2 years ago, I proposed a ctypes-based Documentum extension for python, DctmAPI.py. While it did the job, it was quite basic. For example, its select2dict() function, as inferred from its name, returned the documents from a dql query into a list of dictionaries, one per document, all in memory. While this is OK for testing and demonstration purpose, it can potentially put some stress on the available memory; besides, do we really need to hold at once in memory a complete result set with several hundreds thousands rows ? It makes more sense to iterate and process the result row by row. For instance, databases have cursors for that purpose.
Another rudimentary demonstration function was select(). Like select2dict(), it executed a dql statement but output the result row by row to stdout without any special attempt at pretty printing it. The result was quite crude, yet OK for testing purposes.
So, after 2 years, I thought it was about time to revamp this interface and make it more practical. A new generator-based function, co_select(), has been introduced for a more efficient processing of the result set. select2dict() is still available for those cases where it is still handy to have a full result set in memory and the volume is manageable; actually, select2dict() is now down to 2 lines, the second one being a list comprehension around co_select() (see the listing below). select() has become select_to_stdout() and its output much enhanced; it can be json or tabular, with optional column-wrapping à la sql*plus and colorization as well, all stuff I mentioned several times in the past, e.g. here. Moreover, a pagination functionality has been added through the functions paginate() and paginate_to_stdout(). Finally, exceptions and message logging have been used liberally. As it can be seen, those are quite some improvements from the original version. Of course, there are so many way to implement them depending on the level of usability and performance that is looked for. Also, new functionalities, maybe unexpected ones as of this writing, can be felt necessary, so the current functions are only to be taken as examples.
Let’s see how the upgraded module looks like now.
Listing of DctmAPI.py
"""
This module is a python - Documentum binding based on ctypes;
requires libdmcl40.so/libdmcl.so to be reachable through LD_LIBRARY_PATH;
initial version, C. Cervini - dbi-services.com - May 2018
revised, C. Cervini - dbi-services.com - December 2020
The binding works as-is for both python2 amd python3; no recompilation required; that's the good thing with ctypes compared to e.g. distutils/SWIG;
Under a 32-bit O/S, it must use the libdmcl40.so, whereas under a 64-bit Linux it must use the java backed one, libdmcl.so;
For compatibility with python3 (where strings are now unicode ones and no longer arrays of bytes, ctypes strings parameters are always converted to unicode, either by prefixing them
with a b if litteral or by invoking their encode('ascii', 'ignore') method; to get back to text from bytes, b.decode() is used;these works in python2 as well as in python3 so the source is compatible with these two versions of the language;
Because of the use of f-strings formatting, python 3.5 minimum is required;
"""
import os
import ctypes
import sys, traceback
import json
# use foreign C library;
# use this library in eContent server < v6.x, 32-bit Linux;
dmlib = '/home/dmadmin/documentum53/libdmcl40.so'
dmlib = 'libdmcl40.so'
# use this library in eContent server >= v6.x, 64-bit Linux;
dmlib = 'libdmcl.so'
# used by ctypes;
dm = 0
# maximum cache size in rows;
# used while calling the paginate() function;
# set this according to the row size and the available memory;
# set it to 0 for unlimited memory;
MAX_CACHE_SIZE = 10000
# incremental log verbosity levels, i.e. include previous levels;
class LOG_LEVEL:
# no logging;
nolog = 0
# informative messages;
info = 1
# errors, i.e. exceptions messages and less;
error = 2
# debug, i.e. functions calls and less;
debug = 3
# current active level;
log_level = error
class dmException(Exception):
"""
generic, catch-all documentum exception;
"""
def __init__(self, origin = "", message = None):
super().__init__(message)
self.origin = origin
self.message = message
def __repr__(self):
return f"exception in {self.origin}: {self.message if self.message else ''}"
def show(level = LOG_LEVEL.error, mesg = "", beg_sep = "", end_sep = ""):
"""
displays the message msg if allowed
"""
if LOG_LEVEL.log_level > LOG_LEVEL.nolog and level <= LOG_LEVEL.log_level:
print(f"{beg_sep} {repr(mesg)} {end_sep}")
def dmInit():
"""
initializes the Documentum part;
returns True if successfull, False otherwise;
since they already have an implicit namespace through their dm prefix, dm.dmAPI* would be redundant so we define later dmAPI*() as wrappers around their respective dm.dmAPI*() functions;
returns True if no error, False otherwise;
"""
show(LOG_LEVEL.debug, "in dmInit()")
global dm
try:
dm = ctypes.cdll.LoadLibrary(dmlib); dm.restype = ctypes.c_char_p
show(LOG_LEVEL.debug, f"in dmInit(), dm= {str(dm)} after loading library {dmlib}")
dm.dmAPIInit.restype = ctypes.c_int;
dm.dmAPIDeInit.restype = ctypes.c_int;
dm.dmAPIGet.restype = ctypes.c_char_p; dm.dmAPIGet.argtypes = [ctypes.c_char_p]
dm.dmAPISet.restype = ctypes.c_int; dm.dmAPISet.argtypes = [ctypes.c_char_p, ctypes.c_char_p]
dm.dmAPIExec.restype = ctypes.c_int; dm.dmAPIExec.argtypes = [ctypes.c_char_p]
status = dm.dmAPIInit()
except Exception as e:
show(LOG_LEVEL.error, "exception in dmInit():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
else:
status = True
finally:
show(LOG_LEVEL.debug, "exiting dmInit()")
return status
def dmAPIDeInit():
"""
releases the memory structures in documentum's library;
returns True if no error, False otherwise;
"""
show(LOG_LEVEL.debug, "in dmAPIDeInit()")
try:
dm.dmAPIDeInit()
except Exception as e:
show(LOG_LEVEL.error, "exception in dmAPIDeInit():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
else:
status = True
finally:
show(LOG_LEVEL.debug, "exiting dmAPIDeInit()")
return status
def dmAPIGet(s):
"""
passes the string s to dmAPIGet() method;
returns a non-empty string if OK, None otherwise;
"""
show(LOG_LEVEL.debug, "in dmAPIGet()")
try:
value = dm.dmAPIGet(s.encode('ascii', 'ignore'))
except Exception as e:
show(LOG_LEVEL.error, "exception in dmAPIGet():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
else:
status = True
finally:
show(LOG_LEVEL.debug, "exiting dmAPIGet()")
return value.decode() if status and value is not None else None
def dmAPISet(s, value):
"""
passes the string s to dmAPISet() method;
returns TRUE if OK, False otherwise;
"""
show(LOG_LEVEL.debug, "in dmAPISet()")
try:
status = dm.dmAPISet(s.encode('ascii', 'ignore'), value.encode('ascii', 'ignore'))
