By Franck Pachot
What I want to show in this blog post is that, as in mathematics where you have to apply some algebra rules to transform an equation to an equivalent one, the database developer must translate the business specification to an equivalent that is optimized (in performance, reliability and readability) for the data model.
I was looking at the Sakila sample database provided with MySQL. It simulates a DVD rental store. For my younger readers who wonder what this is, you can imagine a pre-Netflix generation where, when you want to watch a movie, you read it from a storage media that you bring at home, rather than streaming it through the internet from a distant data center. I’ll write someday about how this Netflix approach, while being more agile (you choose a movie and can watch it immediately – on demand) is a terrible resource consumption design which, in my opinion, is not sustainable. This DVD vs. Netflix example may be good to introduce data gravity, and processing data in the database. But that’s not the topic here. Or maybe it is because I’ll talk about optimization, and stored procedure…
I have installed MySQL in my Oracle Cloud Free Tier instance (Oracle Linux 7) with the following:
sudo yum install -y https://yum.oracle.com/repo/OracleLinux/OL7/MySQL80_community/x86_64/getPackage/mysql-community-devel-8.0.19-1.el7.x86_64.rpm
sudo systemctl start mysqld.service
mysql -uroot -p
mysql --connect-expired-password --user=root \
--password=$(sudo awk '/temporary password/{print $NF}' /var/log/mysqld.log) \
-e "alter user 'root'@'localhost' identified by '2020 @FranckPachot';"
Then I have downloaded and run the Sakila sample database installation:
curl https://downloads.mysql.com/docs/sakila-db.tar.gz | tar -xzvf - -C /var/tmp
mysql --user=root --password='2020 @FranckPachot' < /var/tmp/sakila-db/sakila-schema.sql
mysql --user=root --password='2020 @FranckPachot' < /var/tmp/sakila-db/sakila-data.sql
And I was looking at the example in the documentation: https://dev.mysql.com/doc/sakila/en/sakila-usage.html#sakila-usage-rent-a-dvd which starts the “Rent a DVD” use-case by checking if the DVD is available in stock:
mysql> SELECT inventory_in_stock(10);
+------------------------+
| inventory_in_stock(10) |
+------------------------+
| 1 |
+------------------------+
This function is defined as:
DELIMITER $$
CREATE FUNCTION inventory_in_stock(p_inventory_id INT) RETURNS BOOLEAN
READS SQL DATA
BEGIN
DECLARE v_rentals INT;
DECLARE v_out INT;
#AN ITEM IS IN-STOCK IF THERE ARE EITHER NO ROWS IN THE rental TABLE
#FOR THE ITEM OR ALL ROWS HAVE return_date POPULATED
SELECT COUNT(*) INTO v_rentals
FROM rental
WHERE inventory_id = p_inventory_id;
IF v_rentals = 0 THEN
RETURN TRUE;
END IF;
SELECT COUNT(rental_id) INTO v_out
FROM inventory LEFT JOIN rental USING(inventory_id)
WHERE inventory.inventory_id = p_inventory_id
AND rental.return_date IS NULL;
IF v_out > 0 THEN
RETURN FALSE;
ELSE
RETURN TRUE;
END IF;
END $$
DELIMITER ;
I was really surprised by the complexity of this: 2 queries in a procedural function for something that I expect to be just a simple SQL query. I guess the purpose was to show what can be done within a procedure but it is a very bad example for people starting with SQL. At least the comment is clear:
#AN ITEM IS IN-STOCK IF THERE ARE EITHER NO ROWS IN THE rental TABLE
#FOR THE ITEM OR ALL ROWS HAVE return_date POPULATED
But the code seems to be a one-to-one translation of this sentence to procedural code. And as I mentioned in the introduction, this may have to be worded differently to be optimized. And we must be sure, of course, that the transformation is a functional equivalent. This is called “refactoring”.
Prefer SQL to procedural language
There are several reasons we should prefer one SQL query, when possible, to procedural code. First, because different languages are usually executed in a different engine, and that means context switch and passing parameters. Second, when you run everything as a SQL query, your modules (should I say microservices?) can be merged as a subquery in the calling statement and the query planner can go further to optimize it as a whole. And then you have the advantage of both worlds: the performance of monoliths with the agility of micro-services.
In addition to that, you may think that procedural code is easier to read and evolve, but it is actually the opposite. This impression comes probably from the way IT is learned at school. Students learn a lot of 3rd generation languages (procedural), as interpreted scripts or compiled programs. When I was at university I also learned some 4th generation (declarative) languages like Prolog and, of course, SQL. But this is, in my opinion, neglected today. The language is not important but the logic is. A declarative language is like a math formula: probably difficult to start with, because of the high level of abstraction. But then, once the logic is understood, it because obvious and error-safe. In today’s developer life, this means: more errors encountered before arriving to a solution, but fewer bugs and side effects once the solution is found.
