 THEN 'Trey' ELSE'Tracy' END, RAND() * 10000);
SET @i += 1;
END
GO
CREATE PROCEDURE [dbo].[sp_demo_insert_demo_db_pk]
AS
SET NOCOUNT ON;
DECLARE @i INT = 1;
WHILE @i <= 1000000
BEGIN
INSERT INTO dbo.DEMO_DB_PK VALUES (@i, CASE ROUND(RAND() * 10, 0) WHEN 1 THEN 'Marc' WHEN 2 THEN 'Bill' WHEN 3 THEN 'George' WHEN 4 THEN 'Eliot' WHEN 5 THEN 'Matt' WHEN 6 THEN 'Trey' ELSE'Tracy' END, RAND() * 10000);
SET @i += 1;
END
GO
create procedure [dbo].[sp_demo_insert_demo_hk_sch_data]
AS
SET NOCOUNT ON;
DECLARE @i INT = 1;
WHILE @i <= 1000000
BEGIN
INSERT INTO dbo.DEMO_HK_SCH_DATA VALUES (@i, CASE ROUND(RAND() * 10, 0) WHEN 1 THEN 'Marc'WHEN 2 THEN 'Bill' WHEN 3 THEN 'George' WHEN 4 THEN 'Eliot' WHEN 5 THEN 'Matt' WHEN 6 THEN 'Trey'ELSE 'Tracy' END, RAND() * 10000);
SET @i += 1;
END
GO
CREATE PROCEDURE [dbo].[sp_demo_insert_demo_hk_sch]
AS
SET NOCOUNT ON;
DECLARE @i INT = 1;
WHILE @i <= 1000000
BEGIN
INSERT INTO dbo.DEMO_HK_SCH VALUES (@i, CASE ROUND(RAND() * 10, 0) WHEN 1 THEN 'Marc' WHEN 2 THEN 'Bill' WHEN 3 THEN 'George' WHEN 4 THEN 'Eliot' WHEN 5 THEN 'Matt' WHEN 6 THEN 'Trey' ELSE'Tracy' END, RAND() * 10000);
SET @i += 1;
END
GO
Note that for the following natively compiled stored procedures, I rewrote one portion of code because it concerns CASE statement which is not supported with SQL Server 2014.
create procedure [dbo].[sp_demo_insert_demo_hk_sch_data_cp]
with native_compilation, schemabinding, execute as owner
as
begin atomic with ( transaction isolation level=snapshot, language=N'us_english')
DECLARE @i INT = 1;
DECLARE @test_case INT = RAND() * 10;
DECLARE @name VARCHAR(20);
IF @test_case = 1
SET @name = 'Marc'
ELSE IF @test_case = 2
SET @name = 'Bill'
ELSE IF @test_case = 3
SET @name = 'George'
ELSE IF @test_case = 4
SET @name = 'Eliot'
ELSE IF @test_case = 5
SET @name = 'Matt'
ELSE IF @test_case = 6
SET @name = 'Trey'
ELSE
SET @name = 'Tracy';
WHILE @i <= 1000000
BEGIN
INSERT INTO [dbo].[DEMO_HK_SCH_DATA] VALUES (@i, @name, RAND() * 10000);
SET @i += 1;
END
End
go
create procedure [dbo].[sp_demo_insert_demo_hk_sch_cp]
with native_compilation, schemabinding, execute as owner
as
begin atomic with ( transaction isolation level=snapshot, language=N'us_english')
DECLARE @i INT = 1;
DECLARE @test_case INT = RAND() * 10;
DECLARE @name VARCHAR(20);
IF @test_case = 1
SET @name = 'Marc'
ELSE IF @test_case = 2
SET @name = 'Bill'
ELSE IF @test_case = 3
SET @name = 'George'
ELSE IF @test_case = 4
SET @name = 'Eliot'
ELSE IF @test_case = 5
SET @name = 'Matt'
ELSE IF @test_case = 6
SET @name = 'Trey'
ELSE
SET @name = 'Tracy';
WHILE @i <= 1000000
BEGIN
INSERT INTO [dbo].[DEMO_HK_SCH] VALUES (@i, @name, RAND() * 10000);
SET @i += 1;
END
end
go
create procedure [dbo].[sp_demo_insert_demo_hk_sch_data_cp_d]
with native_compilation, schemabinding, execute as owner
as
begin atomic with ( transaction isolation level=snapshot, language=N'us_english',delayed_durability = on)
DECLARE @i INT = 1;
DECLARE @test_case INT = RAND() * 10;
DECLARE @name VARCHAR(20);
IF @test_case = 1
SET @name = 'Marc'
ELSE IF @test_case = 2
SET @name = 'Bill'
ELSE IF @test_case = 3
SET @name = 'George'
ELSE IF @test_case = 4
SET @name = 'Eliot'
ELSE IF @test_case = 5
SET @name = 'Matt'
ELSE IF @test_case = 6
SET @name = 'Trey'
ELSE
SET @name = 'Tracy';
WHILE @i <= 1000000
BEGIN
INSERT INTO [dbo].[DEMO_HK_SCH_DATA] VALUES (@i, @name, RAND() * 10000);
SET @i += 1;
END
end
GO
Ok it’s time to run the different test scenarios. You will see below the different results and their related wait statistics that I found on my environment:

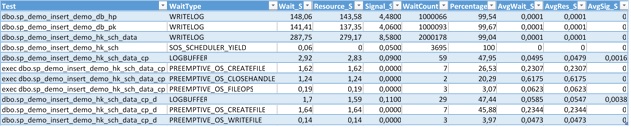
First of all, let’s notice that using In-Memory optimized tables in INTEROP mode seems to not improve the overall performance in all cases. Indeed, we still deal with the pretty same duration and the same CPU time as well when writing to the transaction log and checkpoint files for the In-Memory optimized tables with data persisted on disk – SCHEMA_AND_DATA.
Next, using In-Memory tables with only schema persisted on disk – SCHEMA_ONLY – contributes to better results (performance gain x 2) as we may expect. Indeed, the WRITELOG wait type has completely disappeared because data are not persisted in this case, so we minimize considerably the amount of records inside the Tlog.
Finally let’s have a look at the tests concerning natively compiled stored procedures. If we refer to the first tests (either for disk-based tables or for INTEROP), we can see that we reduce drastically the CPU consumption by using natively compiled stored procedures (roughly 97% in the best case). So, inserting 1M rows is very fast in this case.
Moreover, if we focus only on the results only between In-Memory optimized tables with different durability (SCHEMA_AND_DATA and SCHEMA_ONLY), we may notice that using transaction delayed durability may help. Once again persisting data by writing into the TLog and checkpoint files seems to slow down the insert process.
Some wait types still remain as PREEMPTIVE_OS_CREATEFILE, PREEMPTIVE_OS_CLOSEHANDLE and PREEMPTIVE_IS_FILEOPS and I will probably focus on them later. At this point, I would suspect a misconfigured storage or maybe my Hyper-V settings but I have to verify this point. I already double checked that I enabled instant file initialization according to the Microsoft documentation and disabled also some others features like 8.3 names, file indexing and last modification date tracking as well. So I will come back soon when I have more information.
But anyway for the moment we get a new time reference here: 2’’59’ for disk-based tables against 778 ms for In-Memory optimized tables + natively compiled stored procedures in the best scenario that tends to state that with In-Memory optimized we may get a huge performance improvement depending on our scenario.
So stay connected and see you soon for the next story!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/NME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/STS_web-min-scaled.jpg)