except Exception as e:
show(LOG_LEVEL.error, "exception in dmAPISet():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
else:
status = True
finally:
show(LOG_LEVEL.debug, "exiting dmAPISet()")
return status
def dmAPIExec(stmt):
"""
passes the string s to dmAPIExec() method;
returns TRUE if OK, False otherwise;
"""
show(LOG_LEVEL.debug, "in dmAPIExec()")
try:
status = dm.dmAPIExec(stmt.encode('ascii', 'ignore'))
except Exception as e:
show(LOG_LEVEL.error, "exception in dmAPIExec():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
else:
# no error, status is passed through, to be converted to boolean below;
pass
finally:
show(LOG_LEVEL.debug, "exiting dmAPIExec()")
return True == status
def connect(docbase, user_name, password):
"""
connects to given docbase as user_name/password;
returns a session id if OK, None otherwise
"""
show(LOG_LEVEL.debug, "in connect(), docbase = " + docbase + ", user_name = " + user_name + ", password = " + password)
try:
session = dmAPIGet(f"connect,{docbase},{user_name},{password}")
if session is None:
raise dmException(origin = "connect()", message = f"unsuccessful connection to docbase {docbase} as user {user_name}")
except dmException as dme:
show(LOG_LEVEL.error, dme)
show(LOG_LEVEL.error, dmAPIGet(f"getmessage,{session}").rstrip())
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
session = None
else:
show(LOG_LEVEL.debug, f"successful session {session}")
# emptying the message stack in case some are left form previous calls;
while True:
msg = dmAPIGet(f"getmessage,{session}").rstrip()
if msg is None or not msg:
break
show(LOG_LEVEL.debug, msg)
finally:
show(LOG_LEVEL.debug, "exiting connect()")
return session
def execute(session, dql_stmt):
"""
execute non-SELECT DQL statements;
returns TRUE if OK, False otherwise;
"""
show(LOG_LEVEL.debug, f"in execute(), dql_stmt={dql_stmt}")
try:
query_id = dmAPIGet(f"query,{session},{dql_stmt}")
if query_id is None:
raise dmException(origin = "execute()", message = f"query {dql_stmt}")
err_flag = dmAPIExec(f"close,{session},{query_id}")
if not err_flag:
raise dmException(origin = "execute()", message = "close")
except dmException as dme:
show(LOG_LEVEL.error, dme)
show(LOG_LEVEL.error, dmAPIGet(f"getmessage,{session}").rstrip())
status = False
except Exception as e:
show(LOG_LEVEL.error, "exception in execute():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
else:
status = True
finally:
show(LOG_LEVEL.debug, "exiting execute()")
return status
def co_select(session, dql_stmt, numbering = False):
"""
a coroutine version of former select2dict;
the result set is returned of row at a time as a dictionary by a yield statement, e.g.:
{"attr-1": "value-1", "attr-2": "value-2", ... "attr-n": "value-n"}
in case of repeating attributes, value is an array of values, e.g.:
{ .... "attr-i": ["value-1", "value-2".... "value-n"], ....}
"""
show(LOG_LEVEL.debug, "in co_select(), dql_stmt=" + dql_stmt)
try:
query_id = dmAPIGet(f"query,{session},{dql_stmt}")
if query_id is None:
show(LOG_LEVEL.error, f'in co_select(), error in dmAPIGet("query,{session},{dql_stmt}")')
raise dmException(origin = "co_select", message = f"query {dql_stmt}")
# counts the number of returned rows in the result set;
row_counter = 0
# list of attributes returned by query;
# internal use only; the caller can compute it at will through the following expression: results[0].keys();
attr_names = []
# default number of rows to return at once;
# can be dynamically changed by the caller through send();
size = 1
# multiple rows are returned as an array of dictionaries;
results = []
# iterate through the result set;
while dmAPIExec(f"next,{session},{query_id}"):
result = {"counter" : f"{row_counter + 1}"} if numbering else {}
nb_attrs = dmAPIGet(f"count,{session},{query_id}")
if nb_attrs is None:
raise dmException(origin = "co_select", message = "count")
nb_attrs = int(nb_attrs)
for i in range(nb_attrs):
if 0 == row_counter:
# get the attributes' names only once for the whole query;
value = dmAPIGet(f"get,{session},{query_id},_names[{str(i)}]")
if value is None:
raise dmException(origin = "co_select", message = f"get ,_names[{str(i)}]")
attr_names.append(value)
is_repeating = dmAPIGet(f"repeating,{session},{query_id},{attr_names[i]}")
if is_repeating is None:
raise dmException(origin = "co_select", message = f"repeating {attr_names[i]}")
is_repeating = 1 == int(is_repeating)
if is_repeating:
# multi-valued attributes;
result[attr_names[i]] = []
count = dmAPIGet(f"values,{session},{query_id},{attr_names[i]}")
if count is None:
raise dmException(origin = "co_select", message = f"values {attr_names[i]}")
count = int(count)
for j in range(count):
value = dmAPIGet(f"get,{session},{query_id},{attr_names[i]}[{j}]")
if value is None:
value = "null"
result[attr_names[i]].append(value)
else:
# mono-valued attributes;
value = dmAPIGet(f"get,{session},{query_id},{attr_names[i]}")
if value is None:
value = "null"
result[attr_names[i]] = value
row_counter += 1
results.append(result)
size -= 1
if size > 0:
# a grouping has been requested;
continue
while True:
# keeps returning the same results until the group size is non-negative;
# default size value if omitted is 1, so next(r) keeps working;
# if the size is 0, abort the result set;
size = yield results
if size is None:
# default value is 1;
size = 1
break
if size >= 0:
# OK if size is positive or 0;
break
results = []
if 0 == size: break
err_flag = dmAPIExec(f"close,{session},{query_id}")
if not err_flag:
raise dmException(origin = "co_select", message = "close")
# if here, it means that the full result set has been read;
# the finally clause will return the residual (i.e. out of the yield statement above) rows;
except dmException as dme:
show(LOG_LEVEL.error, dme)
show(LOG_LEVEL.error, dmAPIGet(f"getmessage,{session}").rstrip())
except Exception as e:
show(LOG_LEVEL.error, "exception in co_select():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
finally:
# close the collection;
try:
show(LOG_LEVEL.debug, "exiting co_select()")
dmAPIExec(f"close,{session},{query_id}")
except Exception as e:
pass
return results
# for some unknown reason, an exception is raised on returning ...;
# let the caller handle it;
def select_to_dict(session, dql_stmt, numbering = False):
"""
new version of the former select2dict();
execute in session session the DQL SELECT statement passed in dql_stmt and return the result set into an array of dictionaries;
as the whole result set will be held in memory, be sure it is really necessary and rather use the more efficient co_select();
"""
result = co_select(session, dql_stmt, numbering)
return [row for row in result]
def result_to_stdout(result, format = "table", column_width = 20, mode = "wrap", frame = True, fg_color = "BLACK", bg_color = "white", alt_period = 5, col_mode = 2, numbering = False):
