From time to time you might require to reboot your AWS instances. Maye you applied some patches or for whatever reason. Rebooting an AWS instance can be done in several ways: You can of course do that directly from the AWS console. You can use the AWS command line utilities as well. If you want to schedule a reboot you can either do that using CloudWatch or you can use SSM Maintenance Windows for that. In this post we will only look at CloudWatch and System Manager as these two can be used to schedule the reboot easily using AWS native utilities. You could, of course, do that as well by using cron and the AWS command line utilities but this is not the scope of this post.
For CloudWatch the procedure for rebooting instances is the following: Create a new rule:
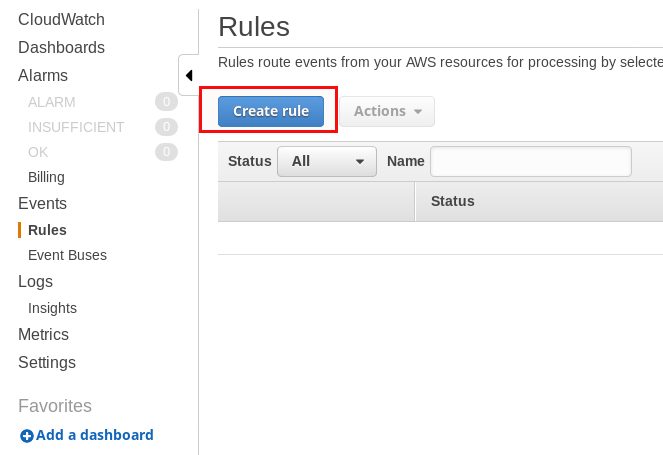
Go for “Schedule” and give a cron expression. In this case it means: 16-July-2019 at 07:45. Select the “EC2 RebootInstances API call” and provide the instance IDs you want to have rebooted. There is one limitation: You can only add up to five targets. If you need more then you have to use System Manager as described later in this post. You should pre-create an IAM role with sufficient permissions which you can use for this as otherwise a new one will be created each time.
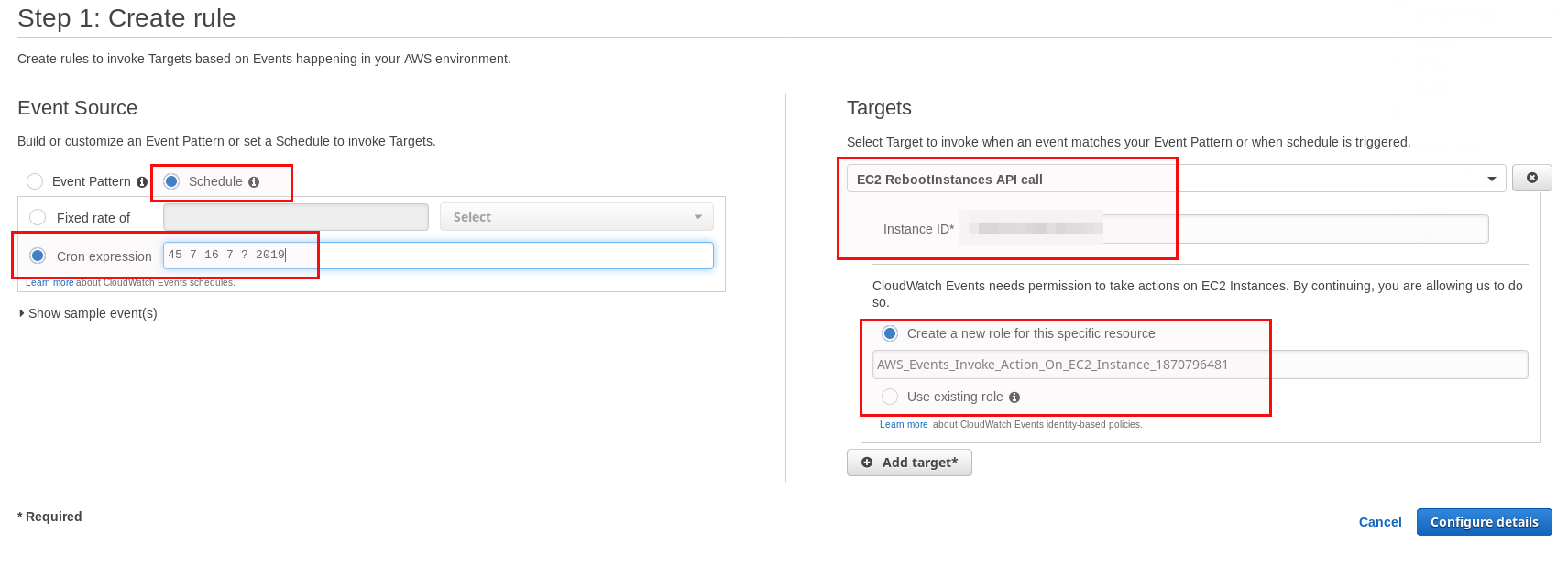
Finally give a name and a description, that’s it:

Once time reaches your cron expression target the instance(s) will reboot.
