By Franck Pachot
.
When you have 2 sites that are not too far you can build an extended cluster. You have one node on each site. And you can also use ASM normal redundancy to store data on each site (each diskgroup has a failure group for each site). Writes are multiplexed, so the latency between the two sites increases the write time. By default, reads can be done from one or the other site. But we can, and should, define that preference goes to local reads.
The setup is easy. In the ASM instance you list the failure groups that are on the same site, with the ‘asm_preferred_read_failure_groups’ parameter. You set that with an ALTER SYSTEM SCOPE=spfile SID=… because you will have different values for each instance. Of course, that supposes that you know the SID of the ASM instance that run on a specific site. If you are in Flex ASM, don’t ask. Wait 12.2 or read Bertrand Drouvot blog post
I’m on an extended cluster where the two sites have between 0.3 and 0.4 milliseconds of latency. I’m checking the storage with SLOB so this is the occasion to check how asm_preferred_read_failure_groups helps in I/O latency.
I use a simple SLOB configuration for physical I/O, read only, single block, and check the wait event histogram for ‘db file sequential read’.
Here is an example of output:
EVENT WAIT_TIME_MICRO WAIT_COUNT WAIT_TIME_FORMAT
------------------------------ --------------- ---------- ------------------------------
db file sequential read 1 0 1 microsecond
db file sequential read 2 0 2 microseconds
db file sequential read 4 0 4 microseconds
db file sequential read 8 0 8 microseconds
db file sequential read 16 0 16 microseconds
db file sequential read 32 0 32 microseconds
db file sequential read 64 0 64 microseconds
db file sequential read 128 0 128 microseconds
db file sequential read 256 538 256 microseconds
db file sequential read 512 5461 512 microseconds
db file sequential read 1024 2383 1 millisecond
db file sequential read 2048 123 2 milliseconds
db file sequential read 4096 148 4 milliseconds
db file sequential read 8192 682 8 milliseconds
db file sequential read 16384 3777 16 milliseconds
db file sequential read 32768 1977 32 milliseconds
db file sequential read 65536 454 65 milliseconds
db file sequential read 131072 68 131 milliseconds
db file sequential read 262144 6 262 milliseconds
It seems that half of the reads are served by the array cache and the other half are above disk latency time.
Now I set the asm_preferred_read_failure_groups to the remote site, to measure reads coming from there.
alter system set asm_preferred_read_failure_groups='DATA1_MIR.FAILGRP_SH' scope=memory;
and here is the result on similar workload:
EVENT WAIT_TIME_MICRO WAIT_COUNT WAIT_TIME_FORMAT
------------------------------ --------------- ---------- ------------------------------
db file sequential read 1 0 1 microsecond
db file sequential read 2 0 2 microseconds
db file sequential read 4 0 4 microseconds
db file sequential read 8 0 8 microseconds
db file sequential read 16 0 16 microseconds
db file sequential read 32 0 32 microseconds
db file sequential read 64 0 64 microseconds
db file sequential read 128 0 128 microseconds
db file sequential read 256 0 256 microseconds
db file sequential read 512 5425 512 microseconds
db file sequential read 1024 6165 1 millisecond
db file sequential read 2048 150 2 milliseconds
db file sequential read 4096 89 4 milliseconds
db file sequential read 8192 630 8 milliseconds
db file sequential read 16384 3598 16 milliseconds
db file sequential read 32768 1903 32 milliseconds
db file sequential read 65536 353 65 milliseconds
db file sequential read 131072 36 131 milliseconds
db file sequential read 262144 0 262 milliseconds
db file sequential read 524288 1 524 milliseconds
The pattern is similar except that I’ve nothing lower than 0.5 millisecond. I/Os served by the storage cache have there the additional latency of 0.3 milliseconds from the remote site. Of course, when we are above the millisecond, we don’t see the difference.