"""
print the list of dictionaries result into a table with column_width-wide columns and optional wrap-around and frame;
result can be a generator from co_select() or an array of dictionaries;
the output is like from idql only more readable with column wrap-around if values are too wide;
if frame is True, a frame identical to the one from mysql/postgresql is drawn around the table;
in order to increase readability, rows can be colorized by specifying a foreground and a background colors;
alt_period is the number of rows to print in fg_color/bg_color before changing to bg_color/fg_color;
if col_mode is:
0: no colorization is applied;
1: text color alternates between fg/bg and bg/fg every alt_period row blocks;
2: alt_period row blocks are colorized 1st line fg/bg and the rest bg/fg
color naming is different of termcolor's; we use the following convention which is later converted to termcolor's:
bright text colors (does not apply to background color) are identified by the uppercase strings: "BLACK", "RED", "GREEN", "YELLOW", "BLUE", "MAGENTA", "CYAN", "WHITE";
normal intensity colors are identified by the capitalized lowercase strings: "Black", "Red", "Green", "Yellow", "Blue", "Magenta", "Cyan", "White";
dim intensity colors are identified by the lowercase strings: "black", "red", "green", "yellow", "blue", "magenta", "cyan", "white";
if numbering is True and a tabular format is chosen, a column holding the row number is prependended to the table;
"""
# let's use the termcolor package wrapper around the ANSI color escape sequences;
from copy import deepcopy
from termcolor import colored, cprint
if fg_color[0].isupper() and fg_color[1:].islower():
# capitalized name: normal intensity;
fg_color = fg_color.lower()
attr = []
elif fg_color.islower():
# all lowercase name: dim intensity;
attr = ["dark"]
elif fg_color.isupper():
# all uppercase name: bright intensity;
attr = ["bold"]
fg_color = fg_color.lower()
else:
show(LOG_LEVEL.error, f"unsupported color {fg_color}; it must either be all uppercase or all lowercase or capitalized lowercase")
if bg_color.isupper():
bg_color = bg_color.lower()
elif not bg_color.islower():
show(LOG_LEVEL.error, f"unsupported color {bg_color}; it must either be all uppercase or all lowercase")
# remap black to termcolor's grey;
if "black" == fg_color:
fg_color = "grey"
if "black" == bg_color:
bg_color = "grey"
bg_color = "on_" + bg_color
color_current_block = 0
max_counter_digits = 7
def colorization(index):
nonlocal color_current_block, ind
if 0 == col_mode:
return "", "", []
elif 1 == col_mode:
#1: fg/bg every alt_period rows then switch to bg/fg for alt_period rows, then back again;
if 0 == index % alt_period:
color_current_block = (color_current_block + 1) % 2
return fg_color, bg_color, attr + ["reverse"] if 0 == color_current_block % 2 else attr
else:
#2: fg/bg as first line of every alt_period rows, then bg/fg;
return fg_color, bg_color, attr if 0 == index % alt_period else attr + ["reverse"]
def rows_to_stdout(rows, no_color = False):
"""
print the list of dictionaries in rows in tabular format using the parent function's parameters;
the first column hold the row number; we don't expect more than 10^max_counter_digits - 1 rows; if more and numbering is True, the table will look distorted, just increase max_counter_digits;
"""
btruncate = "truncate" == mode
ellipsis = "..."
for i, row in enumerate(rows):
# preserve the original data as they may be referenced elsewhere;
row = deepcopy(row)
# hack to keep history of printed rows...;
col_fg, col_bg, col_attr = colorization(max(ind,i)) if 0 != col_mode and not no_color else ("white", "on_grey", [])
while True:
left_over = ""
line = ""
nb_fields = len(row)
pos = 0
for k,v in row.items():
nb_fields -= 1
Min = max(column_width, len(ellipsis)) if btruncate else column_width
# extract the next piece of the column and pad it with blanks to fill the width if needed;
if isinstance(v, list):
# process repeating attributes;
columnS = "{: <{width}}".format(v[0][:Min] if v else "", width = column_width if not (0 == pos and numbering) else max_counter_digits)
restColumn = btruncate and v and len(v[0]) > Min
else:
columnS = "{: <{width}}".format(v[:Min], width = column_width if not (0 == pos and numbering) else max_counter_digits)
restColumn = btruncate and v and len(v) > Min
if restColumn:
columnS = columnS[ : len(columnS) - len(ellipsis)] + ellipsis
# cell content colored only vs. the whole line;
#line += ("| " if frame else "") + colored(columnS, col_fg, col_bg, col_attr) + (" " if frame else (" " if nb_fields > 0 else ""))
line += colored(("| " if frame else "") + columnS + (" " if frame or nb_fields > 0 else ""), col_fg, col_bg, col_attr)
if isinstance(v, list):
# process repeating attributes;
restS = v[0][Min : ] if v else ""
if restS:
v[0] = restS
elif v:
# next repeating value;
v.pop(0)
restS = v[0] if v else ""
else:
restS = v[Min : ]
row[k] = v[Min : ]
left_over += "{: <{width}}".format(restS, width = column_width if not (0 == pos and numbering) else max_counter_digits)
pos += 1
# cell content colored only vs. the whole line;
#print(line + ("|" if frame else ""))
print(line + colored("|" if frame else "", col_fg, col_bg, col_attr))
left_over = left_over.rstrip(" ")
if not left_over or btruncate:
break
def print_frame_line(nb_columns, column_width = 20):
line = ""
while nb_columns > 0:
line += "+" + "{:-<{width}}".format('', width = (column_width if not (1 == nb_columns and numbering) else max_counter_digits) + 2 + 2)
nb_columns -= 1
line += "+"
print(line)
return line
# result_to_stdout;
try:
if not format:
# no output is requested;
return
if "json" != format and "table" != format:
raise dmException(origin = "result_to_stdout", message = "format must be either json or table")
if "wrap" != mode and "truncate" != mode:
raise dmException(origin = "result_to_stdout", message = "invalid mode; mode must be either wrap or truncate")
if "json" == format:
for r in result:
print(json.dumps(r, indent = 3))
else:
for ind, r in enumerate(result):
# print the rows in result set or list one at a time;
if 0 == ind:
# print the column headers once;
# print the frame's top line;
frame_line = print_frame_line(len(r[0]), column_width)
rows_to_stdout([{k:k for k,v in r[0].items()}], no_color = True)
print(frame_line)
rows_to_stdout(r)
# print the frame's bottom line;
print(frame_line)
except dmException as dme:
show(LOG_LEVEL.error, dme)
def select_to_stdout(session, dql_stmt, format = "table", column_width = 20, mode = "wrap", frame = True, fg_color = "BLACK", bg_color = "white", alt_period = 5, col_mode = 2, numbering = False):
"""
execute in session session the DQL SELECT statement passed in dql_stmt and sends the properly formatted result to stdout;
