SQL Server 2019 RC1 was released out a few weeks ago and it is time to start blogging about my favorite core engine features that will be shipped with the next version of SQL Server. Things should not be completely different with the RTM, so let’s introduce the accelerated database recovery (aka ADR) which is mainly designed to solve an annoying issue that probably most of SQL Server DBAs already faced at least one time: long running transactions that impact the overall recovery time. As a reminder with current versions of SQL Server, database recovery time is tied to the largest transaction at the moment of the crash. This is even more true in high-critical environments where it may have a huge impact on the service or application availability and ADR is another feature that may help for sure.
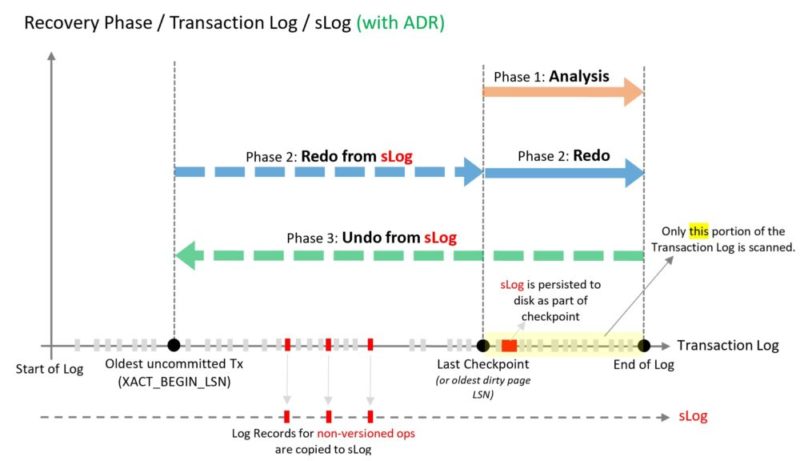
Image from Microsoft documentation
In order to allow very fast rollback and recovery process the SQL Server team redesigned completely the SQL database engine recovery process and the interesting point is they have introduced row-versioning to achieve it. Row-versioning, however, exist since the SQL Server 2005 version through RCSI and SI isolation levels and from my opinion this is finally good news to extend (finally) such capabilities to address long recovery time.
Anyway, I performed some testing to get an idea of what could be the benefit of ADR and the impact of the workload as well. Firstly, I performed a recovery test without ADR and after initiating a long running transaction, I simply crashed my SQL Server instance. I used an AdventureWorks database with the dbo.bigTransactionHistory table which is big enough (I think) to get a relevant result.
The activation of ADR is per database meaning that row-versioning is also managed locally per database. It allows a better workload isolation compared to using the global tempdb version store with previous SQL Server versions.
USE AdventureWorks_dbi;
ALTER DATABASE AdventureWorks_dbi SET
ACCELERATED_DATABASE_RECOVERY = OFF;
ALTER DATABASE AdventureWorks_dbi SET
COMPATIBILITY_LEVEL = 150;
GO
The dbo.bigtransactionHistory table has only one clustered primary key …
EXEC sp_helpindex 'dbo.bigTransactionHistory'; GO
![]()
… with 158’272’243 rows and about 2GB of data
EXEC sp_helpindex 'dbo.bigTransactionHistory'; GO
![]()
I simulated a long running transaction with the following update query that touches every row of the dbo.bigTransactionHistory table to get a relevant impact on the recovery process duration time.
