Today is the second day of the Alfresco DevCon 2018 and therefore yes, it is already over, unfortunately. In this blog, I will be continuing my previous one with sessions I attended on the afternoon of the day-1 as well as day-2. There were too many interesting sessions and I don’t really have the time to talk about all of them… But if you are interested, all the sessions were recorded (as always) so wait a little bit and check out the DevCon website, the Alfresco Community or the Alfresco Youtube channel and I’m sure you will find all the recordings as soon as they are available.
So on the afternoon of the day-1, I started with a presentation of Jeff Potts, you all know him, and he was talking about how to move in (upload) and out (download) of Alfresco some gigantic files (several gigabytes). He basically presented a use case where the users had to manage big files and put them all in Alfresco with the less headache possible. On the paper, Alfresco can handle any file no matter the size because the only limit is what the File System of the Alfresco Server supports. However, when you start working with 10 or 20 GB files, you can sometimes have issues like exceptions, timeouts, network outage, aso… It might not be frequent but it can happen for a variety of reasons (not always linked to Alfresco). The use case here was to simplify the import into Alfresco and make it faster. Jeff tested a lot of possible solutions like using the Desktop Sync, CMIS, FTP, the resumable upload share add-on, aso…
In the end, a pure simple (1 stream) upload/download will always be limited by the network. So he tried to work on improving this part and used the Resilio Sync software (formerly BitTorrent Sync). This tool can be used to stream a file to the Alfresco Server, BitTorrent style (P2P). But the main problem of this solution is that P2P is only as good as the number of users having this specific file available on their workstation… Depending on the use case, it might increase the performance but it wasn’t ideal.
In the end, Jeff came across the protocol “GridFTP”. This is an extension of the FTP for grid computing whose purpose is to make the file transfer more reliable and faster using multiple simultaneous TCP streams. There are several implementations of the GridFTP like the Globus Toolkit. Basically, the solution in this case was to use Globus to transfer the big files from the user’s workstation to a dedicated File System which is mounted on the Alfresco Server. Then using the Alfresco Bulk FileSystem Import Tool (BFSIT), it is really fast to import documents into Alfresco, as soon as they are on the File System of the Alfresco Server. For the download, it is just the opposite (using the BFSET)…
For files smaller than 512Mb, this solution is probably slower than the default Alfresco upload/download actions but for bigger files (or group of files), then it becomes very interesting. Jeff did some tests and basically for one or several files with a total size of 3 or 4GB, then the transfer using Globus and then the import into Alfresco was 50 to 60% faster than the Alfresco default upload/download.
Later, Jose Portillo shared Solr Sharding Best Practices. Sharding is the action of splitting your indexes into Shards (part of an index) to increase the searches and indexing (horizontal scaling). The Shards can be stored on a single Solr Server or they can be dispatched on several. Doing this basically increase the search speed because the search is executed on all Shards. For the indexing of a single node, there is no big difference but for a full reindex, it does increase a lot the performance because you do index several nodes at the same time on each Shards…
A single Shard can work well (according to the Alfresco Benchmark) with up to 50M documents. Therefore, using Shards is mainly for big repositories but it doesn’t mean that there are no use cases where it would be interesting for smaller repositories, there are! If you want to increase your search/index performance, then start creating Shards much earlier.