if format == "json", json.dumps() is invoked for each document;
if format == "table", document is output in tabular format;
"""
result = co_select(session, dql_stmt, numbering)
result_to_stdout(result, format, column_width, mode, frame, fg_color, bg_color, alt_period, col_mode, numbering)
def paginate(cursor, initial_page_size, max_cache_size = MAX_CACHE_SIZE):
"""
Takes the generator cursor and returns a closure handle that allows to move forwards and backwards in the result set it is bound to;
a closure is used here so a context is preserved between calls (an alternate implementation could use a co-routine or a class);
returns None if the result set is empty;
rows are returned as an array of dictionaries;
i.e. if the page size (in rows) is negative, the cursor goes back that many rows, otherwise it moves forwards;
pages can be resized by passing a new page_size to the handle;
use a page size of 0 to close the cursor;
Usage:
cursor = co_select(session, dql_stmt)
handle = paginate(cursor, max_cache_size = 1000)
# paginate forwards 50 rows:
handle(50)
# paginate backwards 50 rows:
handle(-50)
# change page_size to 50 rows while moving forward 20 rows;
handle(20, 50)
# close cursor;
handle(0)
cursor.send(0)
the rows from the result set that have been fetched so far are kept in cache so that they can be returned when paginating back;
the cache is automatically extended when paginating forwards; it is never emptied so it can be heavy on memory if the result set is very large and the forwards pagination goes very far into it;
the cache has a settable max_cache_size limit with default MAX_CACHE_SIZE;
"""
cache = []
# current cache'size in rows;
cache_size = 0
# initialize current_page_size, it can change later;
current_page_size = initial_page_size
# index in cached result_set of first and last rows in page;
current_top = current_bottom = -1
# start the generator;
# one row will be in the cache before even starting paginating and this is taken into account later;
cache = next(cursor)
if cache:
current_top = current_bottom = 0
cache_size = 1
else:
return None
def move_window(increment, page_size = None):
nonlocal cache, cache_size, current_top, current_bottom, current_page_size
if page_size is None:
# work-around the default parameter value being fixed at definition time...
page_size = current_page_size
# save the new page size in case it has changed;
current_page_size = page_size
if increment > 0:
# forwards pagination;
if current_bottom + increment + 1 > cache_size:
# "page fault": must fetch the missing rows to complete the requested page size;
if current_bottom + increment > max_cache_size:
# the cache size limit has been reached;
# note that the above formula does not always reflect reality, i.e. if less rows are returned that asked for because the result set's end has been reached;
# in such cases, page_size will be adjusted to fit max_cache_size;
show(LOG_LEVEL.info, f"in cache_logic, maximum allowed cache size of {max_cache_size} reached")
increment = max_cache_size - current_bottom
delta = increment if cache_size > 1 else increment - 1 # because of the starting one row in cache;
cache += cursor.send(delta)
cache_size += delta # len(cache)
current_bottom += delta
else:
current_bottom += increment
current_top = max(0, current_bottom - page_size + 1)
return cache[current_top : current_bottom + 1]
elif increment < 0:
# backwards pagination;
increment = abs(increment)
current_top = max(0, current_top - increment)
current_bottom = min(cache_size, current_top + page_size) - 1
return cache[current_top : current_bottom + 1]
else:
# increment is 0: close the generator;
# must trap the strange exception after the send();
try:
cursor.send(0)
except:
pass
return None
return move_window
def paginate_to_stdout(session, dql_stmt, page_size = 20, format = "table", column_width = 20, mode = "wrap", frame = True, fg_color = "BLACK", bg_color = "white", alt_period = 5, col_mode = 2, numbering = False):
"""
execute the dql statement dql_stmt in session session and output the result set in json or table format; if a tabular format is chosen, page_size is the maximum number of rows displayed at once;
returns a handle to request the next pages or navigate backwards;
example of usage:
h = paginate_to_stdout(s, "select r_object_id, object_name, r_version_label from dm_document")
if h:
# start the generator;
next(h)
# navigate the result set;
# paginate forwards 10 rows;
h.send(10)
# paginate forwards 20 rows;
h.send(20)
# paginate backwards 15 rows;
h.send(-15)
# close the handle;
h.send(0)
"""
try:
q = co_select(session, dql_stmt, numbering)
if not q:
return None
handle = paginate(q, page_size)
while True:
values = yield handle
nb_rows = values[0] if isinstance(values, tuple) else values
new_page_size = values[1] if isinstance(values, tuple) and len(values) > 1 else None
if new_page_size:
page_size = new_page_size
if nb_rows is None:
# default value is 1;
nb_rows = 1
if 0 == nb_rows:
# exit request;
break
result_to_stdout([handle(nb_rows, page_size)], format, column_width, mode, frame, fg_color, bg_color, alt_period, col_mode, numbering)
except Exception as e:
show(LOG_LEVEL.error, e)
def describe(session, dm_type, is_type = True, format = "table", column_width = 20, mode = "wrap", frame = True, fg_color = "WHITE", bg_color = "BLACK", alt_period = 5, col_mode = 2):
"""
describe dm_type as a type if is_type is True, as a registered table otherwise;
optionally displays the output into a table or json if format is not None;
returns the output of api's describe verb or None if an error occured;
"""
show(LOG_LEVEL.debug, f"in describe(), dm_type={dm_type}")
try:
dump_str = dmAPIGet(f"describe,{session},{'type' if is_type else 'table'},{dm_type}")
if dump_str is None:
raise dmException(origin = "describe()", message = f"bad parameter {dm_type}")
s = [{"attribute": l[0], "type": l[1]} for l in [i.split() for i in dump_str.split("\n")[5:-1]]]
if format:
result_to_stdout([s], format, column_width, mode, frame, fg_color, bg_color, alt_period, col_mode)
except dmException as dme:
show(LOG_LEVEL.error, dme)
show(LOG_LEVEL.error, dmAPIGet(f"getmessage,{session}").rstrip())
finally:
show(LOG_LEVEL.debug, "exiting describe()")
return dump_str
def disconnect(session):
"""
closes the given session;
returns True if no error, False otherwise;
"""
show(LOG_LEVEL.debug, "in disconnect()")
try:
status = dmAPIExec("disconnect," + session)
except Exception as e:
show(LOG_LEVEL.error, "exception in disconnect():")
show(LOG_LEVEL.error, e)
if LOG_LEVEL.log_level > LOG_LEVEL.error: traceback.print_stack()
status = False
finally:
show(LOG_LEVEL.debug, "exiting disconnect()")
return status
# call module initialization;
dmInit()
Some comments
A few comments are in order. I´ll skip the ctypes part because it was already presented in the original blog.