BEGIN TRAN; UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO
The related transactions wrote a log of records into the transaction log size as show below:
SELECT DB_NAME(database_id) AS [db_name], total_log_size_in_bytes / 1024 / 1024 AS size_MB, used_log_space_in_percent AS [used_%] FROM sys.dm_db_log_space_usage; GO
![]()
The sys.dm_tran_* and sys.dm_exec_* DMVs may be helpful to dig into the transaction detail including the transaction start time and log used in the transaction log:
SELECT GETDATE() AS [Current Time], [des].[login_name] AS [Login Name], DB_NAME ([dtdt].database_id) AS [Database Name], [dtdt].[database_transaction_begin_time] AS [Transaction Begin Time], [dtdt].[database_transaction_log_bytes_used] / 1024 / 1024 AS [Log Used MB], [dtdt].[database_transaction_log_bytes_reserved] / 1024 / 1024 AS [Log Reserved MB], SUBSTRING([dest].text, [der].statement_start_offset/2 + 1,(CASE WHEN [der].statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max),[dest].text)) * 2 ELSE [der].statement_end_offset END - [der].statement_start_offset)/2) as [Query Text] FROM sys.dm_tran_database_transactions [dtdt] INNER JOIN sys.dm_tran_session_transactions [dtst] ON [dtst].[transaction_id] = [dtdt].[transaction_id] INNER JOIN sys.dm_exec_sessions [des] ON [des].[session_id] = [dtst].[session_id] INNER JOIN sys.dm_exec_connections [dec] ON [dec].[session_id] = [dtst].[session_id] LEFT OUTER JOIN sys.dm_exec_requests [der] ON [der].[session_id] = [dtst].[session_id] OUTER APPLY sys.dm_exec_sql_text ([der].[sql_handle]) AS [dest] GO
![]()
The restart of my SQL Server instance kicked-in the AdventureWorks_dbi database recovery process. It took about 6min in my case:
EXEC sp_readerrorlog 0, 1, N'AdventureWorks_dbi'
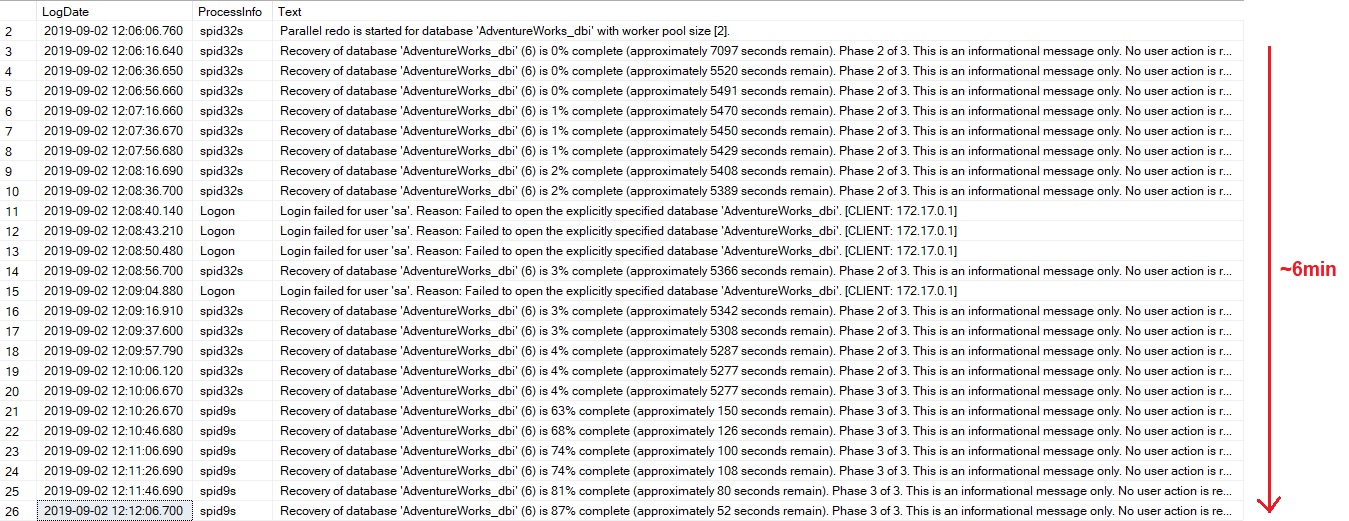
Digging further in the SQL Server error log, I noticed the phase2 (redo) and phase3 (undo) of the recovery process that took the most of time (as expected).
