![]()
Having worked for several years as an Oracle DBA, I decided to have a look at the PostgreSQL database and see how it functions in comparison to the Oracle Database.
The “Enterprise DB” graphical installation of PostgreSQL 9.3 is quite easy and rather fast. Under Linux you run the graphical installer, dialog boxes lead you through the installation process. You enter the specific information of your system and at the end of the PostgreSQL installation, the Stack Builder package is invoked if you need to install applications, drivers, agents or utilities.
You can download the Enterprise DB utility using the following URL:
http://www.enterprisedb.com/downloads/postgres-postgresql-downloads
I have installed PostgreSQL 9.3 using Enterprise DB as described below:

Choose Next.
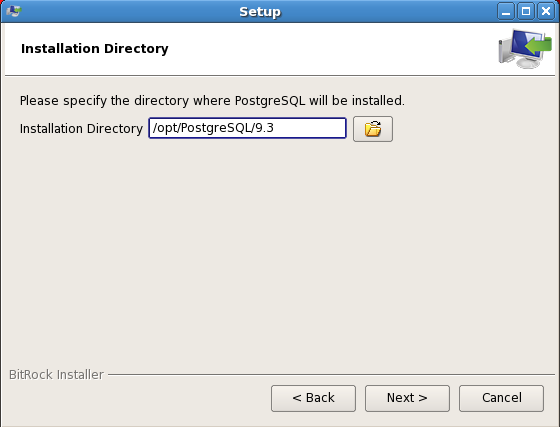
Specify the installation directory where PostgreSQL 9.3 will be installed.
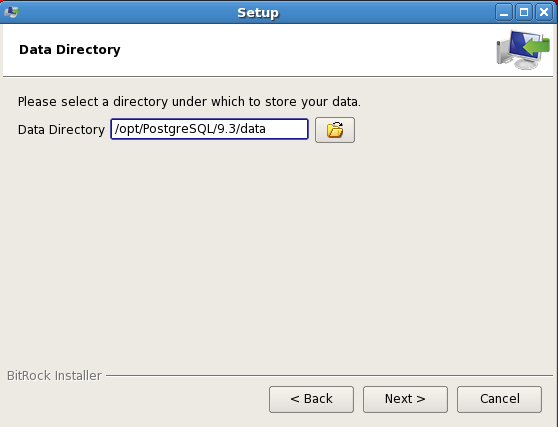
Select the directory that will store the data.
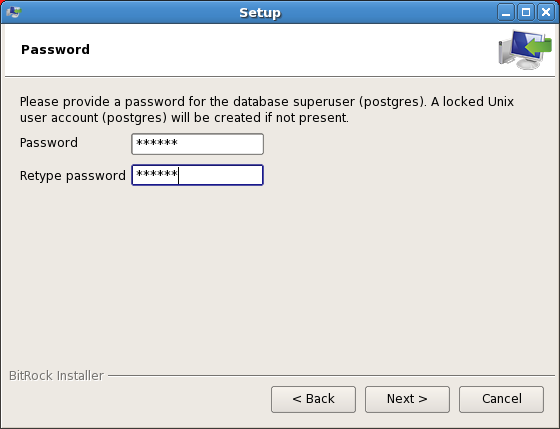
Provide a password to the PostgreSQL database user.
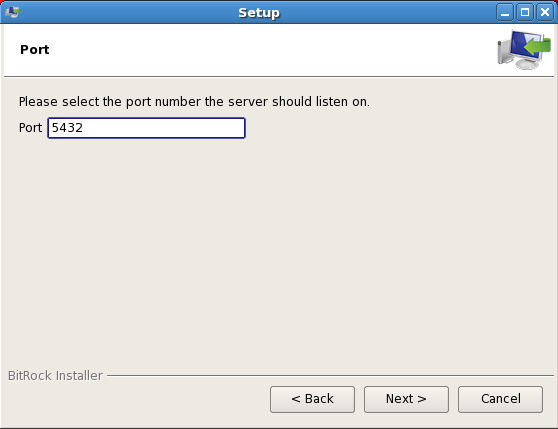
Select a port number.
Choose the locale for the new database cluster.
PostgreSQL is now ready to be installed.

You can choose to launch or not the Stack Builder – if not, the installation process will begin.
If you encounter any problem during the installation phase, the log files are generated in /tmp.
Under Linux, a shell script named uninstall-postgresql is created in the PostgreSQL home directory to de-install the software.