On line 39, class LOG_LEVEL is being defined to encapsulate the verbosity levels, and the current one, of the error messages. Levels are inclusive of lesser ones; set LOG_LEVEL.log_level to LOG_LEVEL.no_log to turn off error messages. Default verbosity level is error, which means that only error messages are output, not debugging messages such as on function entry and exit.
On line 55, class dmException defines the custom exception used to raise Documentum errors, e.g. on lines 189 and 190. The linked-in C library libdmcl.so does not raise exceptions, their calls just return a TRUE or FALSE status (non-zero or zero value). The interface remaps those values to True or False, or sometimes None. Default exception Exception is still handled (e.g. on lines 83 and 92), more so for uniformity reason rather than out of real necessity, although it cannot be totally excluded that ctypes can raise some exception of it own under some circumstances. else and finally clauses are frequently used to remap the status or result value, return it, and cleaning up. Line 64 defines how the custom exception will be printed: it simply prints its instanciation parameters.
One line 235, function co_select() is defined. This is really the main function of the whole interface. Its purpose is to execute a SELECT DQL statement and return the rows on-demand, rather than into one potentially large in-memory list of dictionaries (reminder: pythons lists are respectively equivalent to arrays, and dictionaries to records or hashes, or associative arrays in other languages). On line 316, the yield statement makes this possible; it is this statement that turns a traditional, unsuspecting function into a generator or coroutine (this distinction is really python stuff, conceptually the function is a coroutine). Here, yield works both ways: it returns a row, which makes the function a generator, but can also optionally accept a number of rows to return at once, and 0 to stop the generator, which makes it a coroutine. On line 341, the exception handler´s finally clause closes the collection and, on line 348, returns the residual rows that were fetched but not returned yet because the end of the collection was reached and the yield statement was not executed.
One of the biggest pros of generators, in addition to saving memory, is to separate the navigation into the result set from the processing of the received data. Low-level, dirty technical details are therefore segregated into their own function out of the way of high-level data processing, resulting in a clearer and less distracting code.
Note the function’s numbering parameter: when True, returned rows are numbered starting at 1. It looks like this feature was not really necessary because a SELECT statement could just include a (pseudo-)column such as ROWNUM (for Oracle RDBMS) or a sequence, that would be treated as any other column but things are not so easy. Interfacing a sequence to a registered table, and resetting it before usage, is possible but quite complicated and needs to be done at the database level, which causes it to be not portable; besides, gaps in the sequence were observed, even when nocache was specified.
One line 352, the function select_to_dict() is defined for those cases where it still makes sense to hold a whole result set in memory at once. It does almost nothing, as the bulk of the work is done by co_select(). Line 359 executes a list comprehension that takes the generator returned by co_select() and forces it to be iterated until it meets its stop condition.
Skipping to line 519, function select_to_stdout() is another application of co_select(). This time, the received generator is passed to function result_to_stdout() defined on line 361; this function exemplifies outputting the data in a useful manner: it displays them to stdout either in json through the imported json library, or in tabular format. It can be used elsewhere each time such a presentation is sensible, e.g. from function describe() below, just make sure that the data are passed as a singleton list of a list of dictionaries (i.e. a list whose sole element is a list of dictionaries).