The other solution for scheduling stuff against many instances is to use AWS SSM. It requires a bit more preparation work but in the end this is the solution we decided to go for as more instances can be scheduled with one maintenance window (up to 50) and you could combine several tasks, e.g. executing something before doing the reboot and do something else after the reboot.
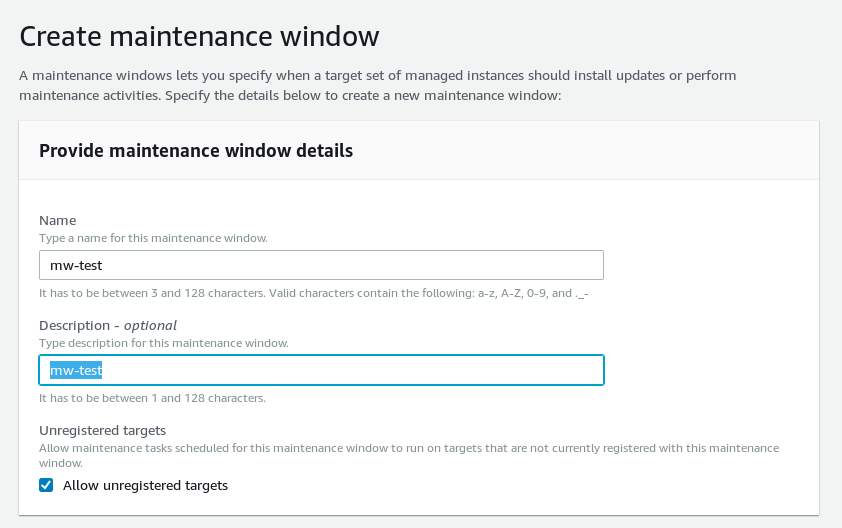
The first step is to create a new maintenance window:

Of course it needs a name and an optional description:
Again, in this example, we use a cron expression for the scheduling (some as above in the CloudWatch example). Be aware that this is UTC time:
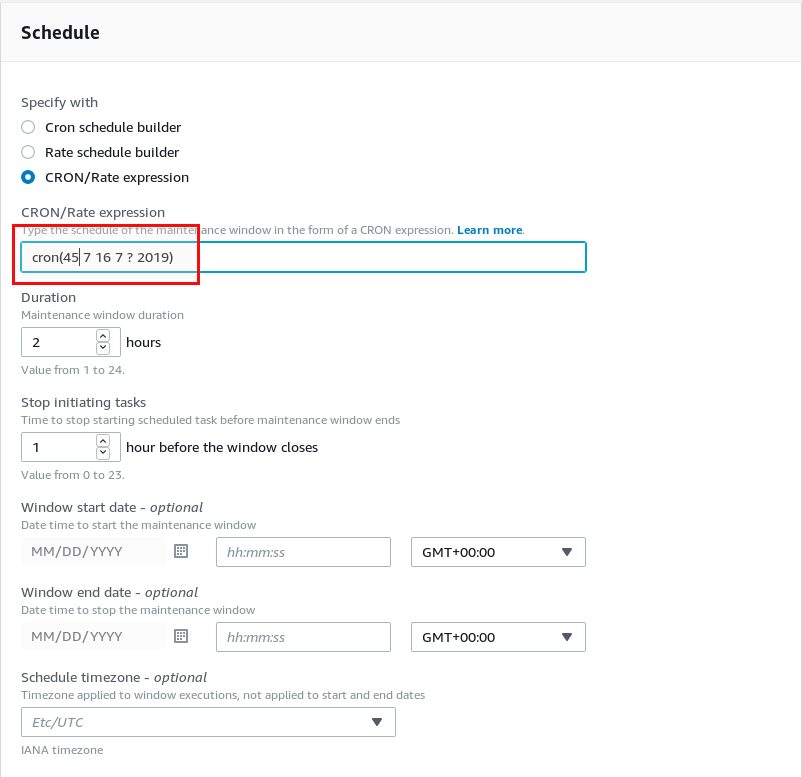