For the Solr Sharding, there are two registration options:
- Manual Sharding => You need to manually configure the IPs/Host where the Shards are located in the Alfresco properties files
- Dynamic Sharding => Easier to setup and Alfresco automatically provide information regarding the Shards on the Admin interface for easy management
There are several methods of Shardings which are summarized here:
- MOD_ACL_ID (ACL v1) => Sharding based on ACL. If all documents have the same ACL (same site for example), then they will all be on the same Shard, which might not be very useful…
- ACL_ID (ACL v2) => Same as v1 except that it uses the murmur hash of the ACL ID and not its modulus
- DB_ID (DB ID) => Default in Solr6. Nodes are evenly distributed on the Shards based on their DB ID
- DB_ID_RANGE (DB ID Range) => You can define the DB ID range for which nodes will go to which Shard (E.g.: 1 to 10M => Shard-0 / 10M to 20M => Shard-1 / aso…)
- DATE (Date and Time) => Assign date for each Shards based on the month. It is possible to group some months together and assign a group per Shard
- PROPERTY (Metadata) => The value of some property is hashed and this hash is used for the assignment to a Shard so all nodes with the same value are in the same Shard
- EXPLICIT_ID (Explicit) => This is an all-new method that isn’t yet on the documentation… It is apparently working similarly to the Metadata one but it’s not hashing the value of the property but using it directly/explicitly to know which shard should be used to index this document. If the property is missing or invalid, it should apparently fall back to the DB_ID method
Unfortunately, the Solr Sharding has only been available starting with Alfresco Content Services 5.1 (Solr 4) and only using the ACL v1 method. New methods were then added using the Alfresco Search Services (Solr 6). The availability of methods VS Alfresco/Solr versions has been summarized in Jose’s presentation:
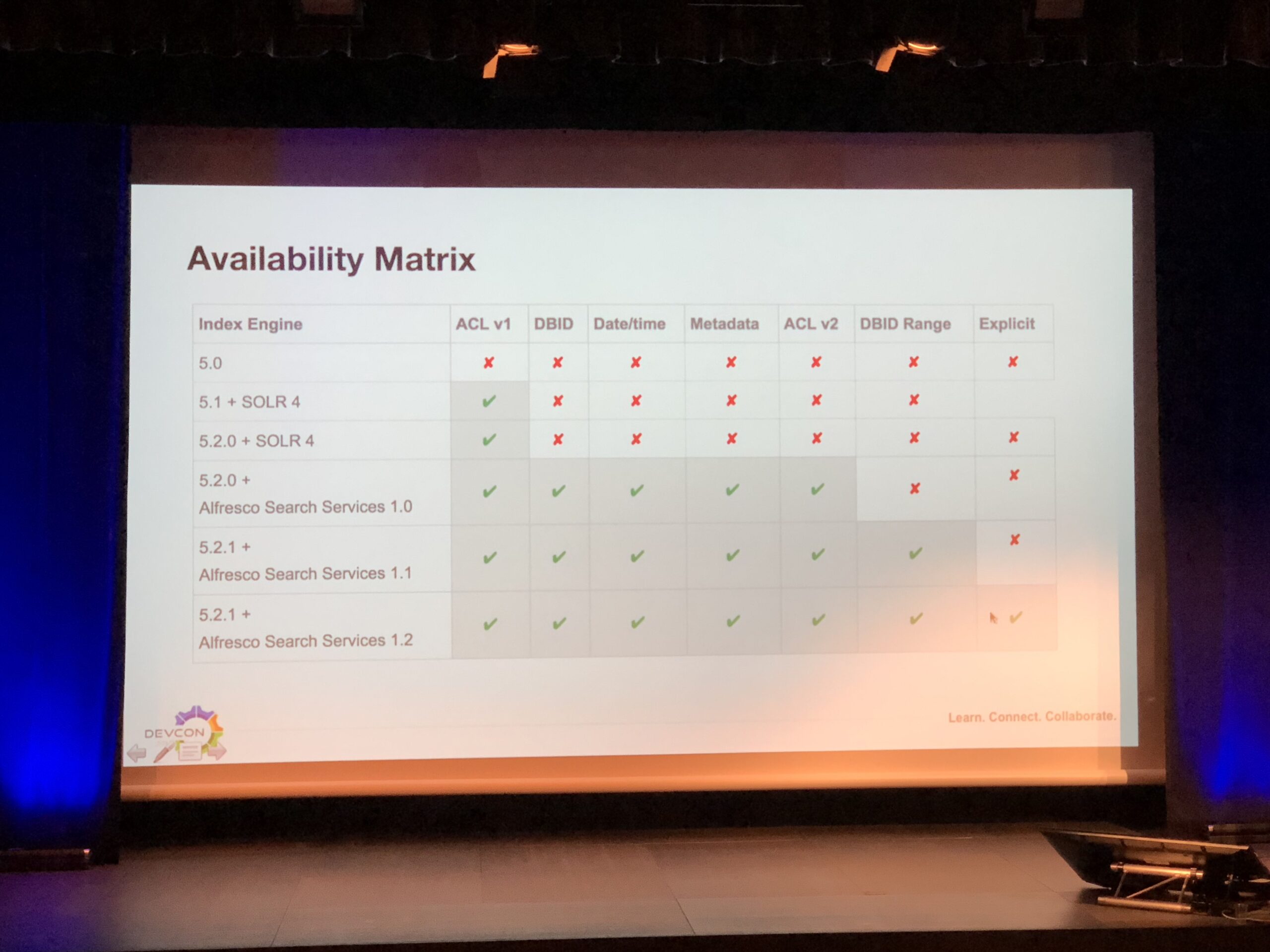
Jose also shared a comparison matrix of the different methods to choose the right one for each use case:

Some other best practices regarding the Solr Sharding:
- Replicate the Shards to increased response time and it also provides High Availability so… No reasons not to!
