A couple of days ago, Microsoft has rolled out the SQL Server vNext CTP 1.3 which includes very nice features and the one that interested me in the supportability of AlwaysOn availability groups on Linux. That is definitely a good news because we may benefit from new ways of architecting high-availability. There are a lot of new cool enhancements, which we’ll try to study when writing new blog posts. In this first blog, let’s learn new available configuration options.
First of all, let’s say that configuring availability groups on Linux is not different than configuring them on Windows in workgroup mode (domainless configuration) from SQL Server perspective.
Basically, the same steps remain as it is (please refer to the Microsoft installation documentation):
- Creating login and users on each replica
- Creating certificate and grant authorization to the corresponding user on each replica
- Creating endpoint for data mirroring and grant permission connected to the corresponding certificate
So let’s just set the scene before moving forward on the other installation steps. I used for my demo two virtual machines on Hyper-V which run on Linux CentOS 7 (LINUX02 and LINUX04) . I also installed two SQL Server instances (CTP 1.3) on each machine which will run on the top of the cluster infrastructure with Pacemaker and Corosync.
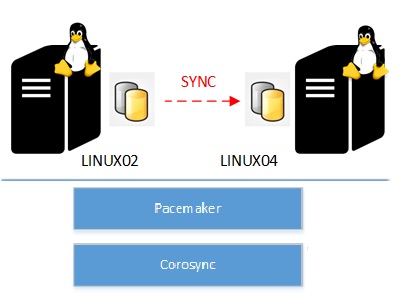
Obviously this time the NFS server is not part of this infrastructure and this time I used a symmetric storage on each virtual machine which includes two mount points and two ext4 partitions (respectively /SQL_DATA and /SQL_LOG to host my AdventureWorks2012 database files).
[mikedavem@linux02 ~]$ cat /etc/fstab /dev/mapper/cl-root / xfs defaults 0 0 UUID=d6eb8d27-35c7-4f0f-b0c1-42e380ab2eca /boot xfs defaults 0 0 /dev/mapper/cl-swap swap swap defaults 0 0 /dev/sdb1 /sql_data ext4 defaults 0 0 /dev/sdc1 /sql_log ext4 defaults 0 0
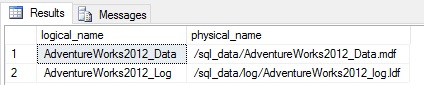
SELECT
name AS logical_name,
physical_name
FROM sys.master_files
WHERE database_id = DB_ID('AdventureWorks2012')
First step to enable the AlwaysOn feature: we have to use the mssql-conf tool (which replaces the famous SQL Server configuration manager) with the new option set hadrenabled 1
Then if we use the Linux firewall on each machine, we have to open the corresponding TCP endpoint port on the Linux firewall on each Linux machine.
[root@linux02 data]firewall-cmd --zone=public --add-port=5022/tcp --permanent success [root@linux02 data]firewall-cmd –reload success [root@linux02 data]firewall-cmd --permanent --zone=public --list-all public target: default icmp-block-inversion: no interfaces: sources: services: dhcpv6-client high-availability mountd nfs rpc-bind ssh ports: 1433/tcp 5022/tcp protocols: masquerade: no forward-ports: sourceports: icmp-blocks: rich rules: [root@linux04 ~]firewall-cmd --zone=public --add-port=5022/tcp --permanent success [root@linux04 ~]firewall-cmd --reload
No really new stuff so far … The most interesting part comes now. After installing SQL Server on Linux and achieving endpoint configurations, it’s time to create the availability group. But wait, at this stage we didn’t install any clustering part right? And in fact, we don’t have to do this. We are now able to create an availability group without any cluster dependencies by using a new T-SQL parameter CLUSTER_TYPE = NONE as follows. Very interesting because we may think about new scenarios where only read-scalability capabilities are considered on DR site. In this case we don’t have to setup additional cluster nodes which may lead to manageability overhead in this case.
We may also use the direct seeding mode feature available since SQL Server 2016 to simplify the process of adding a database in the corresponding availability group (AdventureWorks2012 database in my case).
