A couple of months ago, I did my first installation of SQL Server on Linux. I wrote about it in this blog post. So now it’s time to start the new year by talking about high availability on Linux with SQL Server vNext. Running standalone instances will be suitable for scenarios but I guess introducing high-availability with critical environments still remain mandatory.Currently, the CTP1 supports installing a SQL Server Failover Cluster Instance on the top of RHEL HA Add-on based on Pacemaker. This is a good start although I hope to see also availability groups in the future (maybe a future CTP version). In this blog post I will not go into details of my installation process because some steps will certainly change over the time but I would like to share my notes (or feelings) about this new way to achieve high availability with SQL Server on Linux world.
I performed the installation by using the same infrastructure exposed on the Microsoft documentation. As usual, my environment is fully virtualized with Hyper-V.
So, the first step consisted in installing 3 virtual machines based on a CentOS 7 distribution (the Microsoft documentation is intended to RHEL 7 but CentOS 7 is perfectly suitable in our case). The first two ones concerned the cluster and SQL Server. I performed the same installation process to install SQL Server on Linux. No change here. The third one concerned the NFS server. So let’s show my storage configuration:
[mikedavem@nfs ~]$ sudo fdisk -l | grep -i sd Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors /dev/sda1 * 2048 2099199 1048576 83 Linux /dev/sda2 2099200 41943039 19921920 8e Linux LVM Disk /dev/sdb: 10.7 GB, 10737418240 bytes, 20971520 sectors /dev/sdb1 2048 20971519 10484736 83 Linux Disk /dev/sdc: 10.7 GB, 10737418240 bytes, 20971520 sectors /dev/sdc1 2048 20971519 10484736 83 Linux
The corresponding partition /dev/sdb1 (ext4 formatted) need to be mounted automatically by the system and will be used as a shared storage by the NFS server afterwards.
[mikedavem@nfs ~]$ cat /etc/fstab # # /etc/fstab # Created by anaconda on Thu Jan 12 21:46:34 2017 # … /dev/mapper/cl-root / xfs defaults 0 0 UUID=e4f5fc0b-1fd4-4e18-b655-a76b87778b73 /boot xfs defaults 0 0 /dev/mapper/cl-swap swap swap defaults 0 0 /dev/sdb1 /mnt/sql_data_nfs ext4 auto,user,rw 0 0 /dev/sdc1 /mnt/sql_log_nfs ext4 auto,user,rw 0 0
Then my NFS server will expose the shared directory /mnt/sql_data_nfs to the cluster layer.
[mikedavem@nfs ~]$ cat /etc/exports /mnt/sql_data_nfs 192.168.5.0/24(rw,sync,no_subtree_check,no_root_squash) /mnt/sql_log_nfs 192.168.5.0/24(rw,sync,no_subtree_check,no_root_squash)
We will focus only on the directory /mnt/sql_data_nfs in this case.
[mikedavem@nfs ~]$ showmount -e Export list for nfs.dbi-services.com: /mnt/sql_log_nfs 192.168.5.0/24 /mnt/sql_data_nfs 192.168.5.0/24
That’s it. My directory is ready to be used by my SQL Server cluster nodes as shared storage for my databases. Let’s continue with the second step. We need to install the cluster underlying infrastructure which includes components as Pacemaker (the resource manager) and Corosync (Communication layer between cluster nodes).
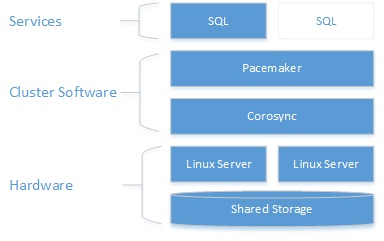
From Microsoft documentation
By reading the Pacemaker documentation on the web, I could find out similar concepts we may have with Microsoft and the Windows Failover Cluster feature. After facing some configuration issues, here my final configuration.
