We have now arrived at the end of the largest Oracle OpenWorld ever. Around 45’000 people traveled to San Francisco to exchange on IT and especially Oracle technologies. It has been a great conference with a lot of interesting sessions and several announcements as every year: Enterprise Manager 12c, Exalytics and Oracle Public Cloud.
For my last post on OOW ’11, I want to talk about the last session I attended. Who said that late sessions are usually less interesting? I personally was lucky enough to attend a great presentation held by Oak Table member Alex Gorbachev. Alex used ASM to demonstrate how hardware and software fault tolerance mechanisms, especially mirroring, are affected by different parameters such as MTBF.
Automatic Storage Management concepts
Let’s start with a brief reminder on some ASM principles before diving deeper in fault tolerance.
ASM is the Oracle recommended volume manager and file system. ASM stores database files in so called disk groups. Disk Group are logical collections of physical disk to provide storage units to databases.
Here come the first ASM principle: Stripping
ASM stripping is pretty closed of RAID 0 and aims to load balance I/O across disks and reduce I/O’s latencies. The stripes within ASM are randomly but equally distributed across the disks.
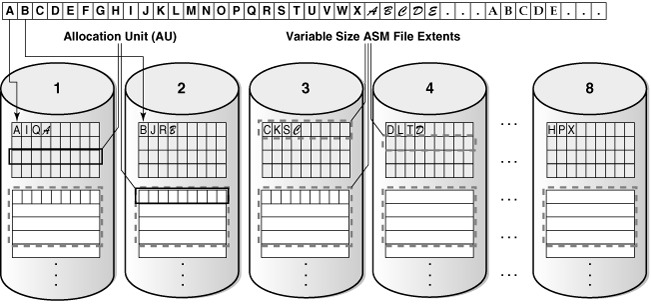
ASM stripping is activated by default and can’t be deactivated.
On top of stripping, ASM integrates the concepts of Mirroring and Failure Groups.
ASM mirroring can of course be configured on disk group level but also fine tuned on file level. There are basically 3 levels of mirroring:
- Normal – “traditional” 2-way mirroring
- High – 3-way mirroring
- External . specifies that the mirroring is handled outside ASM (i.e.: RAID Controller)
ASM mirroring is slightly different than RAID 1. In RAID 1 the copies of the blocks are identical and accessed randomly. In ASM if the content is identical, but there is a primary copy and a mirror copy. Both of them are accessed during write operations, while the read accesses goes by default to the primary copy. In case of an Read I/O error the mirror copy will be accessed. If this works then the primary copy issue will automatically be handled and resolved. Mirror copies are always stored in different Failure Groups than the primary one. Failure Groups are logical collection of disks, which can fail at the same time (i.e.: disks in the same rack).
Within ASM, mirroring is done across all disks of the disk group, unlike RAID 1 which works with pairs of 2 disks. With this principle, each disk is going to share mirrors with all others.
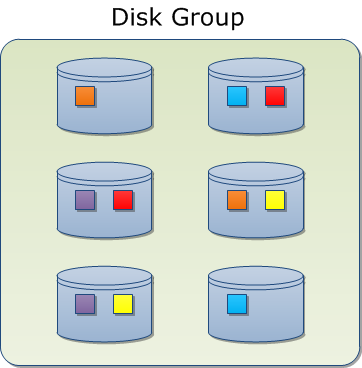
The weak point here is that if you loose 2 disks, you are most likely going to loose data depending on the amount of mirror copies shared between them. Even if using Failure Groups helps reducing this risk, we can see that the amount of disk has a direct impact on the probability of loosing data.
The question is: How can we evaluate this risk?
Probability to survive to a disk failure – Evaluating Murphy’s law for disks
Based on a study of Jehan-François Pâris (University of Houston) and Darell D. E. Long (University of Californa), Using Device Diversity to Protect Data against Batch-Correlated Disk Failures, Alex showed how the risk of losing data in case of 2 simultaneous disk failures can be evaluated.
Basically this value, called Psurv, provides the percent of chances to survive to 2 simultaneous disk failures. It is based on the following information:
- n: number of disks / volume
- λ: rate of failure (1/MTBF)
- Tr: Windows vulnerability (Time to recover)
For the one who are not really sure anymore what is the Mean Time Before Failure (MTBF), you can have a look here: http://en.wikipedia.org/wiki/Mean_time_before_failure
The formula in case of standard 2-way redundancy is:
Psur = exp(-nλTr)
Let’s take an example:
- Case 1: RAID 1
2 disks with MTBF = 1000000 hours
Time to recover 3 hours - Case 2: ASM mirroring
8 disks with MTBF = 1000000 hours
Times to recover 3 hours
Psurv1 = 99,999%
>Psurv2 = 99,997%
We can see that both solution are pretty good. However what happens if we take a failure rate a bit more relevant: 1 failure per week.
Psurv1 = 99,170%
Psurv2 = 96,721%
The gap between RAID 1 and ASM is slowly becoming bigger. And depending on your business (or legal) requirements, this can already be significant.
However, Oracle is aware of the negative impact of having to much disk in a mirroring configuration and therefore has introduced Partnering.
With Partnering, ASM will limit the mirroring on a certain amount of disks called partners. In order to manage these partners, ASM maintains a Partner Status Table (PST). The number of partners is by default limited to 10.
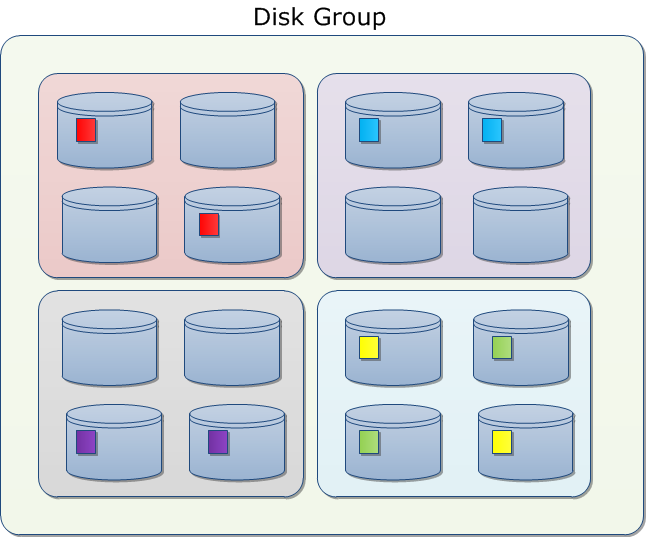
We can now reconsider our previous example.
We have seen that the number of disk was the factor making ASM theoretically less reliable than RAID 1. However this is now partially solved thanks to Partnering. In huge systems like Exadata, we won’t have a disk factor (n) increase from 2 to 100+ but from 2 to 10. Another parameter to take in consideration is that if you have 8 or 10 disks in your mirror, it’s probably going to take less time to rebuild it in case of a disk failure. As a consequence, the Vulnerability Window (Tr) is going to be shorter. Therefore the balance between the number of disk (n) and the Vulnerability Window (Tr) could make ASM even a better solution than RAID 1.
In conclusion, we can see that the paradigm saying that hardware redundancy is more reliable than software redundancy is not true anymore. Finding the best solution will depend on your configuration and also other constraints like performances.
Thanks again to Alex Gorbachev for his presentation at Oracle OpenWorld. Alex’s blog can be found here: http://www.pythian.com/news/author/alex/
Have fun with ASM … and the probabilities 🙄
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DHU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)