There’s another reason to prefer one SQL statement rather than many in a procedure. The latter may have its behavior depending on the isolation level, and you may have to think about exception handling. A SQL statement is always atomic and consistent.
Static analysis
I’ll re-write this function as a simple query and, before looking at the dynamic of the procedural language, I’m looking at bounding the scope: the tables and columns used. This will help to define the tests that should cover all possibilities.
The function reads two tables: the INVENTORY (one row per DVD) and RENTAL (one row per rent transaction). On INVENTORY we check only the presence of the INVENTORY_ID. On RENTAL we check the presence of the INVENTORY_ID and we also check the presence of a RETURN_DATE to know if it is back to the stock.
Define the tests
When I refactor an existing function, the improved performance is only the secondary goal. The first goal is to be sure that my new proposal is functionally equivalent to the existing one. Then, it is critical to build the tests to validate this.
I’ll use the same item, inventory_id=10, and update the tables to get all variations. I’ll rollback between each and then I must disable autocommit:
--------------
set autocommit=0
--------------This DVD, in the initial state of the sample database, has been rented 3 times and is now back in the stock (all rentals have a return date):
--------------
select * from inventory where inventory_id=10
--------------
+--------------+---------+----------+---------------------+
| inventory_id | film_id | store_id | last_update |
+--------------+---------+----------+---------------------+
| 10 | 2 | 2 | 2006-02-15 05:09:17 |
+--------------+---------+----------+---------------------+
--------------
select * from rental where inventory_id=10
--------------
+-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+
| rental_id | rental_date | inventory_id | customer_id | return_date | staff_id | last_update |
+-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+
| 4364 | 2005-07-07 19:46:51 | 10 | 145 | 2005-07-08 21:55:51 | 1 | 2006-02-15 21:30:53 |
| 7733 | 2005-07-28 05:04:47 | 10 | 82 | 2005-08-05 05:12:47 | 2 | 2006-02-15 21:30:53 |
| 15218 | 2005-08-22 16:59:05 | 10 | 139 | 2005-08-30 17:01:05 | 1 | 2006-02-15 21:30:53 |
+-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+The INVENTORY_IN_STOCK function returns “true” in this case:
--------------
SELECT inventory_in_stock(10)
--------------
+------------------------+
| inventory_in_stock(10) |
+------------------------+
| 1 |
+------------------------+My second test simulates a rental that is not yet returned, by setting the last RENTAL_DATE to null:
--------------
update rental set return_date=null where inventory_id=10 and rental_id=15218
--------------
--------------
select * from inventory where inventory_id=10
--------------
+--------------+---------+----------+---------------------+
| inventory_id | film_id | store_id | last_update |
+--------------+---------+----------+---------------------+
| 10 | 2 | 2 | 2006-02-15 05:09:17 |
+--------------+---------+----------+---------------------+
--------------
select * from rental where inventory_id=10
--------------
+-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+
| rental_id | rental_date | inventory_id | customer_id | return_date | staff_id | last_update |
+-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+
| 4364 | 2005-07-07 19:46:51 | 10 | 145 | 2005-07-08 21:55:51 | 1 | 2006-02-15 21:30:53 |
| 7733 | 2005-07-28 05:04:47 | 10 | 82 | 2005-08-05 05:12:47 | 2 | 2006-02-15 21:30:53 |
| 15218 | 2005-08-22 16:59:05 | 10 | 139 | NULL | 1 | 2020-02-29 22:27:15 |
+-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+There, the INVENTORY_IN_STOCK returns “false” because the DVD is out:
--------------
SELECT inventory_in_stock(10)
--------------
+------------------------+
| inventory_in_stock(10) |
+------------------------+
| 0 |
+------------------------+My third test simulates a case that should not happen: multiple rentals not returned. If this exists in the database, it can be considered as corrupted data because we should not be able to rent a DVD that was not returned from the previous rental. But when I replace a function with a new version, I want to be sure that the behavior is the same even in case of a bug.