However, if I performed the same test with ADR enabled for the AdventureWorks_dbi database …
USE AdventureWorks_dbi;
ALTER DATABASE AdventureWorks_dbi SET
ACCELERATED_DATABASE_RECOVERY = ON;
… and I dig again into the SQL Server error log:

Well, the output above is pretty different but clear and irrevocable: there is a tremendous improvement of the recovery time process here. The SQL Server error log indicates the redo phase took 0ms and the undo phase 119ms. I also tested different variations in terms of long transactions and logs generated in the transaction log (4.5GB, 9.1GB and 21GB) without and with ADR. With the latter database recovery remained fast irrespective to the transaction log size as shown below:
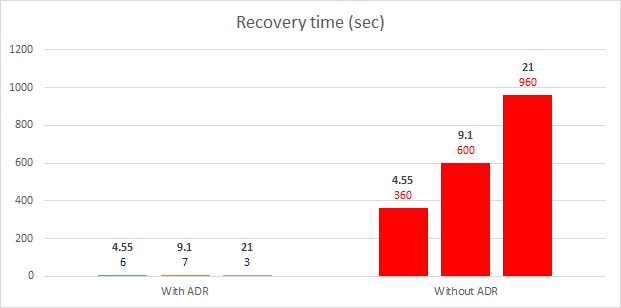
But there is no free lunch when enabling ADR because it is a row-versioning based process which may have an impact on the workload. I was curious to compare the performance of my update queries between scenarios including no row-versioning (default), row-versioning with RCSI only, ADR only and finally both RCSI and ADR enabled. I performed all my tests on a virtual machine quad core Intel® Core ™ i7-6600U CPU @ 2.6Ghz and 8GB of RAM. SQL Server memory is capped to 6GB. The underlying storage for SQL Server data files is hosted on SSD disk Samsung 850 EVO 1TB.
Here the first test I performed. This is the same update I performed previously which touches every row on the dbo.bigTransactionHistory table:
BEGIN TRAN; UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO
And here the result with the different scenarios:
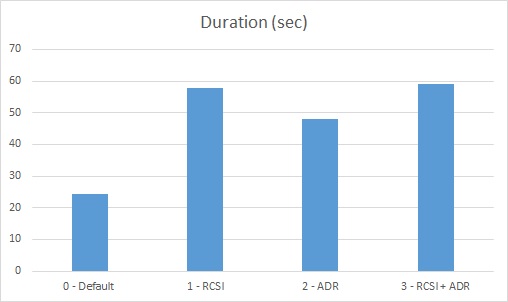
Please don’t focus strongly on values here because it will depend on your context but the result answers to the following questions: Does the activation of ADR will have an impact on the workload and if yes is it in the same order of magnitude than RCSI / SI? The results are self-explanatory.
Then I decided to continue my tests by increasing the impact of the long running transaction with additional updates on the same data in order to stress a little bit the version store.
BEGIN TRAN; UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO
Here the new results:
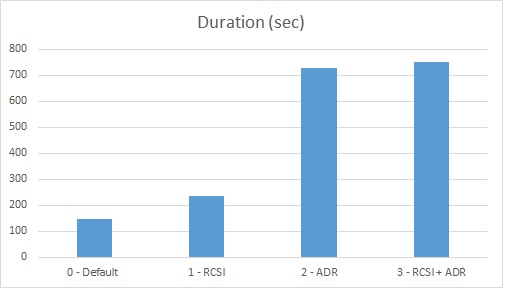
This time ADR seems to have a bigger impact than RCSI in my case. Regardless the strict values of this test, the key point here is we have to be aware that enabling ADR will have an impact to the workload.
After performing these bunch of tests, it’s time to get a big picture of ADR design with several components per database including a persisted version store (PVS), a Logical Revert, a sLog and a cleaner process. In this blog post I would like to focus on the PVS component that acts as persistent version store for the concerned database. In other words, with ADR, tempdb will not be used to store row versions anymore. The interesting point is that RCSI / SI row-versioning will continue to be handle through the PVS if ADR is enabled according to my tests.
There is the new added column named is_accelerated_database_recovery_on to the sys.databases system view. In my case both RCSI and ADR are enabled in AdventureWorks_dbi database.
SELECT name AS [database_name], is_read_committed_snapshot_on, is_accelerated_database_recovery_on FROM sys.databases WHERE database_id = DB_ID()

The sys.dm_tran_version_store_space_usage DMV displays the total space in tempdb used by the version store for each database whereas the new sys.dm_tran_persistent_version_store_stats DMV provides information related to the new PVS created with the ADR activation.
BEGIN TRAN; UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO SELECT DB_NAME(database_id) AS [db_name], oldest_active_transaction_id, persistent_version_store_size_kb / 1024 AS pvs_MB FROM sys.dm_tran_persistent_version_store_stats; GO SELECT database_id, reserved_page_count / 128 AS reserved_MB FROM sys.dm_tran_version_store_space_usage; GO
After running my update query, I noticed the PVS in AdventureWorks_dbi database was used rather the version store in tempdb.