:CONNECT LINUX02 -U sa -P Xxxxx
CREATE AVAILABILITY GROUP [agLinux]
WITH
(
DB_FAILOVER = ON, --> Trigger the failover of the entire AG if one DB fails
CLUSTER_TYPE = NONE --> SQL Server is not a member of a Windows Server Failover Cluster
)
FOR REPLICA ON
N'LINUX02'
WITH
(
ENDPOINT_URL = N'tcp://192.168.5.18:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC, --> Use direct seeding mode
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'LINUX04'
WITH
(
ENDPOINT_URL = N'tcp://192.168.5.20:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC, --> Use direct seeding mode
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
);
GO
ALTER AVAILABILITY GROUP [agLinux]
GRANT CREATE ANY DATABASE;
GO
:CONNECT LINUX04 -U sa -P Xxxxx
ALTER AVAILABILITY GROUP [agLinux] JOIN WITH (CLUSTER_TYPE = NONE)
ALTER AVAILABILITY GROUP [agLinux] GRANT CREATE ANY DATABASE;
GO
:CONNECT LINUX02 -U sa -P Xxxxx
ALTER DATABASE [AdventureWorks2012] SET RECOVERY FULL;
GO
BACKUP DATABASE [AdventureWorks2012] TO DISK = 'NUL';
GO
-- Add the AdventureWorks2012 database to the agLinux AG
ALTER AVAILABILITY GROUP [agLinux] ADD DATABASE [AdventureWorks2012];
GO
After configuring the agLinux availability group let’s have a look at the different DMVs I usually use in this case:
- sys.dm_hadr_availability_group_states
- sys.dm_hadr_availability_replica_states
- sys.dm_hadr_database_replica_states
-- groups info SELECT g.name as ag_name, rgs.primary_replica, rgs.primary_recovery_health_desc as recovery_health, rgs.synchronization_health_desc as sync_health FROM sys.dm_hadr_availability_group_states as rgs JOIN sys.availability_groups AS g ON rgs.group_id = g.group_id -- replicas info SELECT g.name as ag_name, r.replica_server_name, rs.is_local, rs.role_desc as role, rs.operational_state_desc as op_state, rs.connected_state_desc as connect_state, rs.synchronization_health_desc as sync_state, rs.last_connect_error_number, rs.last_connect_error_description FROM sys.dm_hadr_availability_replica_states AS rs JOIN sys.availability_replicas AS r ON rs.replica_id = r.replica_id JOIN sys.availability_groups AS g ON g.group_id = r.group_id -- DB level SELECT g.name as ag_name, r.replica_server_name, DB_NAME(drs.database_id) as [database_name], drs.is_local, drs.is_primary_replica, synchronization_state_desc as sync_state, synchronization_health_desc as sync_health, database_state_desc as db_state FROM sys.dm_hadr_database_replica_states AS drs JOIN sys.availability_replicas AS r ON r.replica_id = drs.replica_id JOIN sys.availability_groups AS g ON g.group_id = drs.group_id ORDER BY g.name, drs.is_primary_replica DESC; GO
Here the corresponding output:
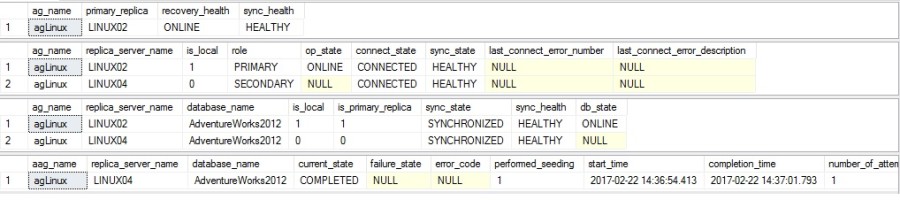
Ok everything seems to be ok. We have configured an availability group which includes two replicas and synchronous replication so far. But maybe you have already noticed we didn’t create any listener and the reason is pretty obvious: if we refer to previous versions of SQL Server, creating a listener requires to create a corresponding CAP on the WSFC side and in our context, no cluster exists at this stage. So go ahead and let’s do it. You may refer to the Microsoft documentation to add the pacemaker cluster to the existing infrastructure.
I didn’t expect a big change compared to my last installation for SQL Server FCI on Linux for the basics but for the integration of the AG resource it will probably be another story. Indeed, the declaration of the resource (ocf:mssql:ag) is completely different compared to the SQL Server FCI (ocf::sql:fci). In this case, we have to create a multi-state resource. Multi-state resources are specialized clone resources which may be in one of two operating modes – master and slave. We run exactly on the same concept with availability groups because we consider to use one primary replica (master) and at least one secondary (slave). According to the Microsoft documentation we have to setup meta-properties which limit the number of resource copies (on replicas) as well as the number of master resources (only one primary replica at time in our case).
Update 20.04.2017 – Removing of pcs command because it keeps changing with new CTPs. Please refer to the Microsoft documentation to get the last update of the command.
Creating a multi-state resource generates two separate resources regarding their role. In my case, I will get respectively sqllinuxaag-master (for the resource enrolled as Master resource) and sqllinuxaag-slave (for resource(s) enrolled as Slave resource(s)).