--------------
rollback
--------------
--------------
update rental set return_date=null where inventory_id=10
--------------
--------------
select * from inventory where inventory_id=10
--------------
+--------------+---------+----------+---------------------+
| inventory_id | film_id | store_id | last_update |
+--------------+---------+----------+---------------------+
| 10 | 2 | 2 | 2006-02-15 05:09:17 |
+--------------+---------+----------+---------------------+
--------------
select * from rental where inventory_id=10
--------------
+-----------+---------------------+--------------+-------------+-------------+----------+---------------------+
| rental_id | rental_date | inventory_id | customer_id | return_date | staff_id | last_update |
+-----------+---------------------+--------------+-------------+-------------+----------+---------------------+
| 4364 | 2005-07-07 19:46:51 | 10 | 145 | NULL | 1 | 2020-02-29 22:27:16 |
| 7733 | 2005-07-28 05:04:47 | 10 | 82 | NULL | 2 | 2020-02-29 22:27:16 |
| 15218 | 2005-08-22 16:59:05 | 10 | 139 | NULL | 1 | 2020-02-29 22:27:16 |
+-----------+---------------------+--------------+-------------+-------------+----------+---------------------+
--------------
SELECT inventory_in_stock(10)
--------------
+------------------------+
| inventory_in_stock(10) |
+------------------------+
| 0 |
+------------------------+This returns “false” for the presence in the stock and I want to return the same in my new function.
I will not test the case where rentals exists but the DVD is not in the inventory because this situation cannot happen thanks to referential integrity constraints:
--------------
delete from inventory
--------------
ERROR 1451 (23000) at line 130 in file: 'sakila-mysql.sql': Cannot delete or update a parent row: a foreign key constraint fails (`sakila`.`rental`, CONSTRAINT `fk_rental_inventory` FOREIGN KEY (`inventory_id`) REFERENCES `inventory` (`inventory_id`) ON DELETE RESTRICT ON UPDATE CASCADE)
The next test is about an item which never had any rental:
--------------
rollback
--------------
--------------
delete from rental where inventory_id=10
--------------
--------------
select * from inventory where inventory_id=10
--------------
+--------------+---------+----------+---------------------+
| inventory_id | film_id | store_id | last_update |
+--------------+---------+----------+---------------------+
| 10 | 2 | 2 | 2006-02-15 05:09:17 |
+--------------+---------+----------+---------------------+
--------------
select * from rental where inventory_id=10
--------------
This means that the DVD is available in the stock:
--------------
SELECT inventory_in_stock(10)
--------------
+------------------------+
| inventory_in_stock(10) |
+------------------------+
| 1 |
+------------------------+One situation remains: the item is not in the inventory and has no rows in RENTAL:
--------------
delete from inventory where inventory_id=10
--------------
--------------
select * from inventory where inventory_id=10
--------------
--------------
select * from rental where inventory_id=10
--------------
--------------
SELECT inventory_in_stock(10)
--------------
+------------------------+
| inventory_in_stock(10) |
+------------------------+
| 1 |
+------------------------+For this one, the INVENTORY_IN_STOCK defined in the Sakila sample database returns “true” as if we can rent a DVD that is not in the inventory. Probably the situation has a low probability to be encountered because the application cannot get an INVENTORY_ID if the row is not in the inventory. But a function should be correct in all cases without any guess on the context where it is called. Are you sure that some concurrent modification cannot encounter this case: one user removing a DVD and another accepting to rent it at the same time? That’s the problem with procedural code: it is very hard to ensure that we cover all cases that can happen with various loops and branches. With declarative code like SQL, because it follows a declarative logic, the risk is lower.
For this refactoring, I’ll make sure that I have the same result even if I think this is a bug. Anyway, it is easy to add a join to INVENTORY if we want to fix this.
--------------
rollback
--------------Single SQL for the same logic
The function returns “true”, meaning that the item is in-stock, when there are no rows in RENTAL (never rented) or if all rows in RENTAL have the RETURN_DATE populated (meaning that it is back to stock).
The Sakila author has implemented those two situations as two queries but that is not needed. I’ll show a few alternatives, all in one SQL query.
NOT EXISTS
“All row in RENTAL have RETURN_DATE not null” can be translated to “no row in RENTAL where RETURN_DATE is null” and that can be implemented with a NOT EXISTS subquery. This also covers the case where there’s no row at all in RENTAL:
select not exists (
select 1 from rental where rental.inventory_id=10
and return_date is null
);
This returns the same true/false value as the INVENTORY_IN_STOCK function. But the parameter for inventory_id must be present in the query (the value 10 here) and this still needs to call a procedure because MySQL has no parameterized views.
NOT IN
A similar query can use NOT IN to return “false” as soon as there is a rental that was not returned:
select (10) not in (
select inventory_id from rental where return_date is null
);The advantage here is that the parameter (the value 10 here) is outside of the subquery.