The installation phase is very quick, your PostgreSQL cluster database is ready to use. Furthermore, the Enterprise DB installation creates the automatic startup file in /etc/init.d/postgresql-9.3 to start PostgreSQL in case of a server reboot.
Once the Enterprise DB installation is processed, a database storage area is initialized on disk (a database cluster). After the installation, this database cluster will contain a database named postgres and will be used by utilities or users:
postgres=# list List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges-----------+----------+----------+------------+------------+-------------postgres | postgres | UTF8 | en_US.utf8 | en_US.utf8 |template0 | postgres | UTF8 | en_US.utf8 | en_US.utf8 | =c/postgres + | | | | | postgres=CTc/postgrestemplate1 | postgres | UTF8 | en_US.utf8 | en_US.utf8 | postgres=CTc/postgres+ | | | | | =c/postgres
By default, a new database is created by cloning the system standard base named template1. The template0 allows you to create a database containing only pre-defined standard objects.
The sqlplus oracle equivalent command in PostgreSQL is psql. As you will see in the document, the PostgreSQL commands begin with the sign. The “?” command lists every possibility.
For example, the following commands connects to the psi database:
-bash-3.2$ psql -d psi Password:psql.bin (9.3.4) Type "help" for help.No entry for terminal type "xterm"; using dumb terminal settings. psi=# q
If you do not want the system to ask for a password, you simply have to create a .pgpass file in the postgres home directory with the 0600 rights and the following syntax:
-bash-3.2$ more .pgpass localhost:5432:PSI:postgres:password -bash-3.2$ su - postgres Password: -bash-3.2$ psql -d psi psql.bin (9.3.4) Type "help" for help. No entry for terminal type "xterm"; using dumb terminal settings. psi=# psi-# q
At first you probably need to create a database. As an Oracle DBA, I was wondering about some typical problems such as character set or default tablespace. With PostgreSQL, it is quite easy to create a database.
As the locale en_US.utf8 has been chosen during the installation phase to be used by the cluster database, every database you will create will use it.
When you create a database you can specify a default tablespace and an owner. At first we create a tablespace:
postgres=# create tablespace psi location '/u01/postgres/data/psi'; CREATE TABLESPACE
The tablespace data is located in /u01/postgres/data/psi:
-bash-3.2$ ls PG_9.3_201306121 -bash-3.2$ ls PG_9.3_201306121/ 16526 -bash-3.2$ ls PG_9.3_201306121/16526/ 12547 12587_vm 12624 12663 12728 12773 12547_fsm 12589 12625 12664 12728_fsm 12774 12664_vm 12730 12774_vm 12627 12666 12731 12776
…
Then we create the database:
postgres=# create database psi owner postgres tablespace psi; CREATE DATABASE
We can list all databases with the list command:
postgres=# list List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+------------+------------+------------- postgres | postgres | UTF8 | en_US.utf8 | en_US.utf8 | psi | postgres | UTF8 | en_US.utf8 | en_US.utf8 | template0 | postgres | UTF8 | en_US.utf8 | en_US.utf8 | =c/postgres | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.utf8 | en_US.utf8 | postgres=CTc/postgres+ | | | | | =c/postgres
Now, we can connect to the psi database and create objects, the syntax is quite similar to Oracle:
postgres=# c psi You are now connected to database "psi" as user "postgres".
We create a table and an index:
psi=# create table employe (name varchar); CREATE TABLE psi=# create index employe_ix on employe (name); CREATE INDEX
We insert values in it:
psi=# insert into employe values ('bill');
INSERT 0 1
We reconnect to the psi database:
-bash-3.2$ psql -d psi Password: psql.bin (9.3.4) Type "help" for help. No entry for terminal type "xterm"; using dumb terminal settings.
The following command lists the tables:
psi=# dt[+] List of relations Schema | Name | Type | Owner | Size | Description --------+---------+-------+----------+-------+------------- public | employe | table | postgres | 16 kB | (1 row) psi=# select * from employe; name ------ bill (1 row)
The d+ postgreSQL command is the equivalent of the Oracle desc command:
psi=# d+ employe Table "public.employe" Column | Type | Modifiers | Storage | Stats target | Description --------+-------------------+-----------+----------+--------------+------------- name | character varying | | extended | | Indexes: "employe_ix" btree (name) Has OIDs: no
Obviously we also have the possibility to create a schema and create objects in this schema.