- Two cluster nodes (linux01.dbi-services.test / linux02.dbi-services.test)
- Two resources that concern my SQL Server FCI (sqllinuxfci resource + virtualip resource)
[mikedavem@linux01 ~]$ sudo pcs status Cluster name: linux_cluster Stack: corosync Current DC: linux01.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - partition with quorum Last updated: Sat Jan 14 19:53:55 2017 Last change: Sat Jan 14 17:28:36 2017 by root via crm_resource on linux01.dbi-services.test 2 nodes and 2 resources configured Online: [ linux01.dbi-services.test linux02.dbi-services.test ] Full list of resources: sqllinuxfci (ocf::sql:fci): Started linux02.dbi-services.test virtualip (ocf::heartbeat:IPaddr2): Started linux02.dbi-services.test ... Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
As said previously, I faced some issues during the cluster installation process. The first one concerned a typo in the Microsoft documentation (at least the command did not work in my case). I was not able to create my SQL Server resource after installing the mssql-server-ha package. Indeed, according to Microsoft documentation we need to create a SQL Server resource based on the ocf:mssql:fci resource agent. However, after some investigations, I was able to figure out that this definition doesn’t exist according to the current OCF resource agent folder hierarchy (see below). In my case, I had to change the definition by ocf:sql:fci
[mikedavem@linux01 ~]$ ls -l /usr/lib/ocf/resource.d/ total 16 drwxr-xr-x. 2 root root 4096 Jan 12 19:31 heartbeat drwxr-xr-x. 2 root root 4096 Jan 12 19:31 openstack drwxr-xr-x. 2 root root 4096 Jan 12 19:31 pacemaker drwxr-xr-x. 2 root root 4096 Jan 14 10:55 sql [mikedavem@linux01 ~]$ ls -l /usr/lib/ocf/resource.d/sql/ total 20 -rw-r--r--. 1 root root 3473 Jan 14 10:58 cfg -rwxr-xr-x. 1 root root 15979 Dec 16 02:09 fci
Let’s say it was also a good opportunity to understand what an OCF resource agent is. First coming from the Microsoft world, I figured out quickly the OCF resource agents correspond in fact to what we call the Windows Failover Cluster DLL resources. In addition, according to linux documentation, I noticed similar concepts like functions and entry points that a Windows resource DLL is expected to implement. Very interesting!
The second issue concerned a strange behavior when the failover of my SQL Server resource occurred. I first noticed the following messages:
Failed Actions:
* sqllinuxfci_start_0 on linux02.dbi-services.test ‘unknown error’ (1): call=16, status=complete, exitreason=’SQL server crashed during startup.’,
last-rc-change=’Sat Jan 14 17:35:30 2017′, queued=0ms, exec=34325ms
Then I moved on the SQL Server error log to try to find out some clues about this issue (SQL Server error log is always your friend in this case)
[mikedavem@linux01 sql]$ sudo cat /var/opt/mssql/log/errorlog 2017-01-14 14:38:55.50 spid5s Error: 17204, Severity: 16, State: 1. 2017-01-14 14:38:55.50 spid5s FCB::Open failed: Could not open file C:\var\opt\mssql\data\mastlog.ldf for file number 2. OS error: 2(The system cannot find the file specified.). 2017-01-14 14:38:55.50 spid5s Error: 5120, Severity: 16, State: 101. 2017-01-14 14:38:55.50 spid5s Unable to open the physical file "C:\var\opt\mssql\data\mastlog.ldf". Operating system error 2: "2(The system cannot find the file specified.)". …
That’s the point. My SQL Server engine was not able to open the master database because it can’t find the specified path. As an apart, you may notice the path used by SQL Server in the error message. A Windows fashion path which includes a drive letter! Well, very surprising but I’m sure it will be changed in the near future. For the purpose of my tests, I had no choice to change the folder permission to 777 to expect my SQL Server instance starting well. One point to investigate of course because it will not meet the security policy rules in production environment.