VIEW TO ANTI-JOIN
Then, the subquery can be defined as a view where the logic (the return_date being null) is encapsulated and usable in many places:
create or replace view v_out_of_stock as
select inventory_id from rental where return_date is null;
And we can use it from another query (probably a query that gets the INVENTORY_ID by its name) with a simple anti-join:
select (10) not in (
select inventory_id from v_out_of_stock
);
VIEW TO JOIN
If you prefer a view to join to (rather than anti-join), you can add the INVENTORY table into the view. But then, you will have a different result in the case where the inventory_id does not exist (where I think the Sakila function is not correct).
create or replace view v_inventory_instock as
select inventory_id from inventory
where inventory_id not in (
select inventory_id from rental where return_date is null
);
Then is you are coming from INVENTORY you can simply join to this view:
select '=== not same in view',(10) in (
select inventory_id from inventory natural join v_inventory_instock
);
I used a natural join because I know there is only one column, but be careful with that. In doubt just join with a USING clause.
Of course this may read the INVENTORY table two times because the MySQL optimizer does not detect that this join can be eliminated:
explain
select * from inventory natural join v_inventory_instock where inventory_id=10
--------------
+----+-------------+-----------+------------+-------+---------------------+---------------------+---------+-------+------+----------+-------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------------+---------------------+---------+-------+------+----------+-------------------------+
| 1 | SIMPLE | inventory | NULL | const | PRIMARY | PRIMARY | 3 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | inventory | NULL | const | PRIMARY | PRIMARY | 3 | const | 1 | 100.00 | Using index |
| 1 | SIMPLE | rental | NULL | ref | idx_fk_inventory_id | idx_fk_inventory_id | 3 | const | 3 | 100.00 | Using where; Not exists |
+----+-------------+-----------+------------+-------+---------------------+---------------------+---------+-------+------+----------+-------------------------+
However, this is still cheaper than calling a function. And you may prefer to create the in-stock view with all the columns from INVENTORY and then don’t have to join to it.
COUNT
If you prefer a COUNT rather than an EXISTS like what was done in the Sakila function, you can compare the number of rentals with the number of returns:
select count(rental_date)=count(return_date) from rental where inventory_id=10 ;
This works as well with no rentals as the count is at zero for both. However, leaves less possibilities to the optimizer. With a ‘NOT IN’ the scan of all rentals can stop as soon as a row is encountered. With a COUNT all rows will be read.
Performance
As the Sakila function is designed, taking an INVENTORY_ID as input, there are good chances that the application calls this function after a visit to the INVENTORY table.
You can test this with the original Sakila sample database with just the additional following view which lists the inventory_id with the in-stock status
create or replace view v_inventory_stock_status as
select inventory_id, inventory_id not in (
select inventory_id from rental where return_date is null
) inventory_in_stock
from inventory
;
I have run the following to get the execution time when checking the in-stock status for each inventory item:
time mysql --user=root --password='2020 @FranckPachot' -bve "
use sakila;
select count(*),inventory_in_stock(inventory_id)
from inventory
group by inventory_in_stock(inventory_id);"
--------------
select count(*),inventory_in_stock(inventory_id) from inventory group by inventory_in_stock(inventory_id)
--------------
+----------+----------------------------------+
| count(*) | inventory_in_stock(inventory_id) |
+----------+----------------------------------+
| 4398 | 1 |
| 183 | 0 |
+----------+----------------------------------+
real 0m2.272s
user 0m0.005s
sys 0m0.002s
2 seconds for those 4581 calls to the inventory_in_stock() function, which itself has executed one or two queries.
Now here is the same group by using an outer join to my view:
time mysql --user=root --password='2020 @FranckPachot' -bve "
use sakila;
select count(inventory_id),inventory_in_stock
from inventory
natural left outer join v_inventory_stock_status
group by inventory_in_stock;"
select count(inventory_id),inventory_in_stock
from inventory
natural left outer join v_inventory_stock_status
group by inventory_in_stock
--------------
+---------------------+--------------------+
| count(inventory_id) | inventory_in_stock |
+---------------------+--------------------+
| 4398 | 1 |
| 183 | 0 |
+---------------------+--------------------+
real 0m0.107s
user 0m0.005s
sys 0m0.001s
Of course, the timings here are there only to show the idea.