Let’s create a schema:
psi=# create schema psi; CREATE SCHEMA
Let’s create a table, insert objects in it and create a view:
psi=# create table psi.salary (val integer); CREATE TABLE psi=# insert into psi.salary values (10000); INSERT 0 1 psi=# select * from psi.salary; val ------- 10000 psi=# create view psi.v_employe as select * from psi.salary; CREATE VIEW
If we list the tables we can only see the public objects:
psi=# d List of relations Schema | Name | Type | Owner --------+---------+-------+---------- public | employe | table | postgres (1 row)
If we modify the search path, all schemas are visible:
psi=# set search_path to psi,public; SET psi=# d List of relations Schema | Name | Type | Owner --------+---------+-------+---------- psi | salary | table | postgres public | employe | table | postgres
Oracle DBA’s are familiar with sql commands – e. g. to get the table list of a schema by typing select table_name, owner from user_tables, etc.
What is the equivalent query in postgreSQL?
PostgreSQL uses a schema named information_schema available in every database. The owner of this schema is the initial database user in the cluster. You can drop this schema, but the space saving is negligible.
You can easily query the tables of this schema to get precious informations about your database objects:
Here is a list of the schemas tables:
psi=# select table_name, table_schema from information_schema.tables where table_schema in ('public','psi');
table_name | table_schema
------------+--------------
employe | public
salary | psi
We can display the database character set:
psi=# select character_set_name from information_schema.character_sets; character_set_name -------------------- UTF8
We can display schema views:
psi=# select table_name from information_schema.views where table_schema='psi'; table_name ------------ v_employe
Using the information_schema schema helps us to display information about a lot of different database objects (tables, constraints, sequences, triggers, table_privileges …)
Like in Oracle you can run a query from the SQL or the UNIX prompt. For example, if you want to know the index name of the table employe, you shoud use the index.sql script:
select t.relname as table_name, i.relname as index_name, a.attname as column_name from pg_class t,pg_class i, pg_index ix,pg_attribute a wheret.oid = ix.indrelid and i.oid = ix.indexrelid and a.attrelid = t.oid and a.attnum = ANY(ix.indkey) and t.relkind = 'r' and t.relname = 'employe' order byt.relname,i.relname;
If you want to display the employee index from the SQL prompt, you run:
psi=# i index.sql table_name | index_name | column_name ------------+------------+------------- employe | employe_ix | name If you want to run the same query from the UNIX prompt: -bash-3.2$ psql -d psi -a -f index.sql Password: table_name | index_name | column_name ------------+------------+------------- employe | employe_ix | name
However, typing an SQL request might be interesting, but – as many Oracle DBA – I like using an administration console because I think it increases efficiency.
I have discovered pgAdmin, an administration tool designed for Unix or Windows systems. pgAdmin is easy to install on a PostgreSQL environment and enables many operations for the administration of a cluster database.
pgAdmin3 is installed in the home directory of the user postgre – in my case in /opt/postgres/9.3.
To successfully enable pgAdmin3, it is necessary to correctly initialize the LD_LIBRARY_PATH variable:
export LD_LIBRARY_PATH=/opt/PostgreSQL/9.3/lib:/opt/PostgreSQL/9.3/pgAdmin3/lib
The pgadmin3 console:
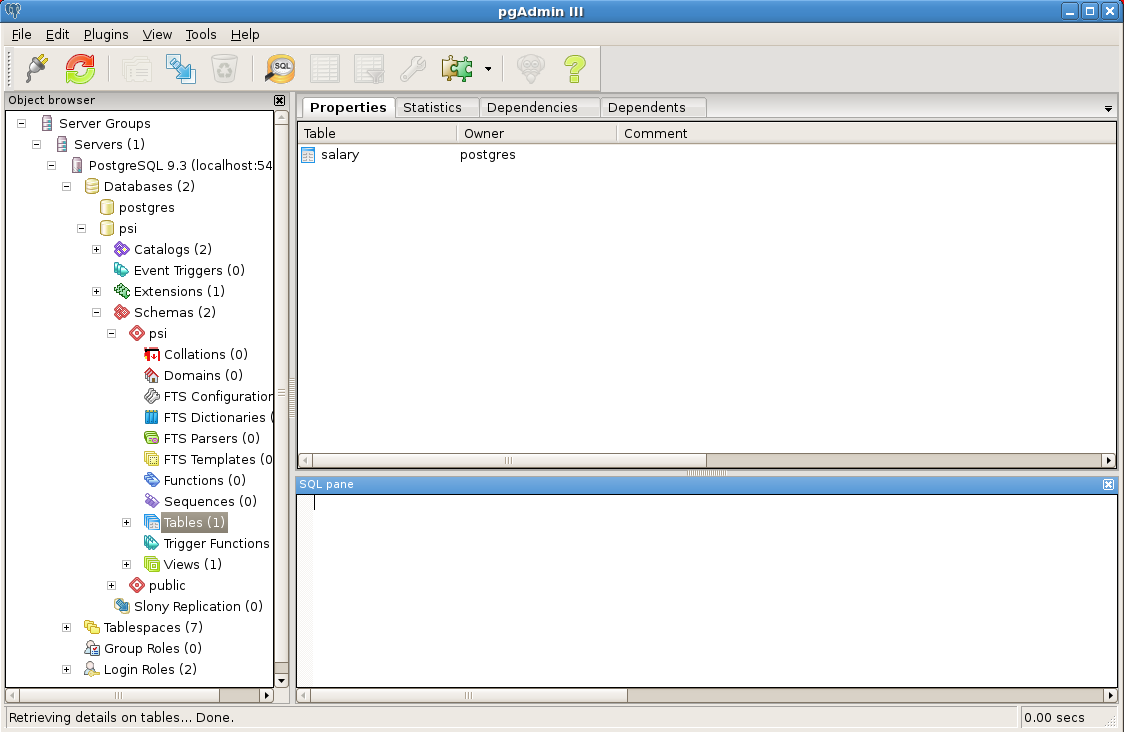
As you can see, you can administer every database object (tables, functions, sequences, triggers, views…).
You can visualize the table creation scripts:
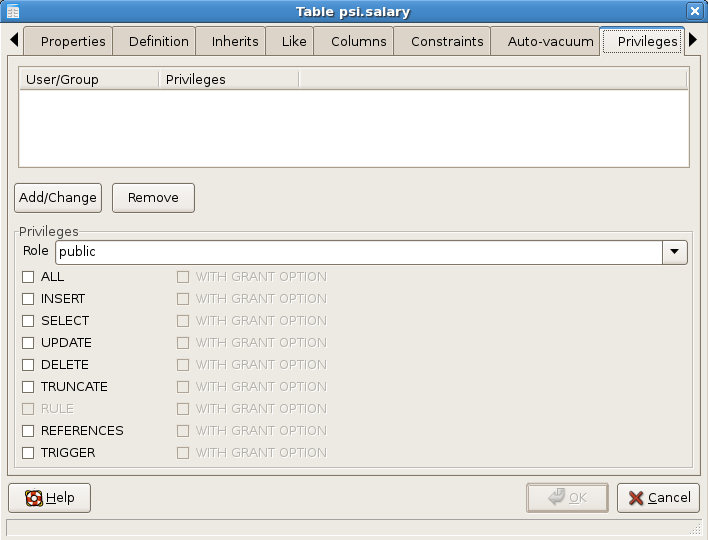
You can edit / change / modify the privileges of an object:
You also have the possibility to create scripst for the database creation:
Or even to backup the database:
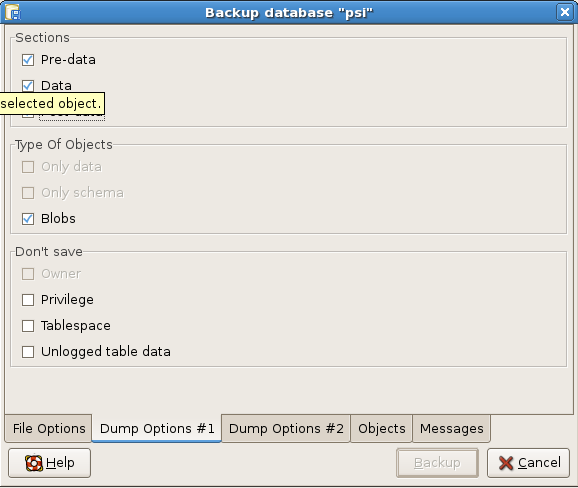
This tool seems to be very powerful, even if for the moment, I did not find any performance tool available like in Cloud Control 12c.
Conclusion
Discovering PostgreSQL as an Oracle DBA, I realized how close the two products are. The PostgreSQL database has a lot of advantages such as the easy installation, the general usage and the price (because it’s free!).
For the processing of huge amounts of data, Oracle certainly has advantages, nevertheless the choice of a RDBMS always depends on what your application business needs are.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ALN_web-min-scaled.jpg)