In the first post of this series we brought up an Exasol test system to have something to play with. Because playing without data is a bit boring this post is about loading data from PostgreSQL to Exasol. We’ll use pgbench on the PostgreSQL side to generate some data and then load that into Exasol.
Exasol comes with a concept called “virtual schemas”. If you know PostgreSQL you can compare that to foreign data wrappers. The purpose is to access data on foreign systems of any kind and integrate that into the system. The data on the foreign system is accessed through standard SQL commands, very much the same like PostgreSQL is doing it. In contrast to PostgreSQL, Exasol usually uses JDBC to connect to a foreign data source, here is the list of currently supported JDBC dialects. You are not limited to one of those, you can well go ahead and combine any of these and centralize your reporting (or whatever you plan to do with the foreign data) into Exasol. There is also a GitHub project which provides additional information around abadapters and virtual schemas.
Before you can connect to an external system you need to install the corresponding JDBC driver but in the case of PostgreSQL the JDBC driver is already there by default. You can check that in the web interface of Exasol:
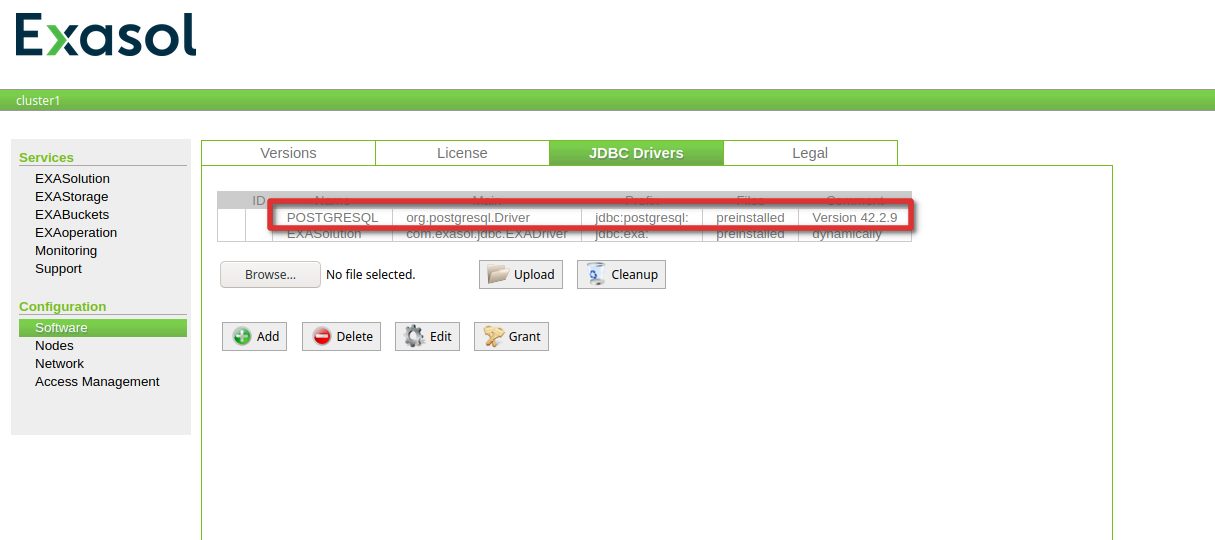 .
.
