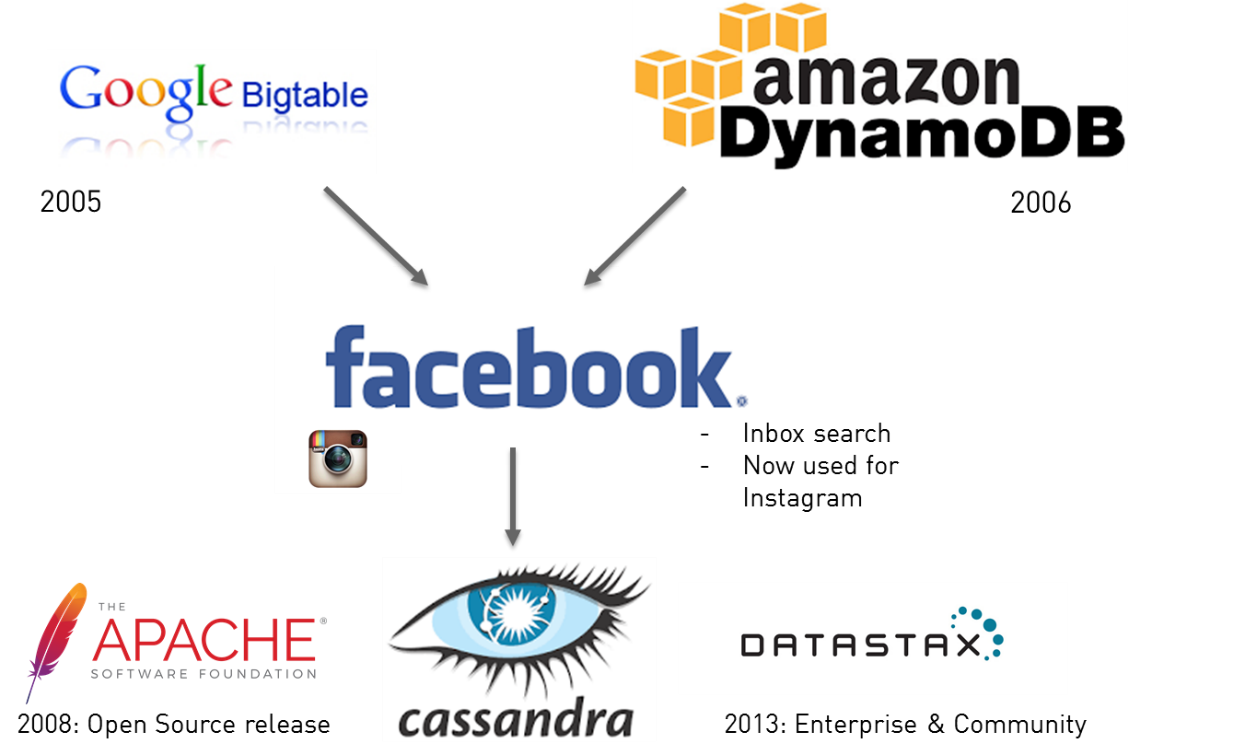
Apache Cassandra is one of the most popular NoSQL databases http://db-engines.com/en/ranking. It is used by many big companies as Facebook, Netflix and many others. Initially the project was initiated by Facebook. In combination with Google BigTable and Amazon DynamoDB, they developed Cassandra. Actually, Cassandra is developed and maintained by the Apache foundation for the community version and by DataStax for the enterprise and commercial versions.
Architecture
Cassandra has a master-less architecture. A cluster is represented as a ring. It’s a peer-to-peer cluster, with no single point of failure.
The Cassandra key features are:
- Distributed
- Decentralized
- Replicated
- Scalable
- Fault-tolerant
- Tunable consistency level
- No Single Point of Failure
- High Available
- Multi data center
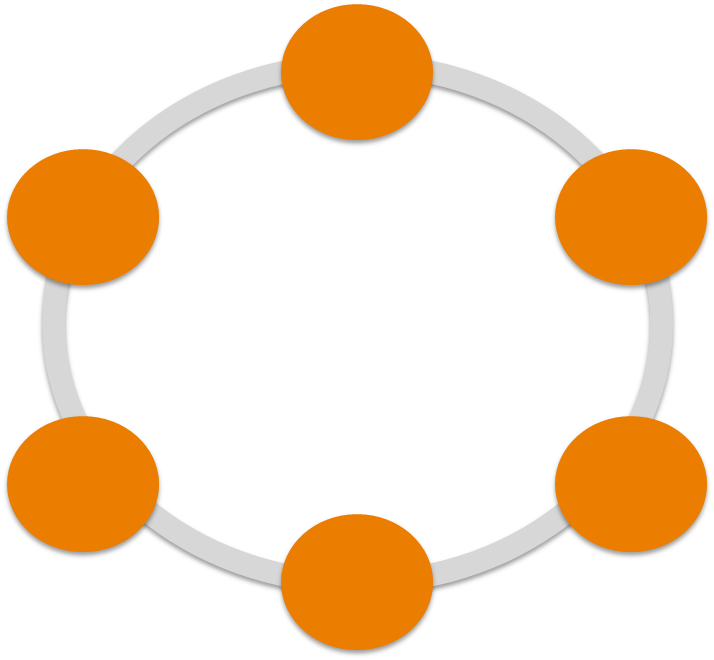
Any server node can accept write or read queries from clients. Every server is equal.