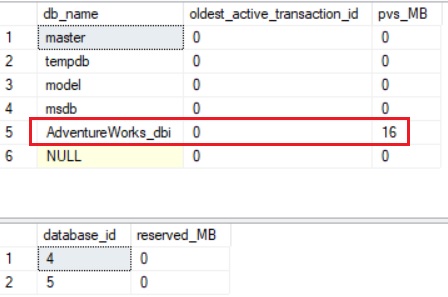
So, getting rid of the version store in tempdb seems to be a good idea and probably more scalable per database but according to my tests and without drawing any conclusion now it may lead to performance considerations … let’s see in the future what happens …
In addition, from a storage perspective, because SQL Server doesn’t use tempdb anymore as version store, my curiosity led to see what happens behind the scene and how PVS interacts with the data pages where row-versioning comes into play. Let’s do some experiments:
Let’s create the dbo.bigTransationHistory_row_version table from the dbo.bigTransationHistory table with fewer data:
USE AdventureWorks_dbi; GO DROP TABLE IF EXISTS [dbo].[bigTransactionHistory_row_version]; SELECT TOP 1 * INTO [dbo].[bigTransactionHistory_row_version] FROM [dbo].[bigTransactionHistory]
Now, let’s have a look at the data page that belongs to my dbo.bigTransacitonHistory_row_version table with the page ID 499960 in my case:
DBCC TRACEON (3604, -1); DBCC PAGE (AdventureWorks_dbi, 1, 499960, 3);
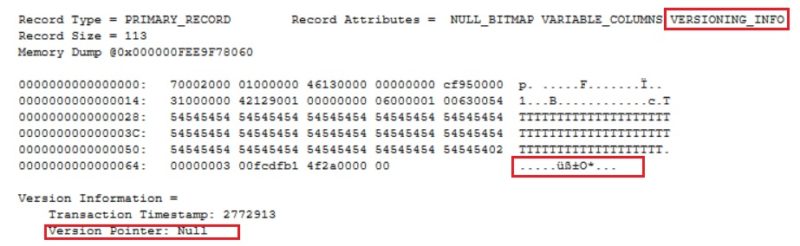
Versioning info exists in the header but obviously version pointer is set to Null because there is no additional version of row to maintain in this case. I just inserted one.
Let’s update the only row that exists in the table as follows:
BEGIN TRAN; UPDATE [dbo].[bigTransactionHistory_row_version] SET Quantity = Quantity + 1
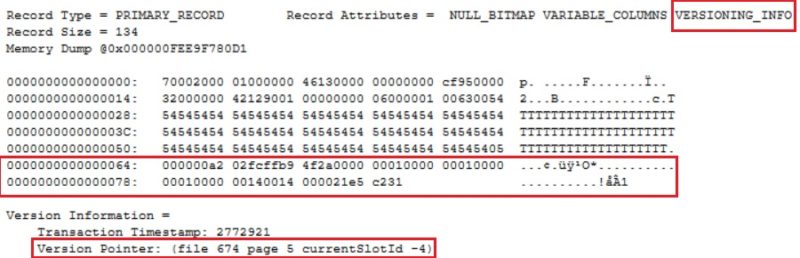
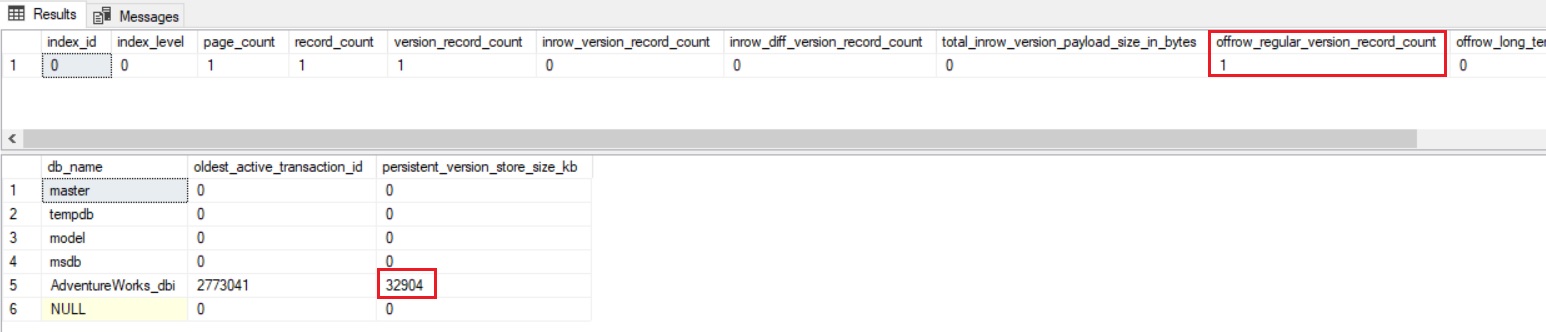
The version pointer has been updated (but not sure the information is consistent here or at least the values displayed are weird). One another interesting point is there exists more information than the initial 14 bytes of information we may expect to keep track of the pointers. There is also extra 21 bytes at the end of row as show above. On the other hand, the sys.dm_db_index_physical_stats() DMF has been updated to reflect the PVS information with new columns inrow_*, total_inrow_* and offrow_* and may help to understand some of the PVS internals.