Once the maintenance window is created we need to attach a task to it. Until now we only specified a time to run something but we did not specify what to run. Attaching a task can be done in the task section of the maintenance window:
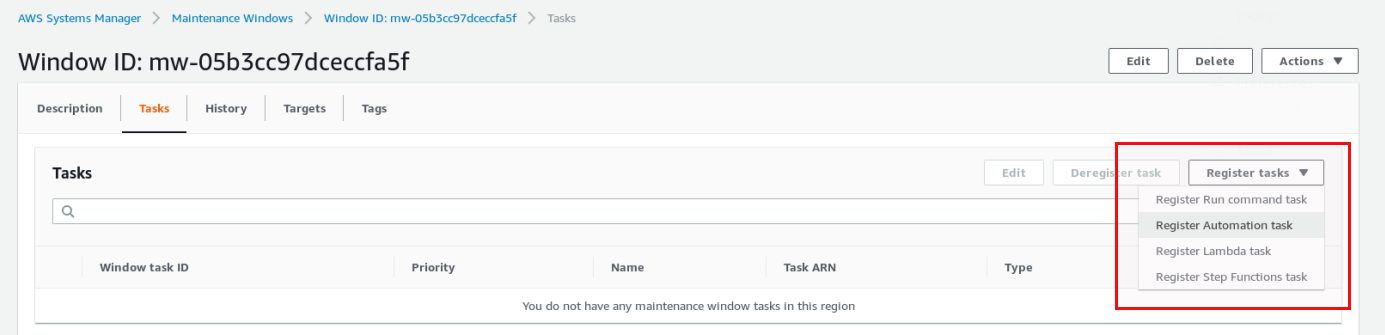
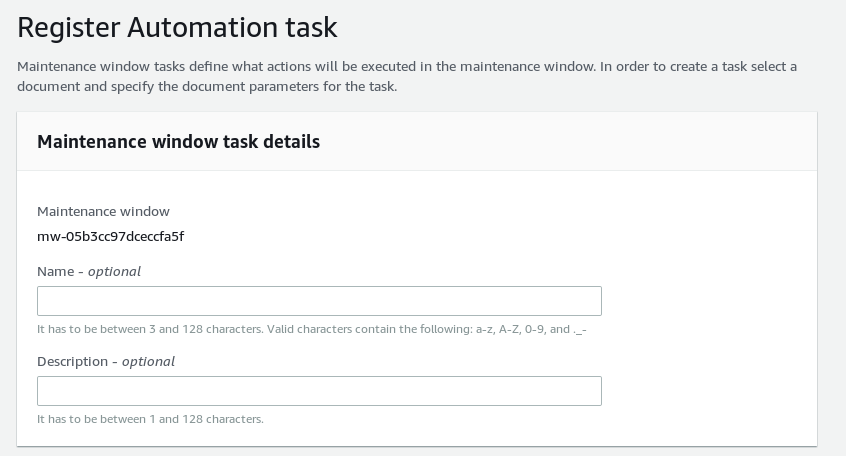
In this case we go for an “Automation task”. Name and description are not required:
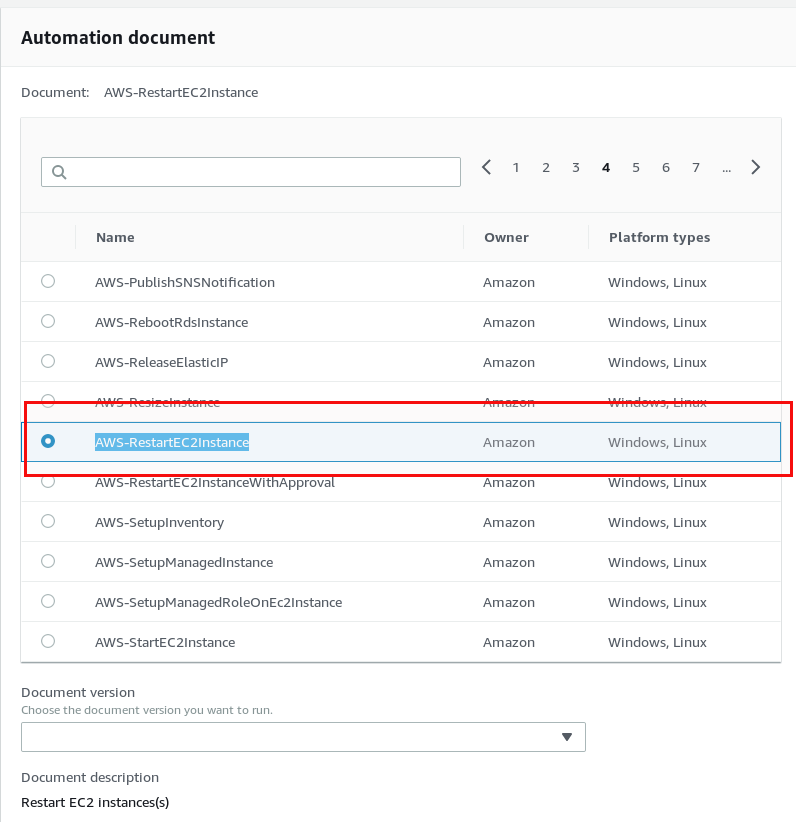
The important part is the document to run, in our case it is “AWS-RestartEC2Instance”:
Choose the instances you want to run the document against:
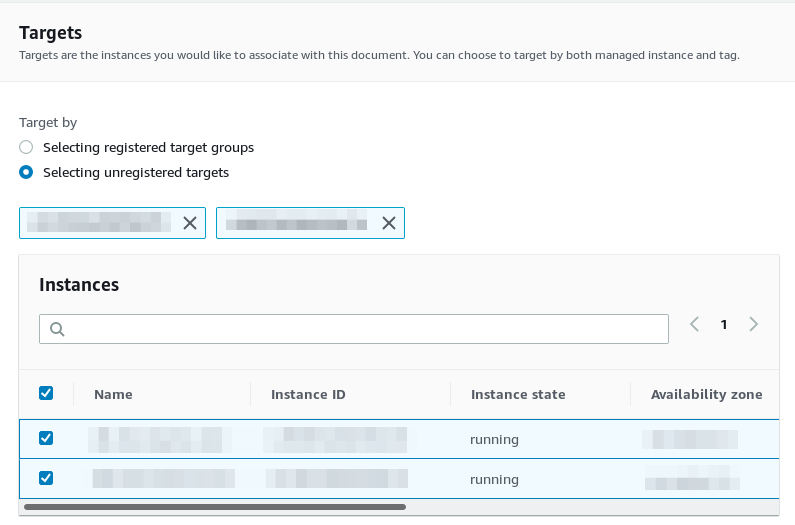
And finally specify the concurrency and error count and again, an IAM role with sufficient permissions to perform the actions defined in the document:
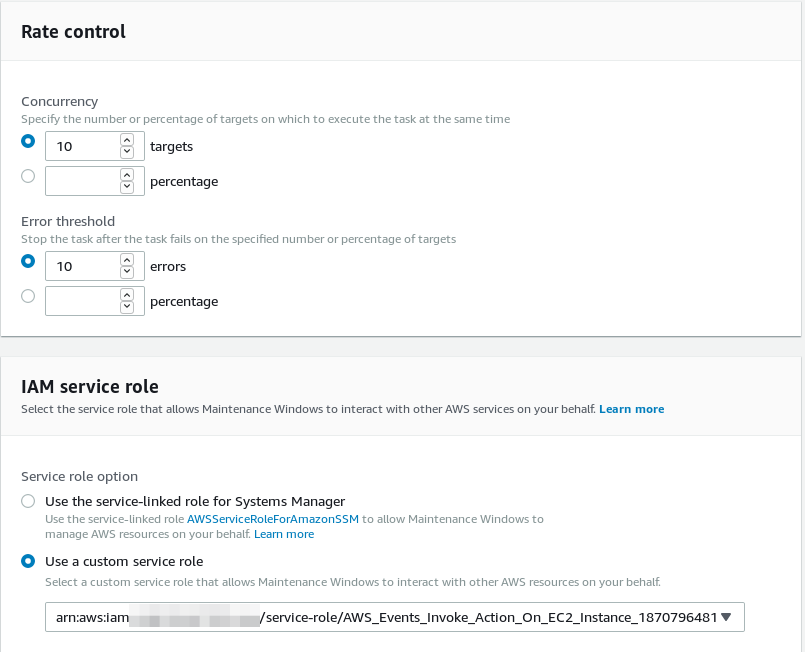
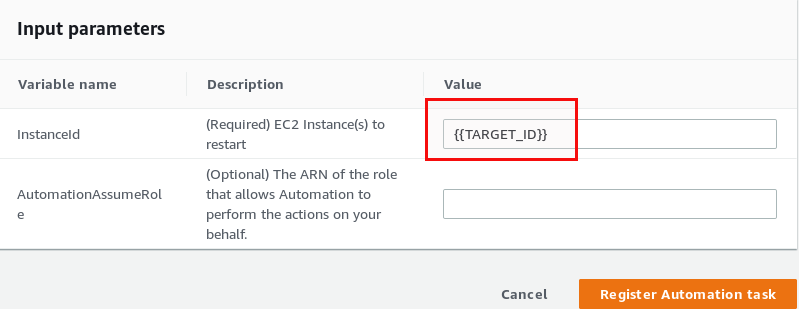
Last, but not least, specify a pseudo parameter called “{TARGET_ID}” which will tell AWS SSM to run that against all the instances you selected in the upper part of the screen:
That’s it. Your instances will be rebooted at the time you specified in the cron expression. All fine and easy and you never have to worry about scheduled instance reboots. Just adjust the cron expression and maybe the list of instances and you are done for the next scheduled reboot. Really? We did it like that against 100 instances and we got a real surprise. What happened? Not many, but a few instances have been rebooted hard and one of them even needed to be restored afterwards. Why that? This