On my first blog about SQL Server on Linux, I introduced the new high availability feature which concerns only SQL Server failover cluster instances so far. During this discovery time, I had the support of Mihaela Blendea (@MihaelaBlendea) at Microsoft to clarify some architecture aspects about this new kind of architecture. Firstly, I would like to thank her. It’s always a big pleasure to get the availability of the Microsoft team in this case. But after achieving the installation of my SQL Server FCI environment on Linux, I was interested in performing the same in a more complex scenario like multi-subnets failover clusters as I may notice at some customer shops. The installation process will surely change over the time and it is not intended as an official documentation of course. This is only an exercise which is part of my Linux immersion experience.
So I decided to evolve my current architecture (two clusters nodes with PaceMaker on the same subnet) by introducing a third one on a different subnet. Here a picture of the architecture I wanted to install.
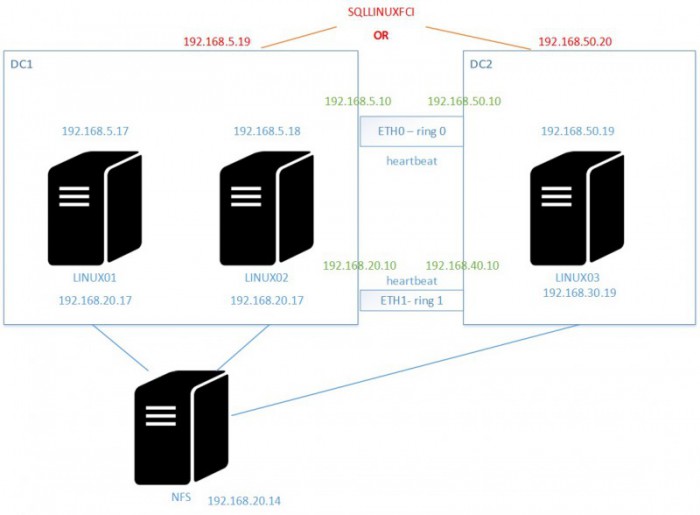
So basically, referring to my previous architecture, the task to perform was as follows:
- Make the initial heartbeat configuration redundant. Even if nowadays having redundant network paths is mostly handled by modern infrastructures and virtualization layers as well, I still believe it is always a best practice to make the heartbeat redundant at the cluster level in order to avoid unexpected behaviors like split brains (for instance with two nodes in this case). I will have the opportunity to talk about quorum stuff in a next post.
- Introduce a third node on a different subnet to the existing architecture and then adding it to the cluster. You may follow the Microsoft documentation to perform this task. The main challenge here was to add the third node in the context of multi-subnet scenario and to ensure the communication path is working well between cluster nodes for both networks (public and private).
- Find a way to make the existing SQL Server FCI resource multi-subnet compliant. I mean to get the same kind of behavior we may have with WSFC on Windows when the resource fails over nodes on different subnets. In this case, we have to configure an OR based resource dependency which includes second virtual address IP.
- Check if applications are able to connect in the context of multi-subnet failover event.
You may notice that I didn’t introduce redundancy at the storage layer. Indeed, the NFS server becomes the SPOF but I didn’t want to make my architecture more complex at all for the moment. In a more realistic scenario at customer shops, this aspect would be probably covered by other storage vendor solutions.
So let’s begin by the heartbeat configuration. According to my existing infrastructure, only one ring was configured and ran on the top of my eth0 interfaces on both nodes ((respectively 192.168.5.17 for the linux01 node and 192.168.5.18 for the linux02 node).
[mikedavem@linux01 ~]$ sudo pcs cluster corosync
…
nodelist {
node {
ring0_addr: linux01.dbi-services.test
nodeid: 1
}
node {
ring0_addr: linux02.dbi-services.test
nodeid: 2
}
}
…
So I added one another network interface (eth1) on each cluster node with a different subnet (192.168.20.0). Those interfaces will be dedicated on running the second Corosync link (ring 2).
- Linux01
[mikedavem@linux01 ~]$ ip addr show eth1
eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:15:5d:00:2b:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.17/24 brd 192.168.20.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fe00:2bd4/64 scope link
valid_lft forever preferred_lft forever
- Linux02
[mikedavem@linux01 ~]$ sudo ssh linux02 ip addr show eth1
…
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:15:5d:00:2b:d5 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.18/24 brd 192.168.20.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::36d8:d6f9:1b7a:cebd/64 scope link
valid_lft forever preferred_lft forever
At this point I binded each new IP address with a corresponding hostname. We may either store the new configuration in the /etc/hosts file or in the DNS server(s).