SELECT
index_id,
index_level,
page_count,
record_count,
version_record_count,
inrow_version_record_count,
inrow_diff_version_record_count,
total_inrow_version_payload_size_in_bytes,
offrow_regular_version_record_count,
offrow_long_term_version_record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(), OBJECT_ID('dbo.bigTransactionHistory_row_version'),
NULL,
NULL,
'DETAILED'
)

Indeed, referring to the above output and correlating them to results I found inside the data page, I would assume the extra 21 bytes stored in the row seems to reflect a (diff ?? .. something I need to get info) value of the previous row (focus on in_row_diff_version_record_count and in_row_version_payload_size_in_bytes columns).
Furthermore, if I perform the update operation on the same data the storage strategy seems to switch to a off-row mode if I refer again to the sys.dm_db_index_physical_stats() DMF output:

Let’s go back to the DBCC PAGE output to confirm this assumption:
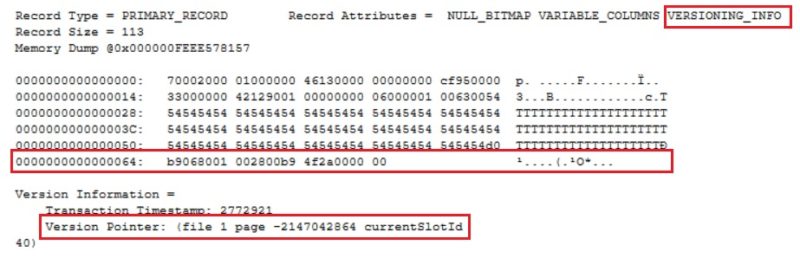
Indeed, the extra payload has disappeared, and it remains only the 14 bytes pointer which has been updated accordingly.
Finally, if I perform multiple updates of the same row, SQL Server should keep the off-row storage and should create inside it a chain of version pointers and their corresponding values.
BEGIN TRAN; UPDATE [dbo].[bigTransactionHistory_row_version] SET Quantity = Quantity + 1 GO 100000
My assumption is verified by taking a look at the previous DMVs. The persistent version store size has increased from ~16MB to ~32MB and we still have 1 version record in off-row mode meaning there is still one version pointer that references the off-row mode structure for my record.
Finally, let’s introduce the cleaner component. Like the tempdb version store, cleanup of old row versions is achieved by an asynchronous process that cleans page versions that are not needed. It wakes up periodically, but we can force it by executing the sp_persistent_version_cleanup stored procedure.
Referring to one of my first tests, the PVS size is about 8GB.
BEGIN TRAN; UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO UPDATE dbo.bigTransactionHistory SET Quantity = Quantity + 1; GO SELECT DB_NAME(database_id) AS [db_name], oldest_active_transaction_id, persistent_version_store_size_kb / 1024 AS pvs_MB FROM sys.dm_tran_persistent_version_store_stats; GO -- Running PVS cleanu process EXEC sp_persistent_version_cleanup
According to my tests, the cleanup task took around 6min for the entire PVS, but it was not a blocking process at all as you may see below. As ultimate test, I executed in parallel an update query that touched every row of the same table, but it was not blocked by the cleaner as show below:

This is a process I need to investigate further. Other posts are coming as well .. with other ADR components.
See you!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)