- Backup the Shards using the provided Web Service so Alfresco can do it for you for one or several Shards
- Use DB_ID_RANGE if you want to be able to add Shards without having to perform a full reindex, this is the only way
- If you need another method than DB_ID_RANGE, then plan carefully the number of Shards to be created. You might want to overshard to take into account the future growth
- Keep in mind that each Shard will pull the changes from Alfresco every 15s and it all goes to the DB… It might create some load there and therefore be sure that your DB can handle that
- As far as I know, at the moment, the Sharding does not support Solr in SSL. Solr should anyway be protected from external accesses because it is only used by Alfresco internally so this is an ugly point so far but it’s not too bad. Sharding is pretty new so it will probably support the SSL at some point in the future
- Tune properly Solr and don’t forget the Application Server request header size
- Solr4 => Tomcat => maxHttpHeaderSize=…
- Solr6 => Jetty => solr.jetty.request.header.size=…
The day-2 started with a session from John Newton which presented the impact of emerging technologies on content. As usual, John’s presentation had a funny theme incorporated in the slides and this time it was Star Wars.

After that, I attended the Hack-a-thon showcase, presented/introduced by Axel Faust. In the Alfresco world, Hack-a-thons are:
- There since 2012
- Open-minded and all about collaboration. Therefore, the output of any project is open source and available for the community. It’s not about money!
- Always the source of great add-ons and ideas
- 2 times per year
- During conferences (day-0)
- Virtual Hack-a-thon (36h ‘follow-the-sun’ principle)
A few of the 16 teams that participated in the Hack-a-thon presented the result of their Hack-a-thon day and there were really interesting results for ACS, ACS on AWS, APS, aso…
Except that, I also attended all lightning talks on this day-2 as well as presentations on PostgreSQL and Solr HA/Backup solutions and best practices. The presentations about PostgreSQL and Solr were interesting especially for newcomers because it really explained what should be done to have a highly available and resilient Alfresco environment.
There were too many lightning talk to mention them all but as always, there were some quite interesting and there I just need to mention the talk about the ContentCraft plugin (from Roy Wetherall). There cannot be an Alfresco event (be it a Virtual Hack-a-thon, BeeCon or DevCon now) without an Alfresco integration into Minecraft. Every year, Roy keeps adding new stuff into his plugin… I remember years ago, Roy was already able to create a building in Minecraft where the height represented the number of folders stored in Alfresco and the depth was the number of documents inside, if my memory is correct (this changed now, it represents the number of sub-folders). This year, Roy presented the new version and it’s even more incredible! Now if you are in front of one of the building’s door, you can see the name and creator of the folder in a ‘Minecraft sign’. Then you can walk in the building and there is a corridor. On both sides, there are rooms which represent the sub-folders. Again, there are ‘Minecraft signs’ there with the name and creator of the sub-folders. Until then, it’s just the same thing again so that’s cool but it will get even better!
If you walk in a room, you will see ‘Minecraft bookshelves’ and ‘Minecraft chests’. Bookshelves are just there for the decoration but if you open the chests, then you will see, represented by ‘Minecraft books’, all your Alfresco documents stored on this sub-folder! Then if you open a book, you will see the content of this Alfresco document! And even crazier, if you update the content of the book on Minecraft and save it, the document stored in Alfresco will reflect this change! This is way too funny :D.
It’s all done using CMIS so there is nothing magical… Yet it really makes you wonder if there are any limits to what Alfresco can do ;).
If I dare to say: long live Alfresco! And see you around again for the next DevCon.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/OLS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)