Cassandra uses the Gossip protocol for internode communication within the cluster. The Gossip protocol allows the exchanges of information between cluster nodes, such as the status. Each cluster node sends its status every second to three other nodes in the ring. A gossip message contain a version and in case of a conflict the older version is overwritten.
A Partitioned Row Store
Because C* is a NoSQL database, and in the “NoSQL world” no strict standards are defined, there is a lot of misunderstanding around the Cassandra data model. Currently, C* is defined as a column-store oriented DBMS, but there is a big confusion on this definition.
To define, the Cassandra data model you have to decompose it. The picture below will help you to understand the data objects composition.
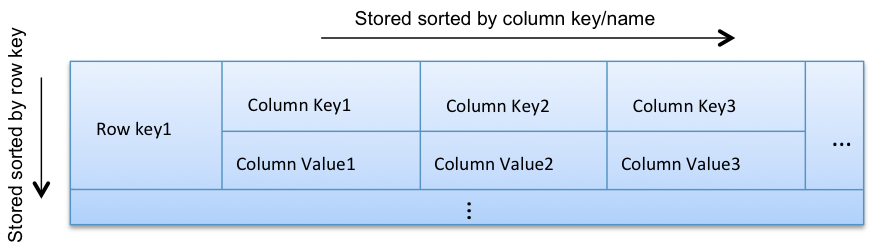
The Cassandra data model is organized into rows of multiple columns/values pairs. Each row is uniquely identifiable by a key, the Row Key. Rows group columns and super columns. A column is the most basic unit of the data model. All columns are sorted by column key name, and all row key are sorted by row keys.
Each row key, is stored into tables or column-family and both are encapsulated into Keyspaces. Below is a representation of the complete Cassandra data model.
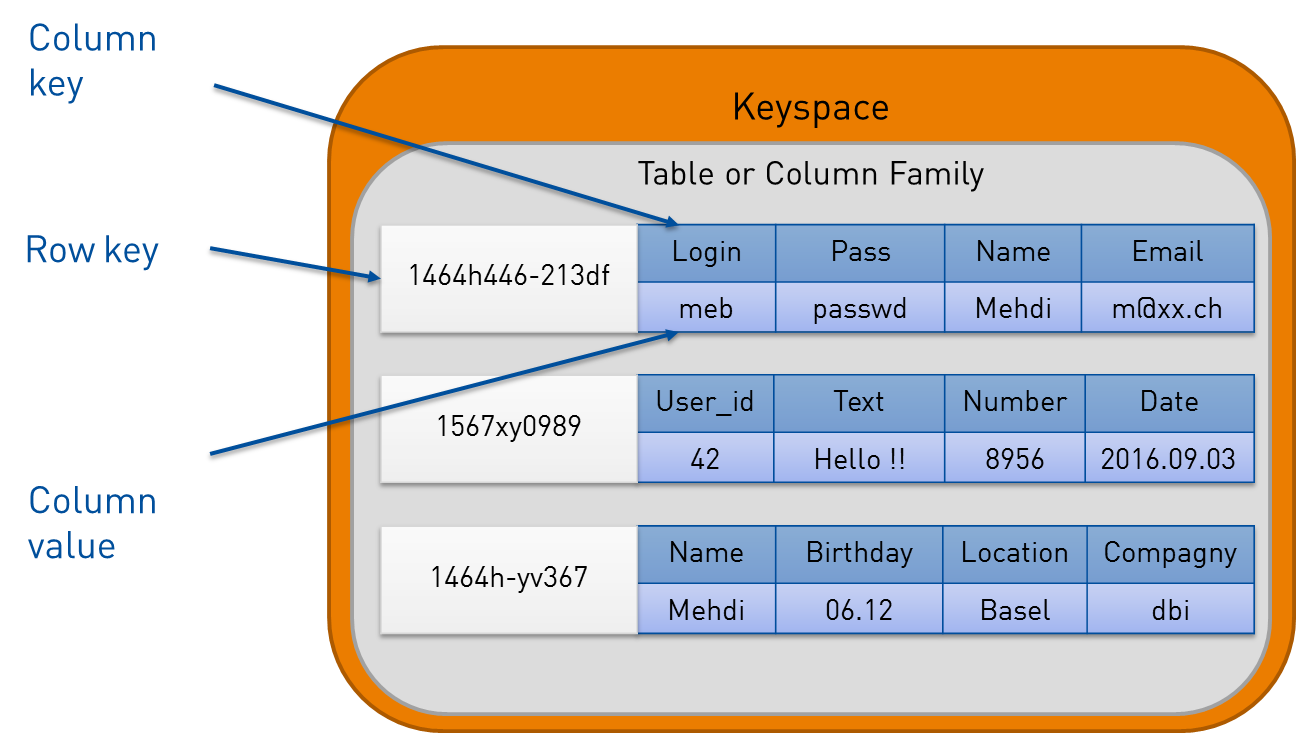
Finally, Apache C* can be defined as a Partitioned row store database.