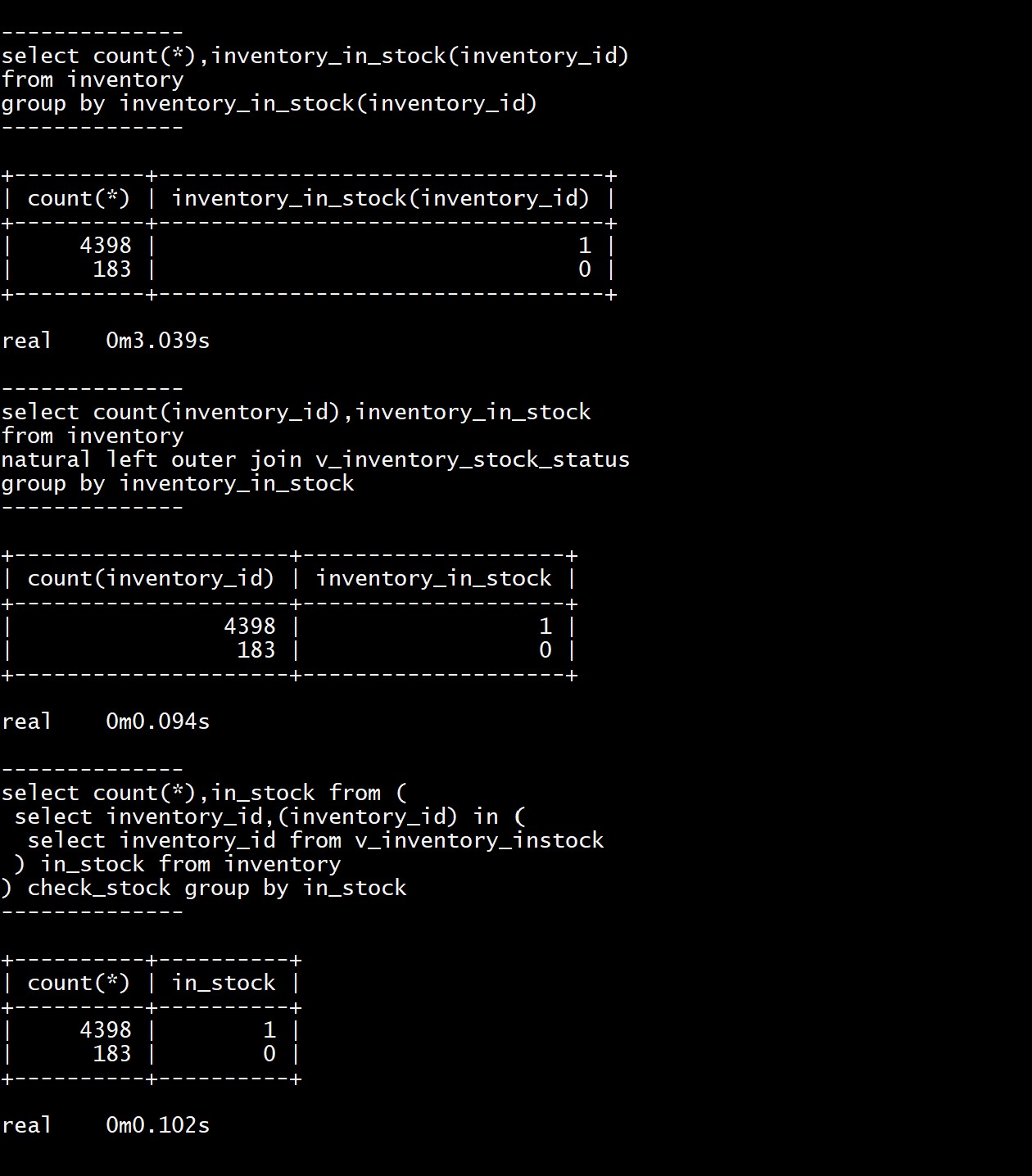
You can test the same in your environment, and profile it to understand the overhead behind the recursive calls to the procedure and to its SQL statements. Stored procedures and functions are nice to provide an API to your database. It is ok to execute one per user call. But when you get the parameters from a SQL statement (INVENTORY_ID here) and call a function which itself executes some other SQL statements you go to poor performance and non-scalable design. When you can refactor the functions to replace them by views you keep the same maintainability with reusable modules, and you also give to the SQL optimizer a subquery that can be merged in a calling SQL statement. A join will always be faster than calling a function that executes another SQL statement.
The idea here is common to all databases, but other database engines may have better solutions. PostgreSQL can inline functions that are defined in “language SQL” and this can be used as a parameterized view. Oracle 20c introduces SQL Macros which are like a SQL preprocessor where the function returns a SQL clause rather than computing the result.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/05/open-source-author.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/NME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/STS_web-min-scaled.jpg)