There isn’t much to add about the well-known json format (see an example below) but the tabular presentation is quite rich in functionalities. It implements in python what was presented here and here with the addition of color; the driving goal was to get a readable and comfortable table output containing documents as rows and their attributes as columns. Interactivity can be achieved by piping the output of the function into the less utility, as illustrated below:
$ pip install termcolor
$ export PYTHONPATH=/home/dmadmin/dctm-DctmAPI:/home/dmadmin/.local/lib/python3.5/site-packages
$ cat - < test-table.py
#!/usr/bin/python3.6
import DctmAPI
s = DctmAPI.connect("dmtest73", "dmadmin", "dmadmin")
DctmAPI.select_to_stdout(s, "select r_object_id, object_name, title, owner_name, subject, r_version_label from dm_document", format = "table", column_width = 30, mode = "wrap", frame = True, fg_color = "YELLOW", bg_color = "BLACK", alt_period = 5, col_mode = 2)
eot
$ chmod +x test-table.py
$ ./test-table.py | less -R
Result:
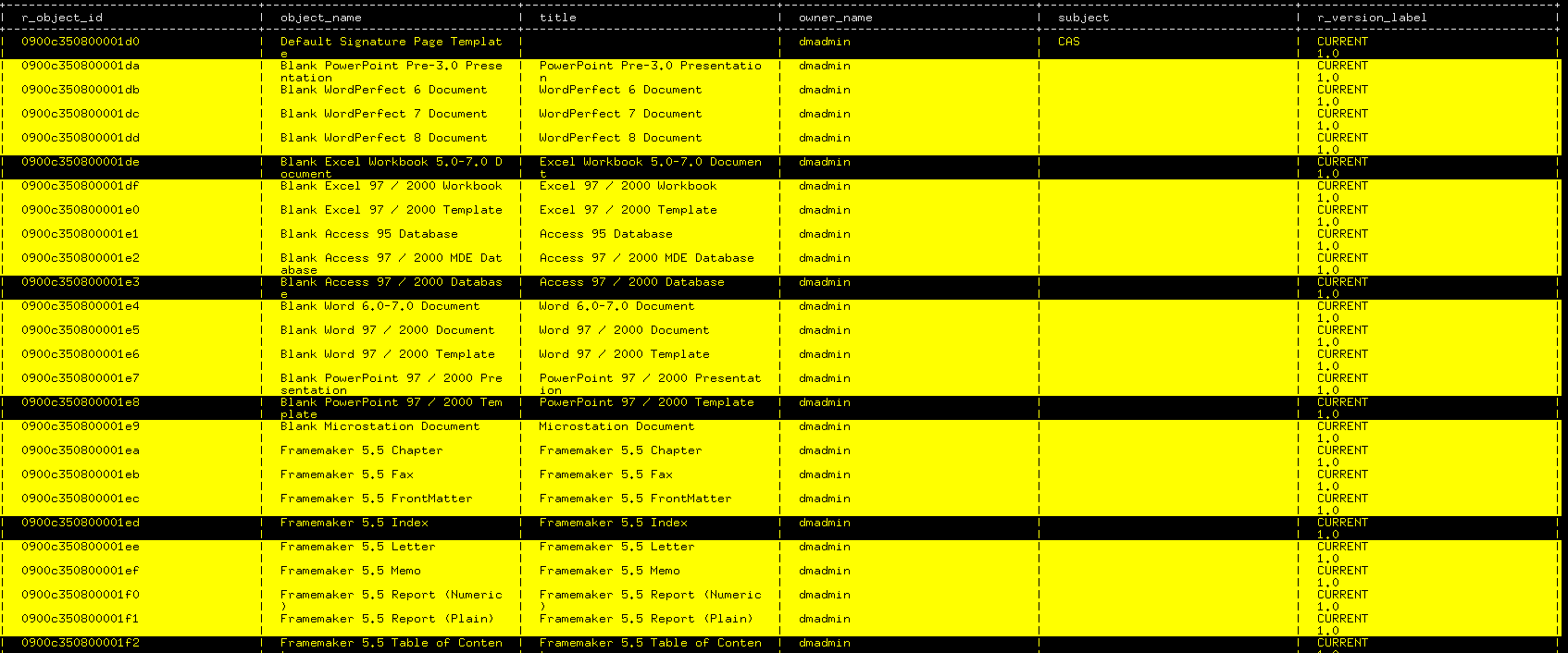
Here, a tabular (format = “table”, use format = “json” for json output) representation of the data returned by the DQL statement has been requested with 30 character-wide columns (column_width = 30); attributes too large to fit in their column are wrapped around; they could have been truncated by setting mode = “truncate”. A frame à la mysql or postgresql has been requested with frame = True. Rows colorization has been requested with the first line every 5 rows (alt_period = 5) in reverse color yellow on black and the others in black on yellow (col_mode = 2; use col_mode = 1 for alt_period lines large alternating colored fg/bg bg/fg blocks, and col_mode = 0 for no colorization).
The simple but very effective termcolor ANSI library is used here, which is a real relief compared to having to reimplement one myself for the 2nd or 3rd time in my life…
Note the use of the less command with the -R option so ANSI color escape sequences are passed through to the terminal and correctly rendered.
As a by-product, let’s generalize the snippet above into an independent, reusable utility:
$ cat test-table.py
#!/usr/bin/python3.6
import argparse
import DctmAPI
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--docbase', action='store',
default='dmtest73', type=str,
nargs='?',
help='repository name [default: dmtest73]')
parser.add_argument('-u', '--user_name', action='store',
default='dmadmin',
nargs='?',
help='user name [default: dmadmin]')
parser.add_argument('-p', '--password', action='store',
default='dmadmin',
nargs='?',
help='user password [default: "dmadmin"]')
parser.add_argument('-q', '--dql_stmt', action='store',
nargs='?',
help='DQL SELECT statement')
args = parser.parse_args()
session = DctmAPI.connect(args.docbase, args.user_name, args.password)
if session is None:
print(f"no session opened in docbase {args.docbase} as user {args.user_name}, exiting ...")
exit(1)
DctmAPI.select_to_stdout(session, args.dql_stmt, format = "table", column_width = 30, mode = "wrap", frame = True, fg_color = "YELLOW", bg_color = "BLACK", alt_period = 5, col_mode = 2)
# make it self-executable;
$ chmod +x test-table.py
# test it !
$ ./test-table.py -q "select r_object_id, object_name, title, owner_name, subject, r_version_label from dm_document" | less -R
# ship it !
# nah, kidding.
For completeness, here is an example of a json output:
s = DctmAPI.connect("dmtest73", "dmadmin", "dmadmin")
DctmAPI.select_to_stdout(s, "select r_object_id, object_name, r_version_label from dm_document", format = "json")
[
{
"r_object_id": "0900c350800001d0",
"object_name": "Default Signature Page Template",
"r_version_label": [
"CURRENT",
"1.0"
]
}
]
...
[
{
"r_object_id": "0900c350800001da",
"object_name": "Blank PowerPoint Pre-3.0 Presentation",
"r_version_label": [
"CURRENT",
"1.0"
]
}
]
Note the embedded list for the repeating attribute r_version_label; unlike relational tables, the json format suits perfectly well documents from repositories. It is not ready to support Documentum’s object-relational model but it is close enough. Maybe one day, once hell has frozen over -;), we’ll see a NOSQL implementation of Documentum, but I digress.
Back to the code, on line 528 function paginate() is defined. This function allows to navigate a result set forwards and backwards into a table; the latter is possible by caching (more exactly, saving, as the data are cumulative and never replaced), the rows received so far. As parameters, it takes a cursor for the opened collection, a page size and the maximum cache size. In order to preserve its context, e.g. the cache and the pointers to the first and last rows displayed from the result set, the function’s chosen implementation is that of a closure, with the inner function move_window() returned to the caller as a handle. Alternative implementations could be a class or a co-routine again. move_windows() requests the rows from the cursor via send(nb_rows) as previously explained and returns them as a list. A negative nb_rows means to navigate backwards, i.e. the requested rows are returned from the cache instead of the cursor. Obviously, as the cache is dynamically extended up to the specified size and its content never released to make room for the new rows, if one paginates to the bottom of a very large result set, a lot of memory can still be consumed because the whole result set finishes up in memory. A more conservative implementation could get rid of older rows to accomodate the new ones but at the cost of a reduced history depth, so it’s a trade-off; anyway, this subject is out of scope.