We will anyway upload the latest PostgreSQL driver to show the procedure. To upload the latest driver, again go to EXAOperations and locate the drivers tab under software adn press “Add”:
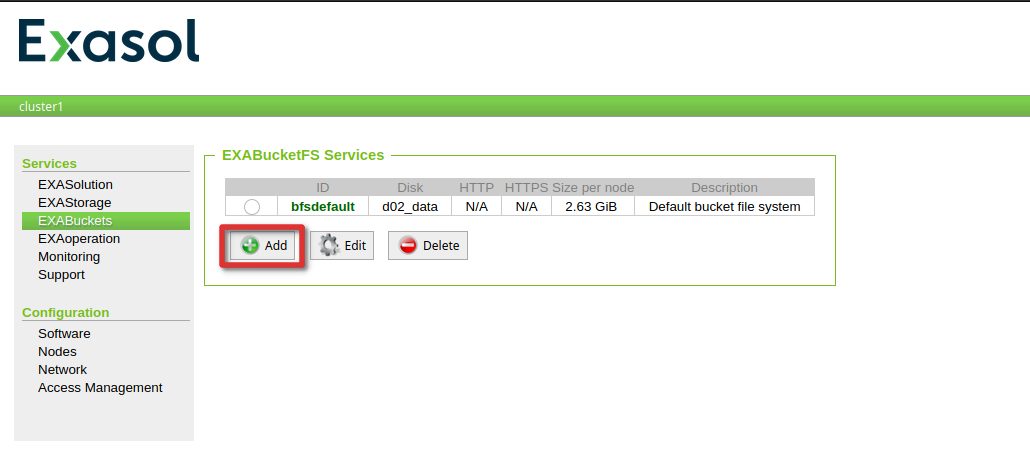
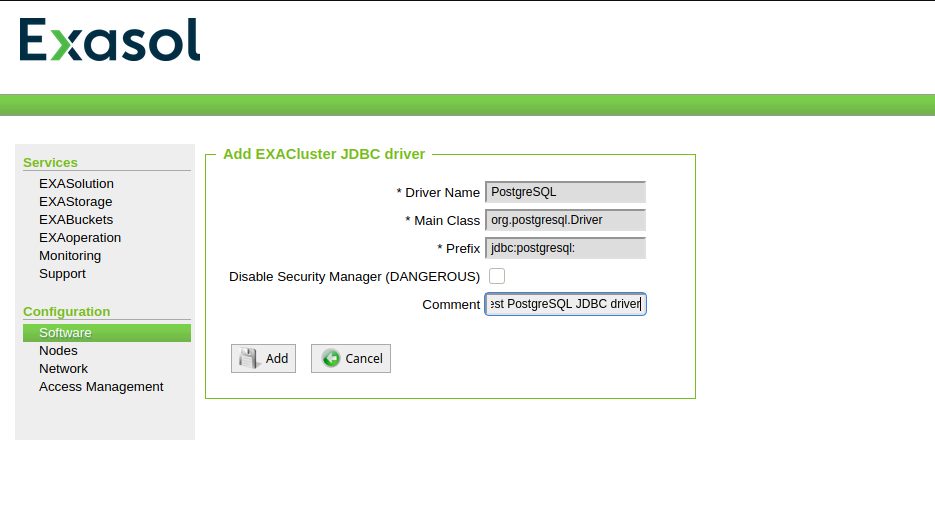
Add the driver details:
Locate the driver (can be downloaded from jdbc.postgresql.org) and upload the jar file:
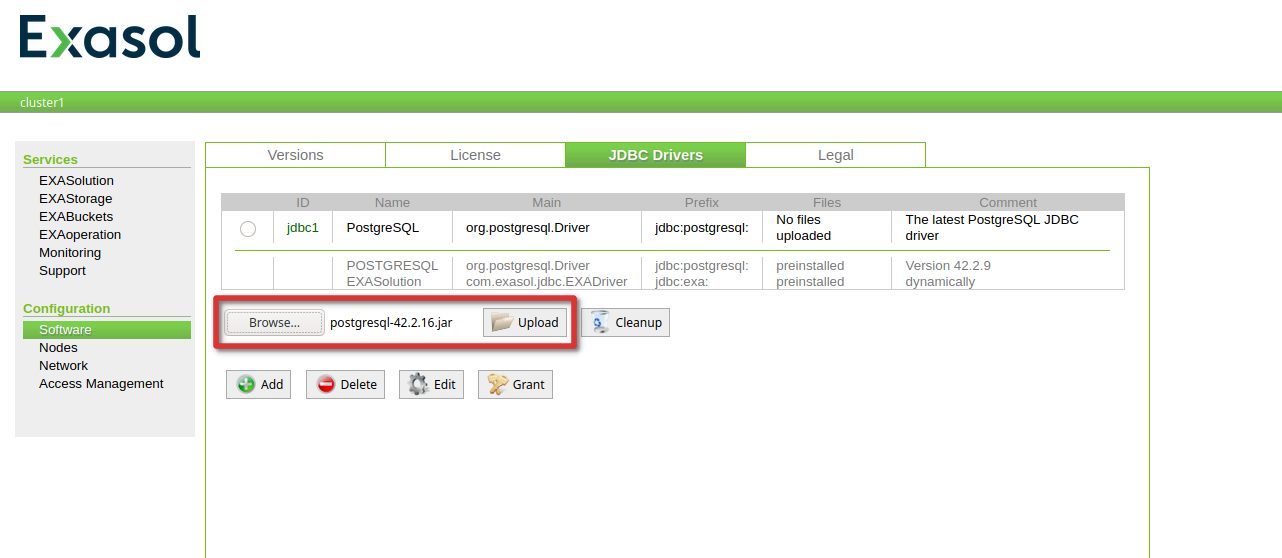
That’s it for the driver update.