Update 28.01.2017
In fact one important thing to keep in mind is that SQL Server on Linux uses a special mssql user.
[mikedavem@linux01 ~]$ grep mssql /etc/passwd mssql:x:995:993::/var/opt/mssql:/bin/bash
Therefore I modified the permissions as follows:
[mikedavem@linux01 ~]$ sudo chown mssql:mssql /var/opt/mssql/data [mikedavem@linux01 ~]$ sudo chmod 640 /var/opt/mssql/data
The third one concerned IP and hostname resolution. I had to add my cluster IP and hostnames related information into the /etc/hosts file on each cluster node to get it to resolve correctly as follows:
[mikedavem@linux01 sql]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.5.17 linux01.dbi-services.test linux01 192.168.5.18 linux02.dbi-services.test linux02 192.168.5.19 sqllinuxfci.dbi-services.test sqllinuxfci
Finally, after fixing the previous issues, I performed some failover tests (move resources and bring offline a cluster node as well) that ran successfully.
- Move resource
[mikedavem@linux01 sql]$ sudo pcs resource move sqllinuxfci linux01.dbi-services.test [mikedavem@linux01 sql]$ sudo pcs status … 2 nodes and 2 resources configured Online: [ linux01.dbi-services.test linux02.dbi-services.test ] Full list of resources: sqllinuxfci (ocf::sql:fci): Started linux01.dbi-services.test virtualip (ocf::heartbeat:IPaddr2): Started linux01.dbi-services.test
- Simulate failure node LINUX02.dbi-services.test
[mikedavem@linux01 ~]$ sudo pcs status Cluster name: linux_cluster Stack: corosync Current DC: linux01.dbi-services.test (version 1.1.15-11.el7_3.2-e174ec8) - part ition with quorum Last updated: Sun Jan 15 10:59:14 2017 Last change: Sun Jan 15 10:56:54 2017 by root via crm_resource on linux01.dbi-services.test 2 nodes and 2 resources configured Online: [ linux01.dbi-services.test ] OFFLINE: [ linux02.dbi-services.test ] Full list of resources: sqllinuxfci (ocf::sql:fci): Started linux01.dbi-services.test virtualip (ocf::heartbeat:IPaddr2): Started linux01.dbi-services.tes t Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Another “bug” I noticed is that the SERVERPROPERTY() function output does not show correctly the my FCI name. Probably a mistake which will be resolved in the next CTPs. Be patient …

Update 28.01.2017
I got some explanations from Mihaela Blendea (Senior Program Manager at Microsoft) and I also noticed updates from the Microsoft documentation. Currently, SQL Server is not as coupled as with WSFC on Windows. Therefore, the virtual network name is WSFC-specific and there is no equivalent of the same in Pacemaker. This is why I noticed this behavior above.
My final thoughts
Here my feeling after playing a little bit with my new infrastructure.
Based on this first installation, we must face the facts: building a SQL Server FCI infrastructure is a fastest process on Linux in comparison to the same in Windows but I prefer to be prudent and not to draw hasty conclusions. Let’s see what we are going to have in the RTM release. One important thing I noticed for example is there is no explicit cluster validation compared to Windows at least in appearance. In fact, if we take a closer look at the cluster side, we already have some validation steps during the cluster creation (node authentication and cluster setup). However, I didn’t see any validation step at the SQL Server side (compared to Windows) except basic verifications which include verifying the standalones instances are able to start and share the same storage.
Moreover, one another important point we may notice is that we don’t need to setup DNS servers to run the cluster infrastructure. During my tests, I didn’t use it (hostname resolution was made only from /etc/hosts file) but as soon as I had to connect my infrastructure from remote computers, DNS resolution became almost mandatory 🙂
Finally, there is a plenty of tests to perform to understand how behave the cluster layer as well as the cluster resource.
Well, there is still a way to go in order to complete all my work on Linux. To be continued ….
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)