Then I updated the Corosync.conf on both nodes by adding the new ring configuration as follows. The point here is that configuration changes are not synchronized automatically across nodes like Windows Failover clusters. To allow redundant ring protocol, I added the rrp_mode parameter to be active on both network interfaces (eth0 and eth1) and a new ring section for each node (ring1_addr).
totem {
version: 2
secauth: off
cluster_name: linux_cluster
transport: udpu
rrp_mode: active
}
nodelist {
node {
ring0_addr: linux01.dbi-services.test
ring1_addr: linux01H2.dbi-services.test
nodeid: 1
}
node {
ring0_addr: linux02.dbi-services.test
ring1_addr: linux02H2.dbi-services.test
nodeid: 2
}
}
After restarting the Corosync service on both nodes, I checked the new ring status on both nodes
[mikedavem@linux01 ~]# sudo corosync-cfgtool -s
Printing ring status.
Local node ID 1
RING ID 0
id = 192.168.5.17
status = ring 0 active with no faults
RING ID 1
id = 192.168.20.17
status = Marking seqid 23 ringid 1 interface 192.168.20.17 FAULTY
[root@linux01 ~]#
[root@linux01 ~]# ssh linux02 corosync-cfgtool -s
Printing ring status.
Local node ID 2
RING ID 0
id = 192.168.5.18
status = ring 0 active with no faults
RING ID 1
id = 192.168.20.18
status = ring 1 active with no faults
At this point, my pacemaker cluster was able to use all the network interfaces to execute heartbeat.
In the respect of the Microsoft documentation, I added a new node LINUX03 with the same heartbeat configuration and the general Corosync configuration was updated as follows:
[mikedavem@linux01 ~]# sudo pcs cluster node add linux03.dbi-services.test,linux03H2.dbi-services.testnodelist
…
node {
ring0_addr: linux01.dbi-services.test
ring1_addr: linux01H2.dbi-services.test
nodeid: 1
}
node {
ring0_addr: linux02.dbi-services.test
ring1_addr: linux02H2.dbi-services.test
nodeid: 2
}
node {
ring0_addr: linux03.dbi-services.test
ring1_addr: linux03H2.dbi-services.test
nodeid: 3
}
}
Obviously, communication paths were done successfully after configuring correctly the routes between nodes on different subnets. Corresponding default gateways are already configured for eth0 interfaces but we have to add static routes for eth1 interfaces as shown below:
- LINUX01 and LINUX02 (eth0 – subnet 192.168.5.0 – default gateway 192.168.5.10 / eth1 – subnet 192.168.20.0 – static route to 192.168.30.0 subnet by using 192.168.20.10).
[mikedavem@linux01 ~]$ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.5.10 0.0.0.0 UG 0 0 0 eth0 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 eth1 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 192.168.20.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 192.168.30.0 192.168.20.10 255.255.255.0 UG 0 0 0 eth1
- LINUX03 (eth0 – subnet 192.168.50.0 – default gateway 192.168.50.10 / eth1 – subnet 192.168.30.0 – static route to 192.168.20.0 subnet by using 192.168.30.10).
[mikedavem@linux03 ~]$ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.50.10 0.0.0.0 UG 0 0 0 eth0 0.0.0.0 192.168.50.10 0.0.0.0 UG 100 0 0 eth0 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 192.168.20.0 192.168.30.10 255.255.255.0 UG 100 0 0 eth1 192.168.30.0 0.0.0.0 255.255.255.0 U 100 0 0 eth1 192.168.50.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
Let’s have a look at the cluster status:
[root@linux01 ~]# pcs cluster status Cluster Status: Stack: corosync Current DC: linux01.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - partition with quorum Last updated: Mon Jan 30 12:47:00 2017 Last change: Mon Jan 30 12:45:01 2017 by hacluster via crmd on linux01.dbi-services.test 3 nodes and 3 resources configured PCSD Status: linux01.dbi-services.test: Online linux03.dbi-services.test: Online linux02.dbi-services.test: Online
To enable NFS share to be mounted from the new cluster node LINUX03 on the 192.168.50.0 subnet, we have to add the new configuration in the /etc/exports file and export it afterwards.
[root@nfs ~]# exportfs -rav exporting 192.168.5.0/24:/mnt/sql_log_nfs exporting 192.168.5.0/24:/mnt/sql_data_nfs exporting 192.168.50.0/24:/mnt/sql_data_nfs [root@nfs ~]# showmount -e Export list for nfs.dbi-services.com: /mnt/sql_log_nfs 192.168.5.0/24 /mnt/sql_data_nfs 192.168.50.0/24,192.168.5.0/24
Well, after checking everything is ok from the cluster side, the next challenge was to find a way to configure the SQL Server FCI resource to be multi-subnet compliant. As stated by Microsoft, the SQL Server FCI is not as coupled with Pacemaker add-on as the Windows Failover Cluster. Based on my Windows Failover experience, I wondered if I had to go to the same way with the pacemaker cluster on Linux and I tried to find out a way to add a second VIP and then to include it as part of the OR dependency but I found nothing on this field. But Pacemaker offers concepts which include location / collocation and scores in order to behave on the resources during failover events. My intention is not to go into details trough the pacemaker documentation but by playing with the 3 concepts I was able to address our need. Again please feel free to comments if you have a better method to meet my requirement.