Before we connect Exasol to PostgreSQL, let’s prepare the data on the PostgreSQL side:
postgres=# create user exasol with login password 'exasol'; CREATE ROLE postgres=# create database exasol with owner = exasol; CREATE DATABASE postgres=# \! pgbench -i -s 100 -U exasol exasol dropping old tables... creating tables... generating data... 100000 of 10000000 tuples (1%) done (elapsed 0.07 s, remaining 7.14 s) 200000 of 10000000 tuples (2%) done (elapsed 0.19 s, remaining 9.21 s) ... 10000000 of 10000000 tuples (100%) done (elapsed 17.42 s, remaining 0.00 s) vacuuming... creating primary keys... done.
That gives as 10 million rows in the pgbench_accounts table:
postgres=# \c exasol exasol You are now connected to database "exasol" as user "exasol". exasol=> select count(*) from pgbench_accounts; count ---------- 10000000 (1 row)
On the Exasol side, the first thing you need to do is to create a connection (In PostgreSQL that would be the foreign server and the user mapping):
dwe@dwe:~/EXAplus-7.0.0$ ./exaplus -c 192.168.22.117:8563 -u sys -p exasol EXAplus 7.0.0 (c) EXASOL AG Wednesday, September 30, 2020 at 9:49:38 AM Central European Summer Time Connected to database EXAone as user sys. EXASolution 7.0.2 (c) EXASOL AG SQL_EXA> CREATE OR REPLACE CONNECTION JDBC_POSTGRESQL 1 > TO 'jdbc:postgresql://192.168.22.11:5433/exasol' 2 > USER 'exasol' 3 > IDENTIFIED BY 'exasol'; EXA: CREATE OR REPLACE CONNECTION JDBC_POSTGRESQL... Rows affected: 0
To test that connection you can simply do:
SQL_EXA> IMPORT FROM JDBC AT JDBC_POSTGRESQL STATEMENT ' SELECT ''OK'' '; EXA: IMPORT FROM JDBC AT JDBC_POSTGRESQL STATEMENT ' SELECT ''OK'' '; ?column? -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- OK 1 row in resultset. SQL_EXA>
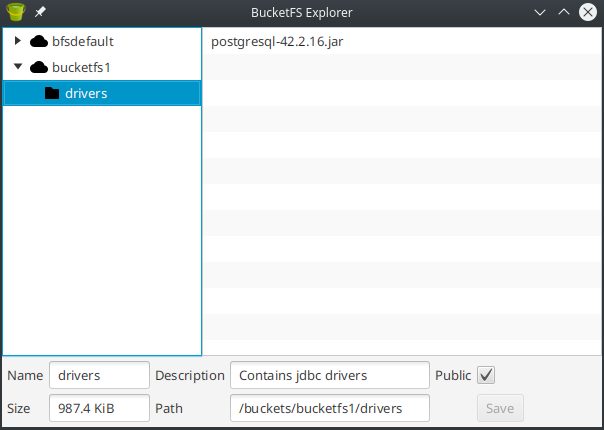
Now is the time to create the virtual schema so we can access the tables on the PostgreSQL side via plan SQL. Before we can do that we need to deploy the adapter. The PostgreSQL JDBC driver must be uploaded to BucketFS and I’ve created a new bucket for that:
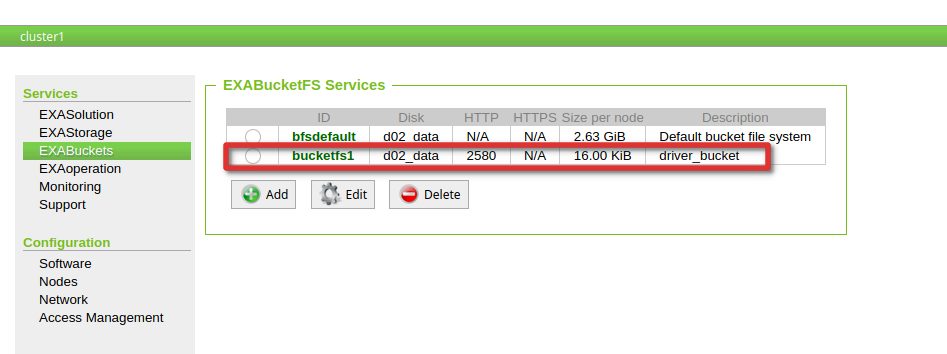
BucketFS is an internal file system that gets synchronized automatically between the Exasol cluster nodes.