As its usage protocol may not by that simple at first, an example function paginate_to_stdout() is defined as a co-routine starting on line 613, with the same parameters as in select_to_stdout(). It can be used as follows:
# connect to the repository;
s = DctmAPI.connect("dmtest73", "dmadmin", "dmadmin")
# demonstration of DctmAPI.paginate_to_stdout();
# request a pagination handle to the result set returned for the SELECT dql query below;
h = DctmAPI.paginate_to_stdout(s, "select r_object_id, object_name, title, owner_name, subject, r_version_label from dm_document", page_size = 5, format = "table", column_width = 30, mode = "wrap", frame = True, fg_color = "RED", bg_color = "black", alt_period = 5, col_mode = 1, numbering = True)
print("starting the generator")
next(h)
nb_rows = 3
print(f"\nnext {nb_rows} rows")
h.send(nb_rows)
nb_rows = 10
print(f"\nnext {nb_rows} rows")
h.send(nb_rows)
nb_rows = 5
print(f"\nnext {nb_rows} rows and page_size incremented to 10")
h.send((nb_rows, 10))
nb_rows = 10
print(f"\nnext {nb_rows} row")
h.send(nb_rows)
nb_rows = -4
print(f"\nprevious {nb_rows} rows")
h.send(nb_rows)
nb_rows = 12
print(f"\nnext {nb_rows} rows and page_size decremented to 6")
h.send((nb_rows, 6))
nb_rows = -10
print(f"\nprevious {nb_rows} rows")
h.send(nb_rows)
print(f"exiting ...")
try:
h.send(0)
except:
# trap the StopIteration exception;
pass
sys.exit()
Here, each call to send() results in a table being displayed with the requested rows, as illustrated below:
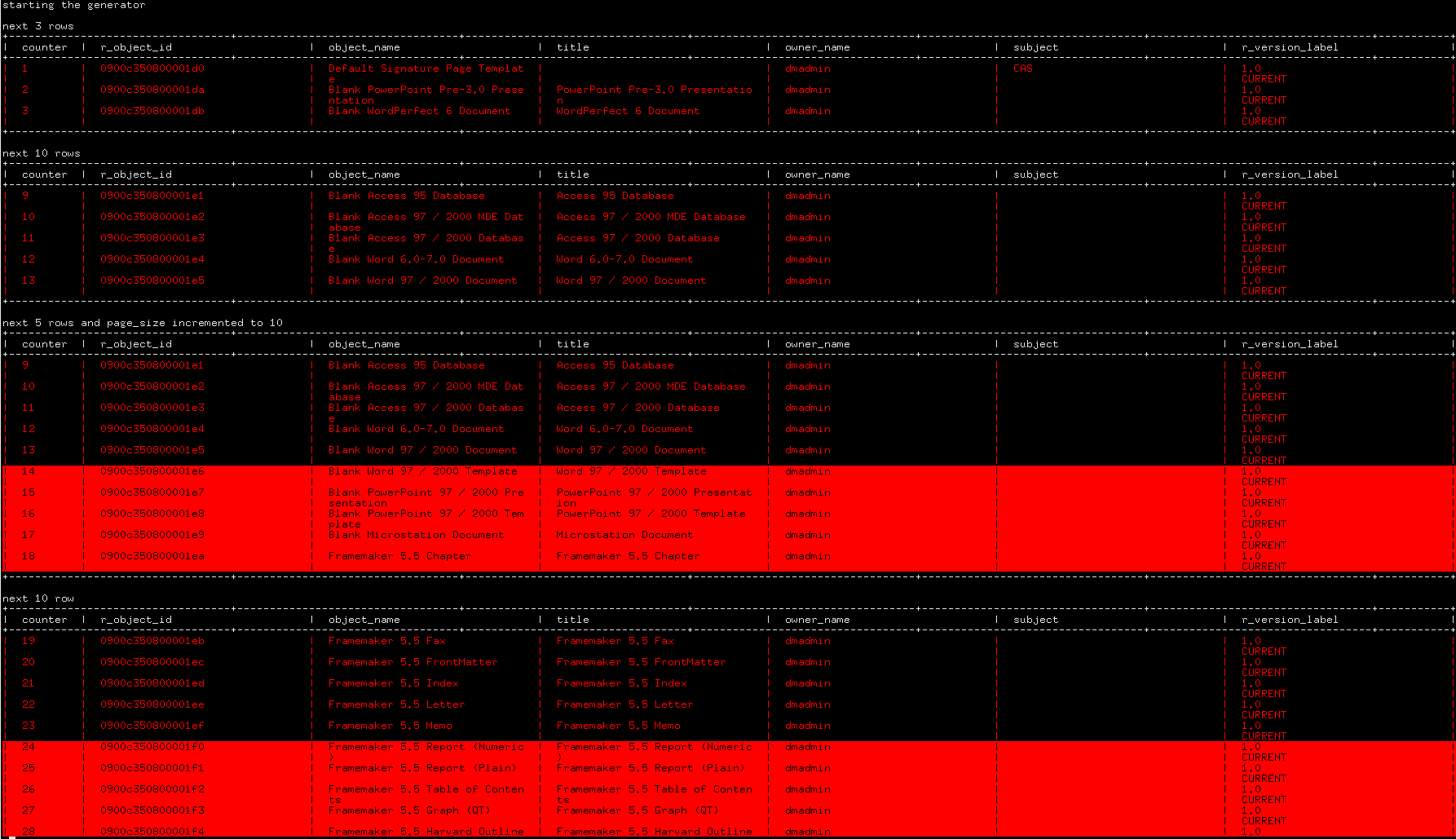
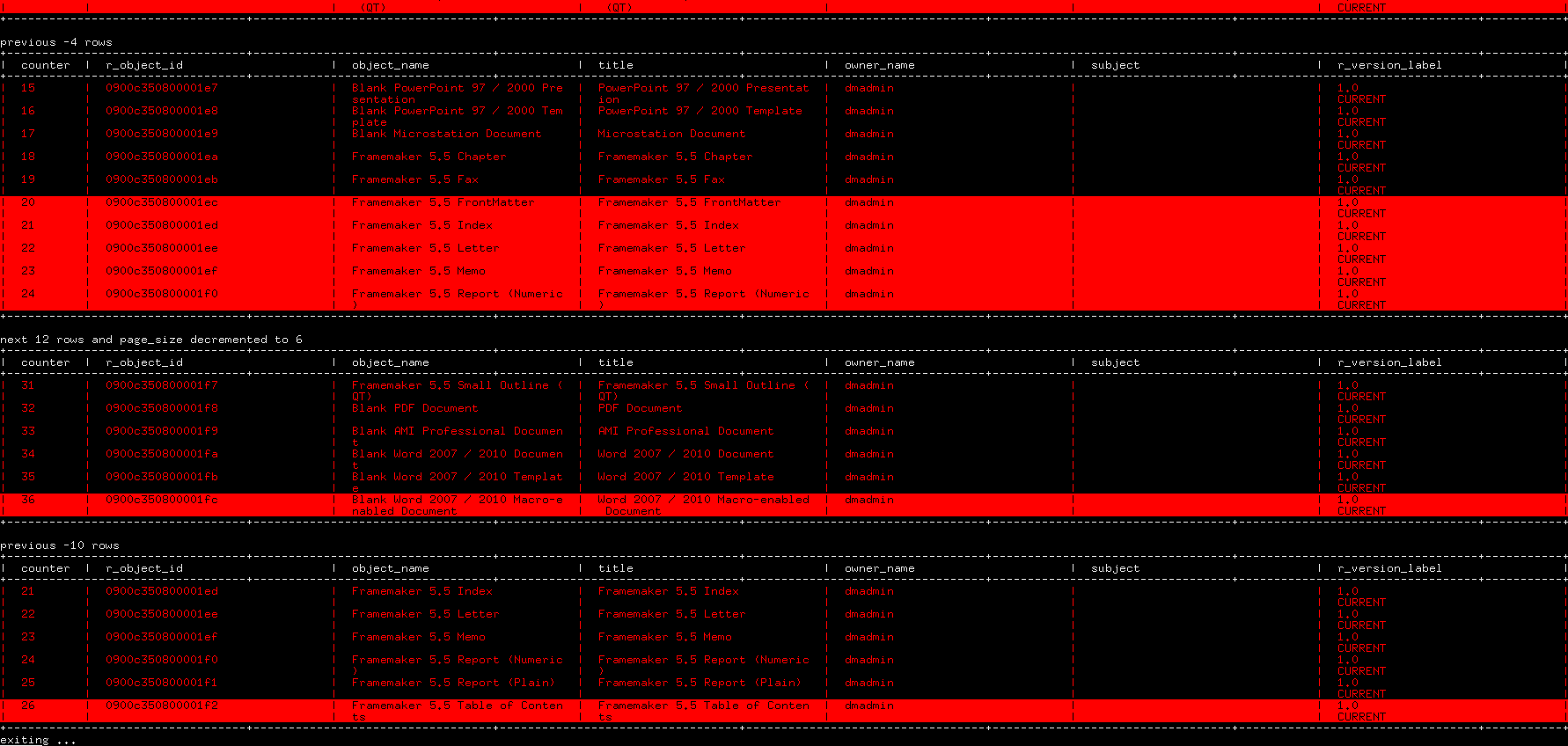
Note how send() takes either a scalar or a tuple as parameter; when the page size needs to be changed, a tuple including the new page size is passed to the closure which processes it to extract its values (line 640 and 641). It is a bit convoluted but it is a limitation of the send() function: as it takes only one parameter, they must be packed into a collection if they are more than one.
The snippet above could be generalized to a stand-alone interactive program that reads from the keyboard a number of rows as an offset to move backwards or forwards, if saving the whole result set into a disk file is too expensive and only a few pages are requested, but DQL has the limiting clause enable(return_top N) for this purpose. so such an utility is not really useful.