never happened in the tests we did before. When an instance does not reboot within 4 minutes AWS performs a hard reboot. This can lead to corruption as stated here. When you have busy instances at the time of the reboot this is not what you want. On Windows you get something like this:
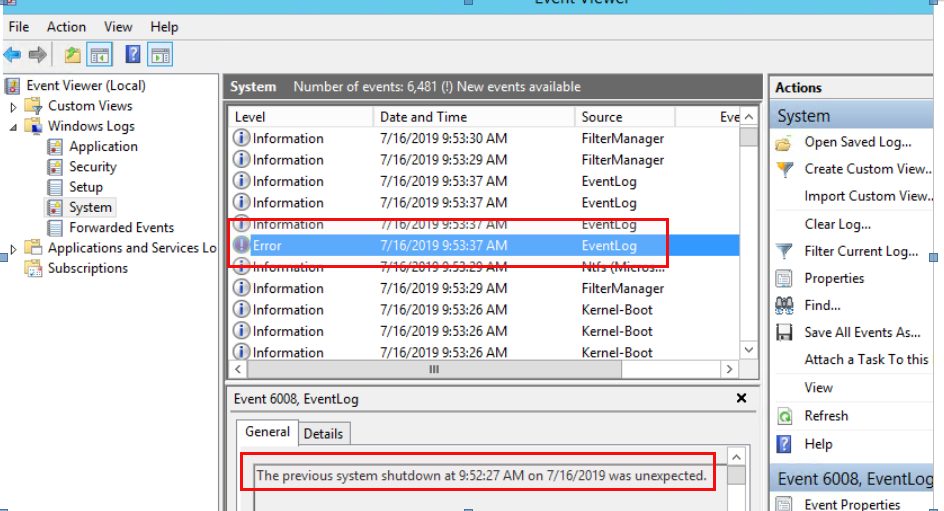
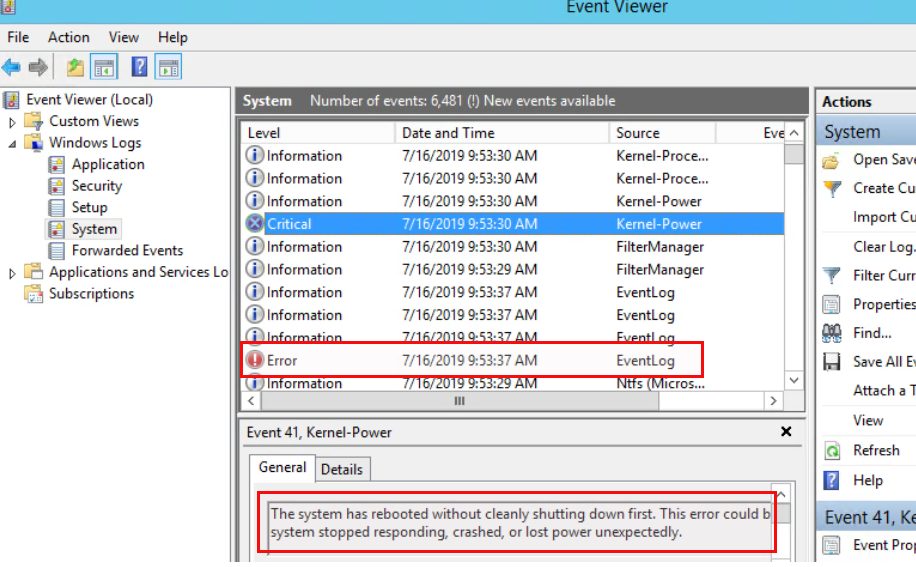
You can easily reproduce that by putting a Windows system under heavy load with a cpu stress test and then schedule a reboot as described above.
In the background the automation document calls aws:changeInstanceState and that comes with a force parameter:

… and here we have it again: Risk of corruption. When you take a closer look at the automation document that stops an EC2 instance you can see that as well:
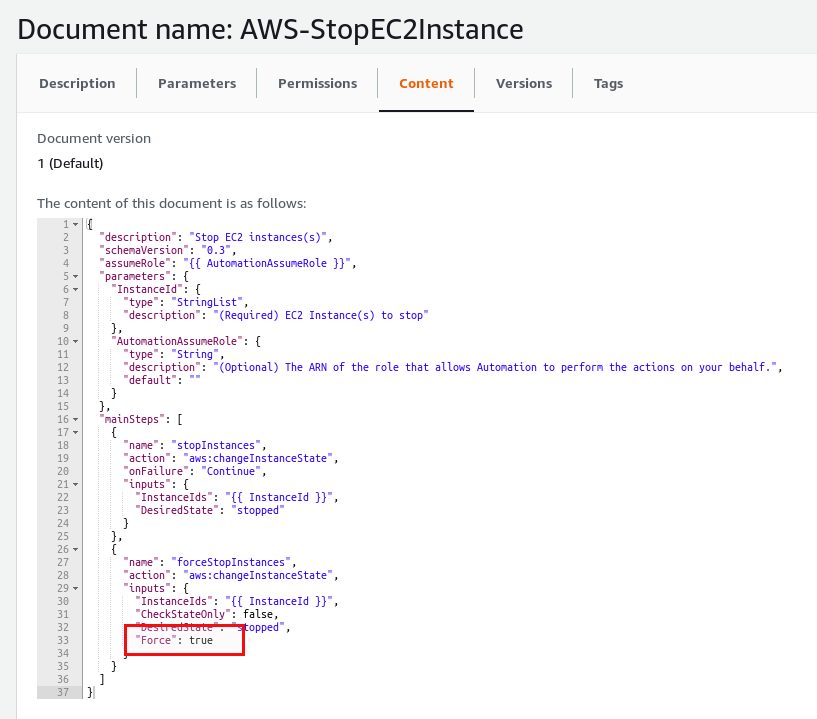
So what is the conclusion of all this? It is not to blame AWS for anything, all is documented and works as documented. Testing in a test environment does not necessarily mean it works on production as well. Even if it is documented you might not expect it because your tests went fine and you missed that part of the documentation where the behavior is explained. AWS System Manager still is a great tool for automating tasks but you really need to understand what happens before implementing it in production. And finally: Working on public clouds make many things easier but others harder to understand and troubleshoot.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)