Update 20.04.2017 – Removing of pcs command because it keeps changing with new CTPs. Please refer to the Microsoft documentation to get the last update of the command
Finally, we have to create and associate a virtual IP address as follows. The virtual IP must run at the same location than the master resource in our case (INFINITY is mandatory here)
[mikedavem@linux02 ~]$ sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=192.168.5.30 [mikedavem@linux02 ~]$ sudo pcs constraint colocation add virtualip sqllinuxaag-master INFINITY with-rsc-role=Master
Here a recap of the existing constraints which concern my availability group resource:
[mikedavem@linux02 ~]$ sudo pcs constraint Location Constraints: Ordering Constraints: promote sqllinuxaag-master then start virtualip (kind:Mandatory) Colocation Constraints: virtualip with sqllinuxaag-master (score:INFINITY) (with-rsc-role:Master) Ticket Constraints:
We may notice the global state of the resources and their roles (Master/Slave)
[mikedavem@linux02 ~]$ sudo pcs status
Cluster name: clustlinuxag
Stack: corosync
Current DC: linux04.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - partition with quorum
Last updated: Mon Feb 27 06:16:03 2017 Last change: Mon Feb 27 06:14:11 2017 by root via cibadmin on linux02.dbi-services.test
…
Full list of resources:
Master/Slave Set: sqllinuxaag-master [sqllinuxaag]
Masters: [ linux02.dbi-services.test ]
Slaves: [ linux04.dbi-services.test ]
virtualip (ocf::heartbeat:IPaddr2): Started linux02.dbi-services.test
So, now let’s perform some failover tests. I used a basic PowerShell script to connect to my availability group by using the sqllinuxaag resource and return a response (OK and the server name of the concerned replica or KO). But let’s say the resource is not considered as a listener from the availability group. No listener exists at this stage.
- First test:
The first test consisted in switching manually over the sqllinuxaag (master) to the next available node (LINUX02). At this stage, we can’t use neither the wizard nor T-SQL statement to trigger a failover event. This is a limitation (explained by Microsoft) and I expect to see it to disappear in the future. Keeping the control of such action from SQL Server side will make more sense for DBAs.
[mikedavem@linux04 ~]$ sudo pcs resource move sqllinuxaag-master linux02.dbi-services.test --master
During the failover event, no way to reach out the resource but the situation went back into normal as expected.

- Second test
The second test consisted in simulating “soft” failure by changing the state of the new active node (LINUX02) to standby in order to trigger a switch over the next available cluster node (LINUX04). But before going on this way, let’s configure stickiness to avoid unexpected failback of the sqllinuxaag-master resource when the situation will go back to normal.
[mikedavem@linux04 ~]$ sudo pcs resource defaults resource-stickiness=INFINITY
[mikedavem@linux04 ~]$ sudo pcs cluster standby linux02.dbi-services.test
[mikedavem@linux04 ~]$ sudo pcs status
Cluster name: clustlinuxag
Stack: corosync
Current DC: linux02.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - partition with quorum
Last updated: Sun Feb 26 18:55:01 2017 Last change: Sun Feb 26 18:54:42 2017 by root via crm_attribute on linux04.dbi-services.test
2 nodes and 3 resources configured
Node linux02.dbi-services.test: standby
Online: [ linux04.dbi-services.test ]
Full list of resources:
Master/Slave Set: sqllinuxaag-master [sqllinuxaag]
Masters: [ linux04.dbi-services.test ]
Stopped: [ linux02.dbi-services.test ]
virtualip (ocf::heartbeat:IPaddr2): Started linux04.dbi-services.test
Same result than previously. During the failover event, the resource was unreachable but after the situation went back to normal, the application was able to connect again.

We may also confirm the state of the availability group by using usual DMVs. The replica role has switched between replicas as expected and the synchronization state remained in healthy state.
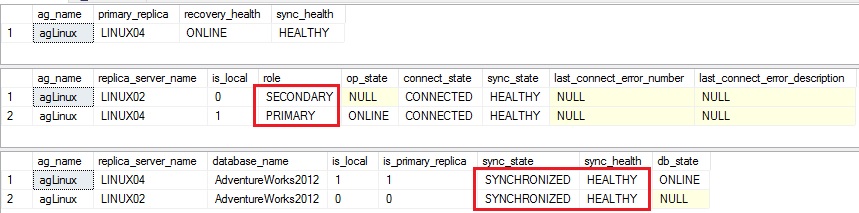
- Third test
My third test consisted in simulating a network outage between my two cluster nodes and the infrastructure responded well and performed the necessary tasks to recover the situation.
It was a quick introduction to the new capabilities offered by the SQL Server vNext in terms of HA and availability groups. Other scenarios and tests as well will come soon. In any event, availability groups feature is very popular as well as Linux in my area and getting the way to mix the both will probably be a good argument for customer adoption. We will see in a near future!
See you
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)