Let’s first add a second virtual IP address for the 192.168.50.0 subnet (virtualipdr) and then let’s add a new dependency / colocation between for SQL Server resource (sqllinuxfci)
[mikedavem@linux01 ~]$sudo pcs cluster cib cfg [mikedavem@linux01 ~]$sudo pcs -f cfg resource create virtualipdr ocf:heartbeat:IPaddr2 ip=192.168.50.20 [mikedavem@linux01 ~]$sudo pcs -f cfg constraint colocation add virtualipdr sqlinuxfci [mikedavem@linux01 ~]$sudo pcs cluster cib-push cfg [mikedavem@linux01 ~]$sudo pcs constraint location
Now to avoid starting virtualip or virtualipdr resources on the wrong subnet, let’s configure an “opt-out” scenario which includes symmetric cluster to allow resources to run everywhere and location constraints to avoid running a resource on a specified location / node.
[mikedavem@linux01 ~]$sudo pcs property set symmetric-cluster=true [mikedavem@linux01 ~]$pcs constraint location virtualipdr avoids linux01.dbi-services.test=-1 [mikedavem@linux01 ~]$pcs constraint location virtualipdr avoids linux02.dbi-services.test=-1 [mikedavem@linux01 ~]$pcs constraint location virtualip avoids linux03.dbi-services.test=-1
The new constraint topology is as follows
[mikedavem@linux01 ~]$ sudo pcs constraint
Location Constraints:
Resource: sqllinuxfci
Enabled on: linux01.dbi-services.test (score:INFINITY) (role: Started)
Resource: virtualip
Disabled on: linux03.dbi-services.test (score:-1)
Resource: virtualipdr
Disabled on: linux01.dbi-services.test (score:-1)
Disabled on: linux02.dbi-services.test (score:-1)
Ordering Constraints:
Colocation Constraints:
FS with sqllinuxfci (score:INFINITY)
virtualip with sqllinuxfci (score:INFINITY)
virtualipdr with sqllinuxfci (score:INFINITY)
Ticket Constraints:
Let’s have a look at the pacemaker status. At this point all SQL Server resources are running on the LINUX01 on the 192.168.5.0 subnet. We may notice the virtualipdr is in stopped state in this case.
[mikedavem@linux01 ~]$ sudo pcs status Cluster name: linux_cluster Stack: corosync Current DC: linux02.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - partition with quorum Last updated: Tue Jan 31 22:28:57 2017 Last change: Mon Jan 30 16:57:10 2017 by root via crm_resource on linux01.dbi-services.test 3 nodes and 4 resources configured Online: [ linux01.dbi-services.test linux02.dbi-services.test linux03.dbi-services.test ] Full list of resources: sqllinuxfci (ocf::mssql:fci): Started linux01.dbi-services.test FS (ocf::heartbeat:Filesystem): Started linux01.dbi-services.test virtualip (ocf::heartbeat:IPaddr2): Started linux01.dbi-services.test virtualipdr (ocf::heartbeat:IPaddr2): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Go ahead and let’s try to move the resources on the LINUX03 node – 192.168.50.0 subnet
[mikedavem@linux01 ~]$ sudo pcs resource move sqllinuxfci linux03.dbi-services.test
The new Pacemarker status becomes
[mikedavem@linux01 ~]$ sudo pcs status Cluster name: linux_cluster Stack: corosync Current DC: linux02.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - partition with quorum Last updated: Tue Jan 31 22:33:21 2017 Last change: Tue Jan 31 22:32:53 2017 by root via crm_resource on linux01.dbi-services.test 3 nodes and 4 resources configured Online: [ linux01.dbi-services.test linux02.dbi-services.test linux03.dbi-services.test ] Full list of resources: sqllinuxfci (ocf::mssql:fci): Stopped FS (ocf::heartbeat:Filesystem): Started linux03.dbi-services.test virtualip (ocf::heartbeat:IPaddr2): Stopped virtualipdr (ocf::heartbeat:IPaddr2): Started linux03.dbi-services.test Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
In turn, the virtualipdr brought online and virtualip brought offline as well because we are now located on the 192.168.50.0 subnet. Here we go!
Ok at this point our SQL Server Failover Cluster Instance seems to behave as expected but how to deal with client connections in this case? If I refer to previous Windows Failover Cluster experiences, I may think about two scenarios by using DNS servers.
- We are able to use SqlClient / JAVA / ODBC support for HA with MultiSubnetFailover parameter on the connection string. In this case good news, we may simply put the both different addresses for the corresponding DNS record and the magic will operate by itself (similar to RegisterAllProvidersIP property with availability groups). The client will reach out automatically the first available address and everything should be fine.
- We cannot modify or use the MultiSubnetFailover and in this case we may setup the TTL value manually for the corresponding DNS record (similar to the HostRecordTTL parameters with availability groups). We will experience timeout issues for the first connection attempt but the second one should work.
- Other scenarios?? Please feel free to comment
In my lab environnement using SqlClient based connections seem to work well in the aforementioned cases. I will perform further tests in a near feature and update this blog accordingly with the results.
I’m looking forward to see other improvements / features with the next SQL Server CTPs
Happy clustering on Linux!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)