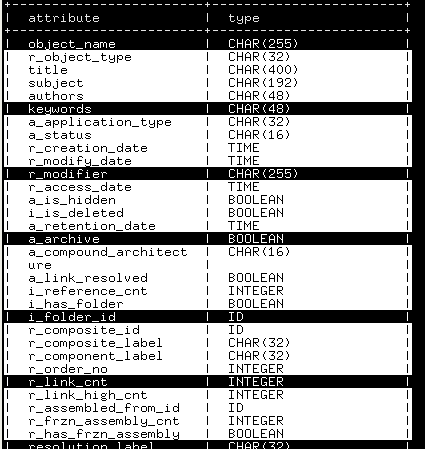
On line 654, the describe() function returns as-is the result of the eponymous api verb, i.e. as a raw string with each item delimited by an end of line character (‘\n’character under Linux) for further processing by the caller; optionally, it can also output it as a table or as a json literal by taking profit of the function result_to_stdout() and passing it the data that were appropriately formatted on line 667 as a list of one list of dictionaries.
Here are two examples of outputs.
s = DctmAPI.connect("dmtest73", "dmadmin", "dmadmin")
desc_str = DctmAPI.describe(s, "dm_document", format = "json")
# json format:

s = DctmAPI.connect("dmtest73", "dmadmin", "dmadmin")
desc_str = DctmAPI.describe(s, "dm_document")
# Tabular format:
Finally, on line 693, the module is automatically initialized at load time.
Conclusion
The python language has quite evolved from v2 to v3, the latest as of this writing being 3.9. Each version brings a few small, visible enhancements; an example of which are the formatting f’strings (no pun intended), which were used here. Unfortunately, they need python 3.6 minimum, which breaks compatibility with previous releases; fortunately, they can be easily replaced with older syntax alternatives if need be.
As usual, the DctmAPI does not pretend to be the best python interface to Documentum ever. It has been summarily tested and bugs could still be lurking around. I know, there are lots of improvements and functionalities possible, e.g. displaying acls and users and groups, maybe wrapping the module into classes, using more pythonic constructs, to name but a few. So, feel free to add your comments, corrections and suggestions below. They will all be taken into consideration and maybe implemented too if interesting enough. In the meantime, take care of yourself and your family. Happy New Year to everyone !
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/CEC_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/CVI_web-min-scaled.jpg)