The easiest way to upload files is to use the bucket explorer but you could also use curl against the REST API:
dwe@dwe:~/Downloads$ curl --user admin -v -X PUT -T postgresql-42.2.16.jar http://192.168.22.117:2580/bucketfs/bucketfs1/drivers/postgresql-42.2.16.jar
Also upload the latest virtual schema distribution from here, so it looks like this:
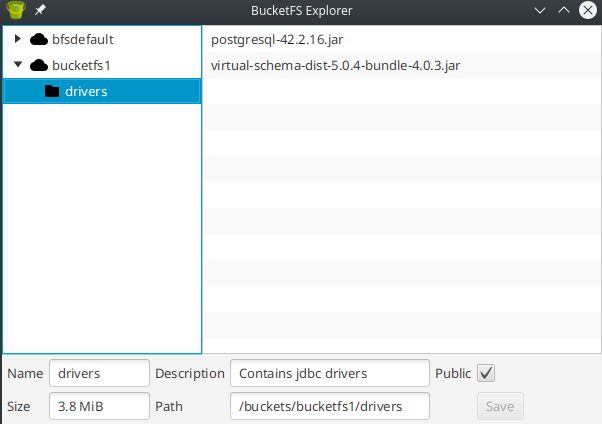
Now we need to create the so-clalled “Adapter script”:
SQL_EXA> CREATE SCHEMA ADAPTER;
EXA: CREATE SCHEMA ADAPTER;
Rows affected: 0
SQL_EXA> CREATE OR REPLACE JAVA ADAPTER.JDBC_ADAPTER AS
%scriptclass com.exasol.adapter.RequestDispatcher;
%jar /buckets/bucketfs1/drivers/virtual-schema-dist-5.0.4-bundle-4.0.3.jar;
%jar /buckets/bucketfs1/drivers/postgresql-42.2.16.jar;
/
EXA: CREATE OR REPLACE JAVA ADAPTER SCRIPT ADAPTER.JDBC_ADAPTER AS...
Rows affected: 0
SQL_EXA>
Finally we can create the virtual schema:
SQL_EXA> CREATE VIRTUAL SCHEMA POSTGRESQL_REMOTE
USING ADAPTER.JDBC_ADAPTER
WITH
SQL_DIALECT = 'POSTGRESQL'
SCHEMA_NAME = 'public'
CONNECTION_NAME = 'JDBC_POSTGRESQL';
EXA: CREATE VIRTUAL SCHEMA POSTGRESQL_REMOTE...
Rows affected: 0
Now, that the virtual schema is there, the tables on the PostgreSQL side are visible and can be queried:
SQL_EXA> select table_name from exa_dba_tables where TABLE_SCHEMA = 'POSTGRESQL_REMOTE';
EXA: select table_name from exa_dba_tables where TABLE_SCHEMA = 'POSTGRESQL...
TABLE_NAME
--------------------------------------------------------------------------------------------------------------------------------
PGBENCH_ACCOUNTS
PGBENCH_BRANCHES
PGBENCH_HISTORY
PGBENCH_TELLERS
4 rows in resultset.
SQL_EXA> select count(*) from POSTGRESQL_REMOTE.PGBENCH_ACCOUNTS;
EXA: select count(*) from POSTGRESQL_REMOTE.PGBENCH_ACCOUNTS;
COUNT(*)
--------------------
10000000
1 row in resultset.
Compared to PostgreSQL it is bit more work to set this up, but once you are through the process the first time it not an issue anymore. In the next post we will load that data into Exasol and get into more details how Exasol works when it comes to transactions.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)