During my audits at customer places, it still happens very often to find SQL Server databases with page verification option configured to “none”. I always alert my customers on this configuration point because it can have an impact on the overall integrity of their databases. One of my customer told me that the integrity task of its maintenance will detect the corruption anyway and alert him by email – but is it really the case?
Of course, my response to the customer is that it depends of the corruption type and that a dbcc checkdb is not an absolute guarantee in this case. I like to show this example to my customers to convince them to change the page verify option to another thing than “none”.
Let me show this to you:
At this point we have two tables named t1 and t2. Table t2 has a foreign key constraint on the id column that references the table t1 on the column with the same name.
Now let’s corrupt a data page in the clustered index on the table t1. First, we will find the first data page in the clustered index of the table t1:
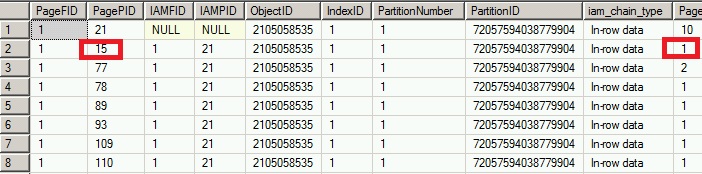
Then we will find the first row. The first row is stored in slot 0 which is located at offset 0x060.
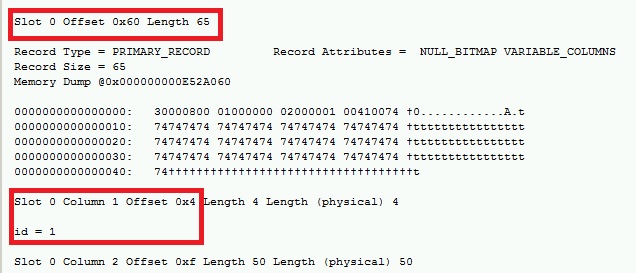
Now it’s time to corrupt the id column (id = 1) located to the offset 0x4 in the row. That means we have to place to the offset 0x60 + 0x4 to corrupt this column.
We will use the DBCC WRITEPAGE undocumented command to corrupt our page (again, a big thanks to Paul Randal for showing us how to use this command for testing purposes).
Now if we take a look at the page id=15, we notice that the id column value is now changed from 1 to 0.
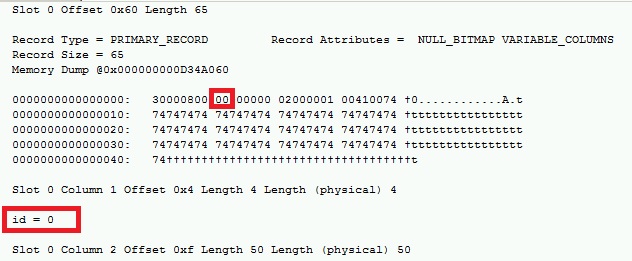
Ok, let’s run a DBCC CHECKDB command:

As you can see, the dbcc checkdb command does not detect any corruption! Now, let’s run the following statements:
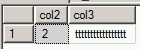
Do you notice that reading the corrupted page does not trigger an error in this case?
![]()
As you can notice, adding the t1.col1 column to the query will give it a different result between the both queries. Strange behavior isn’t it? In fact, the two queries above don’t use the same execution plan as the following below:
Query 1:

Query 2:
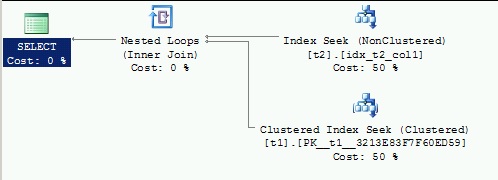
In the query 1, due to the foreign key constraint, the query execution engine doesn’t need to join t2 to t1 to retrieve data because we need only data already covered by the idx_t2_col1 index on table t2. However the story is not the same with the query 2. Indeed, we want to retrieve an additional value provided by the col1 column from the table t1. In this case SQL Server has to join t1 and t2 because the covered index idx_t2_col1 cannot provide all the data we need. But remember we had corrupt the id column of the primary key of the table t1 by changing the value from 1 to 0. This is why the query 2 doesn’t display any results.
The main question here is: why dbcc checkdb doesn’t detect the corruption? Well, in this case corruption has occurring directly on the data value and dbcc checkdb doesn’t have a verification mechanism to detect a corruption issue. Having a checksum value stored in the page would help dbcc checkdb operation in this case because it could compare a computed checksum while reading the page with the stored checksum stored on it.
Below the output provided by dbcc checkdb command if checksum page verify option was enabled for the database …
![]()
… or when we ran the query used earlier:

My conclusion:
Do not hesitate to change your page verify option value when it is configured to “none”.
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)