Now let’s set the right setting where preference should go to local reads:
alter system set asm_preferred_read_failure_groups='DATA1_MIR.FAILGRP_VE' scope=memory;
and the result:
EVENT WAIT_TIME_MICRO WAIT_COUNT WAIT_TIME_FORMAT
------------------------------ --------------- ---------- ------------------------------
db file sequential read 1 0 1 microsecond
db file sequential read 2 0 2 microseconds
db file sequential read 4 0 4 microseconds
db file sequential read 8 0 8 microseconds
db file sequential read 16 0 16 microseconds
db file sequential read 32 0 32 microseconds
db file sequential read 64 0 64 microseconds
db file sequential read 128 0 128 microseconds
db file sequential read 256 1165 256 microseconds
db file sequential read 512 9465 512 microseconds
db file sequential read 1024 519 1 millisecond
db file sequential read 2048 184 2 milliseconds
db file sequential read 4096 227 4 milliseconds
db file sequential read 8192 705 8 milliseconds
db file sequential read 16384 3350 16 milliseconds
db file sequential read 32768 1743 32 milliseconds
db file sequential read 65536 402 65 milliseconds
db file sequential read 131072 42 131 milliseconds
db file sequential read 262144 1 262 milliseconds
Here the fast reads are around 0.5 millisecond. And one thousand reads had a service time lower than 0.3 milliseconds, which was not possible when reading from the remote site.
Here is the pattern in in an Excel chart where you see no big difference for latency above 4 milliseconds.
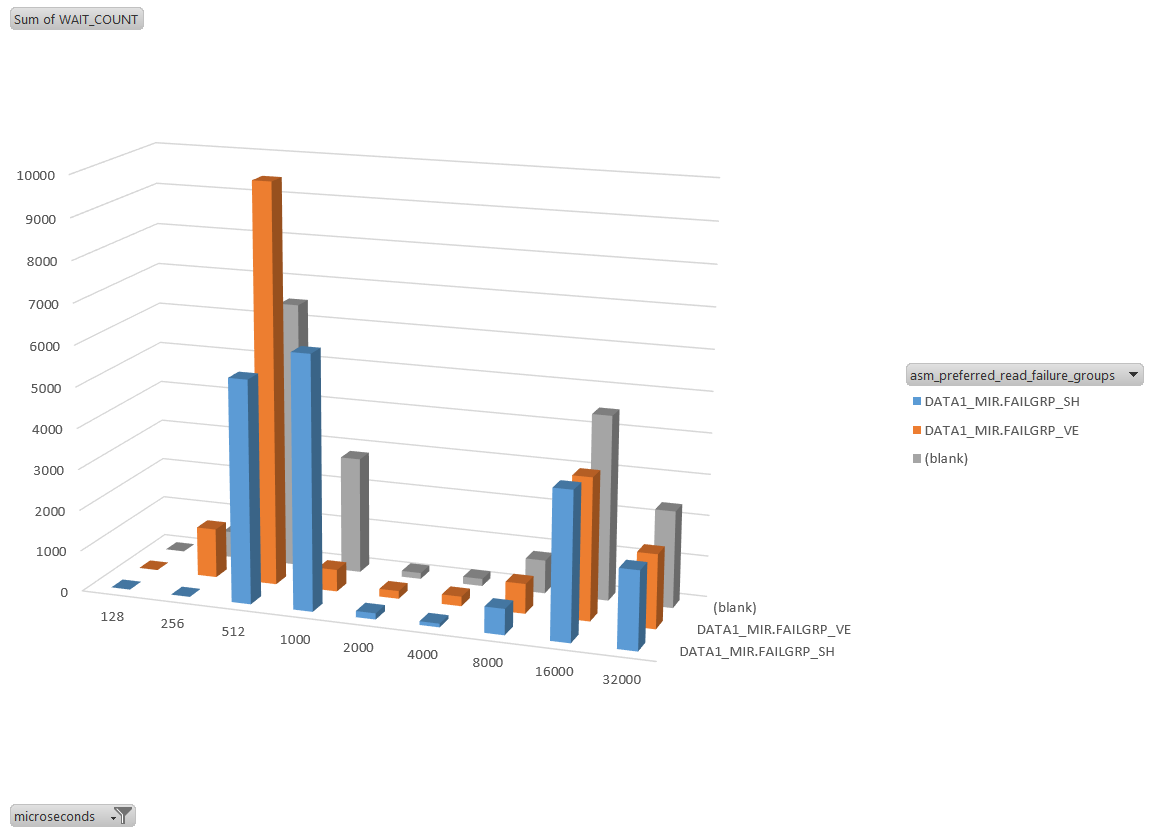
With efficient storage array, extended cluster latency may penalize performance of writes. However, writes should be asynchronous (DBRW) so the latency is not part of the user response time. I’m not talking about redo logs here. For redo you have to choose to put it on a local only diskgroup or on a mirrored one. This depends on availability requirements and latency between the two sites.
So, when you have non uniform latency among failure groups, don’t forget to set asm_preferred_read_failure_groups. And test it with SLOB as I did here. Wat you expect from theorical latencies should be visible in the wait event histogram.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)