How data is distributed
Cassandra uses a partitioner (internal component) to distribute data across cluster nodes. A partitioner determines where each piece of data has to be stored. The partitioning process is completely automatic and transparent.
Basically the partitioner is a hash function, computes a token for each partition key (Partition Key = Row Key). Depending on the partitioning strategy, each node of the cluster is responsible of a token. Below a picture for the partitioning process.
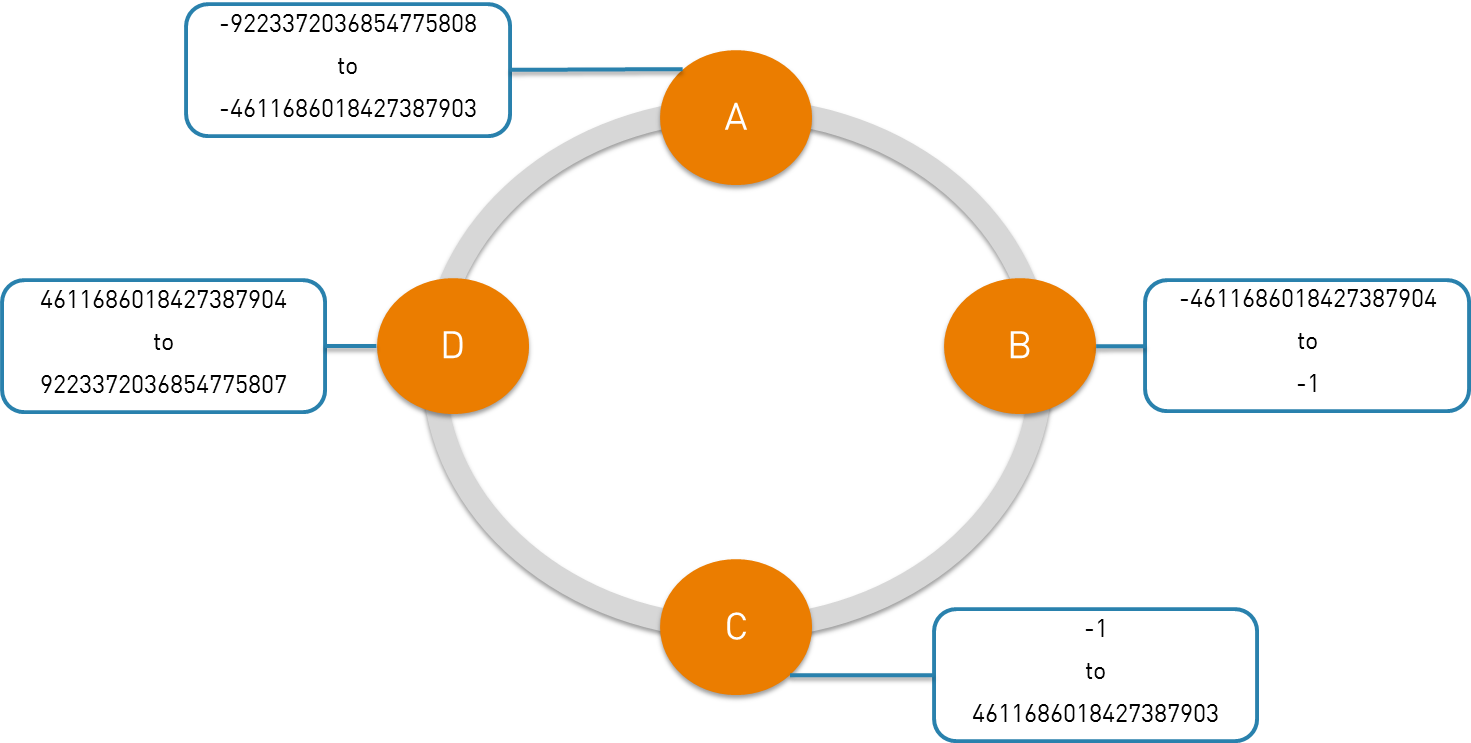
Three partitioning strategies are available:
- Murmur3Partitioner
- RandomPartitioner
- ByteOrderedPartitioner
Replication
Cassandra can store multiple copies of data on multiple nodes in order to ensure high availability and fault tolerance. Two important concepts are used for C* replication.
Replication strategy: determines in which node data is placed
Replication factor: determines the number of nodes where data is placed. A replication factor of 1 means that the data is replicated one time in one node.
The client connects to any node in the ring. This node became the coordinator, then the coordinator determines where the data must be stored. Finally, the data is replicated from one node to another in the sense of a clock hand.
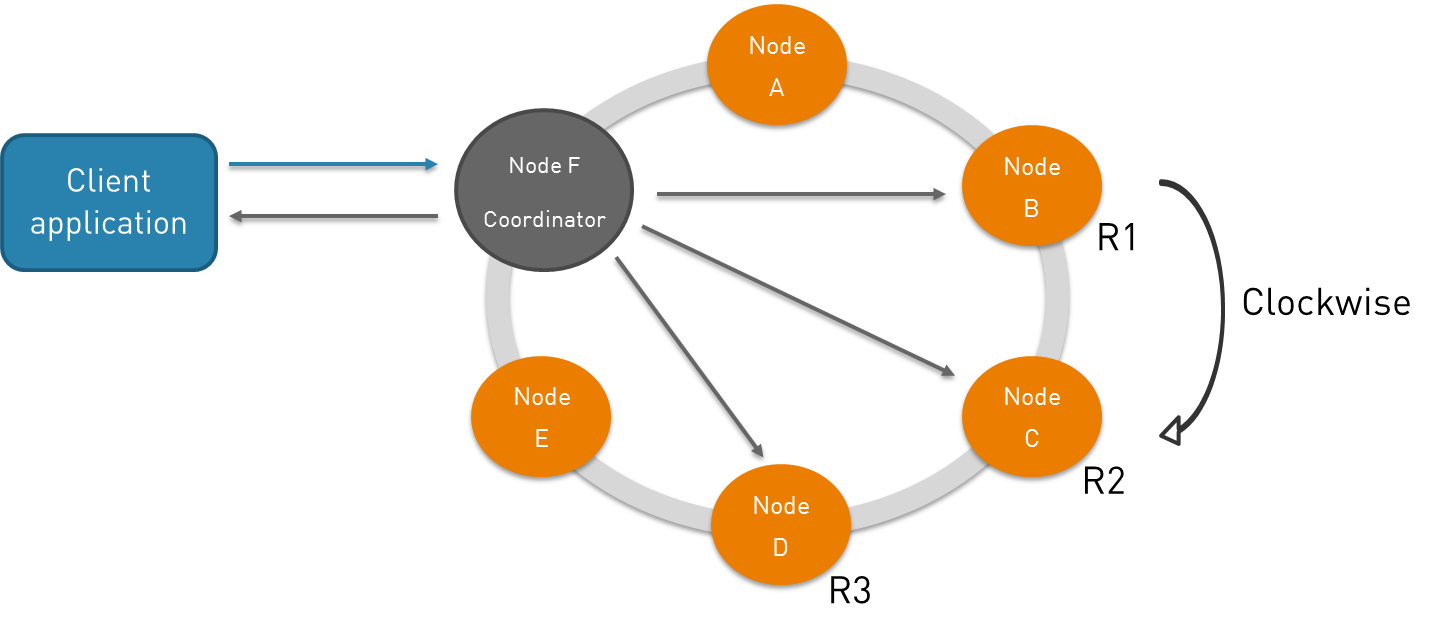
A quick overview of Cassandra main concepts has been done in this post in order to understand more precisely how Apache Cassandra works. Of course Cassandra concepts are more complex and will be described in future blog posts.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)