Before we really start with this post: This is just an experiment and you should not implement it like this in real life. The goal of this post is just to show what is possible and I am not saying that you should do it (the way it is implemented here will be catastrophic for your database performance and it is not really secure). As I am currently exploring a lot of AWS services I wanted to check if there is an easy way to send data from PostgreSQL into an AWS Kinesis data stream for testing purposes and it turned out that this is actually quite easy if you have the AWS Command Line Interface installed and configured on the database server.
Creating a new Kinesis stream in AWS is actually a matter of a few clicks (of course you can do that with the command line utilities as well):

What I want is a simple data stream where I can put data into:
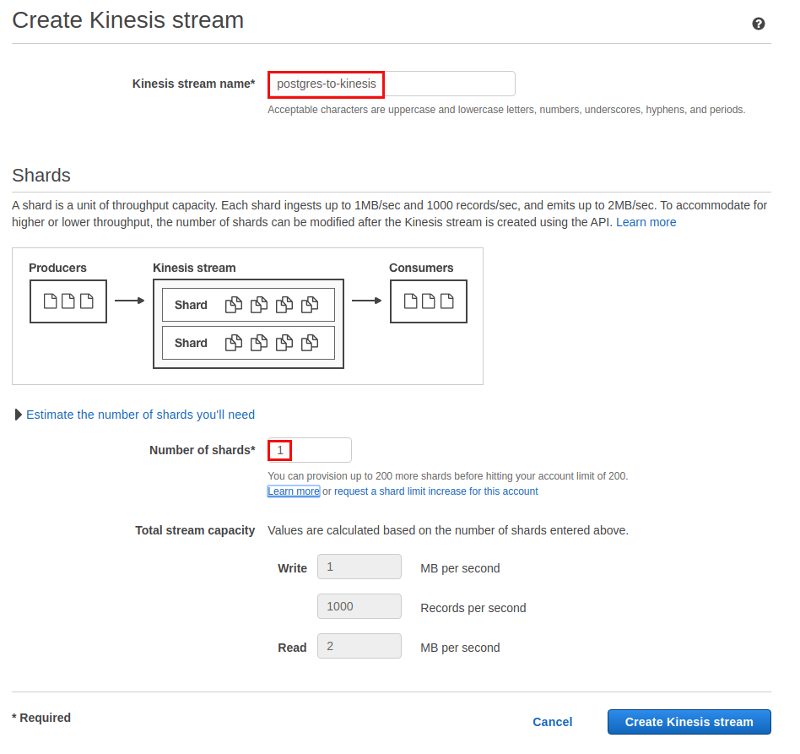
Obviously the new stream needs a name and as I will not do any performance or stress testing one shard is absolutely fine:
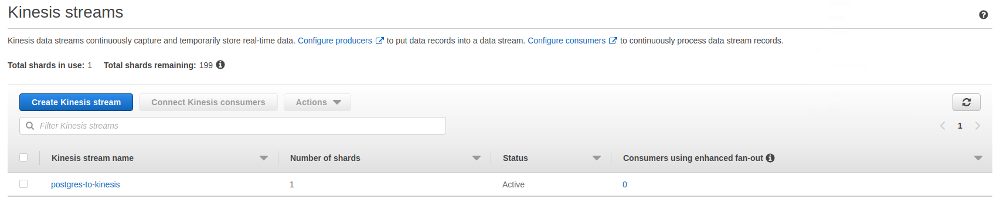
That’s all what needs to be done, the new stream is ready:
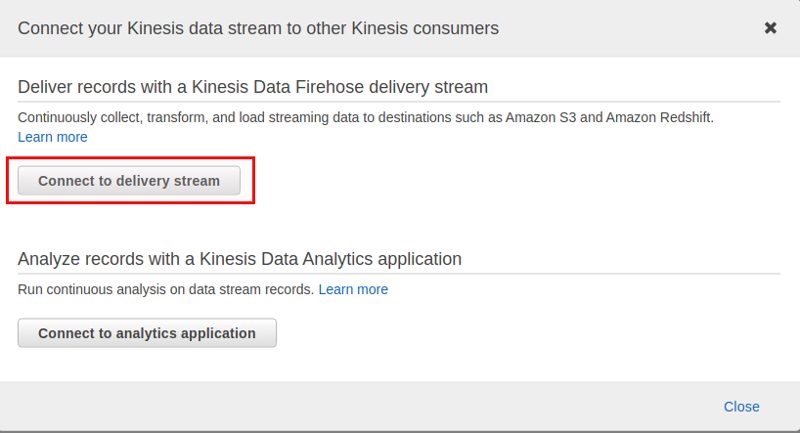
An AWS Kinesis stream is not persistent by default. That means, if you want to permanently store the output of a stream you need to connect the stream to a consumer that processes, eventually transforms, and finally stores the data somewhere. For this you can use AWS Kinesis Firehose and this is what I’ll be doing here:
As I want to use AWS S3 as the target for my data I need to use a delivery stream:
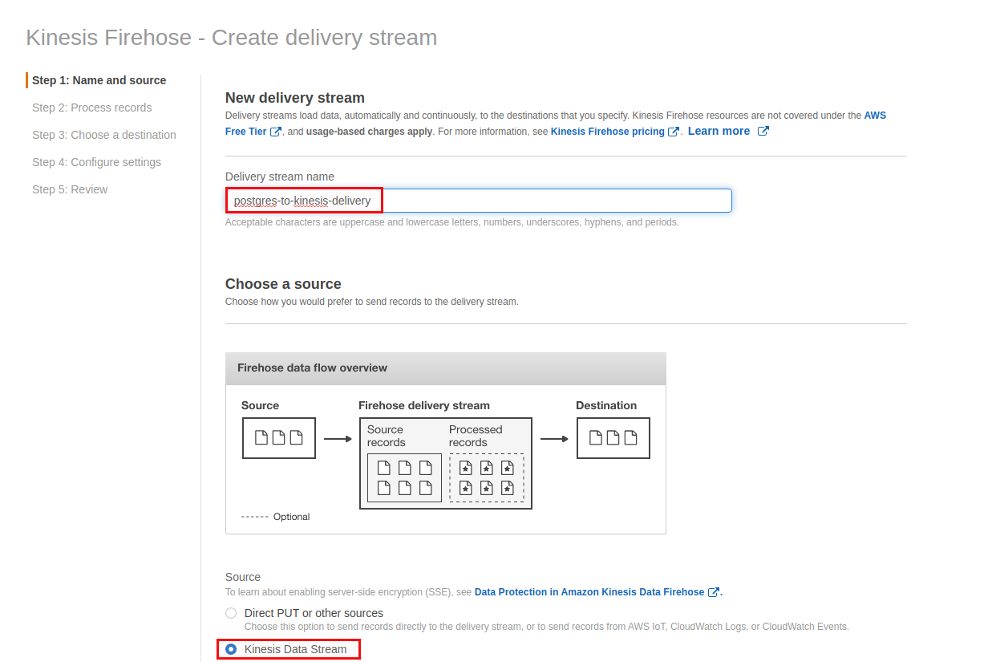
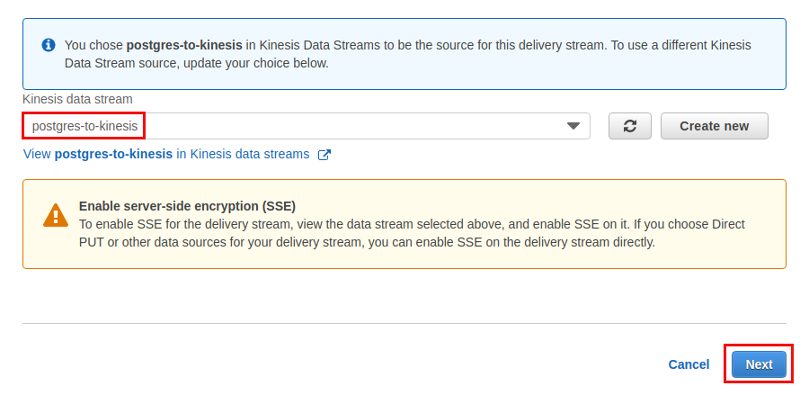
The delivery stream needs a name as well and we will use the stream just created above as the source:
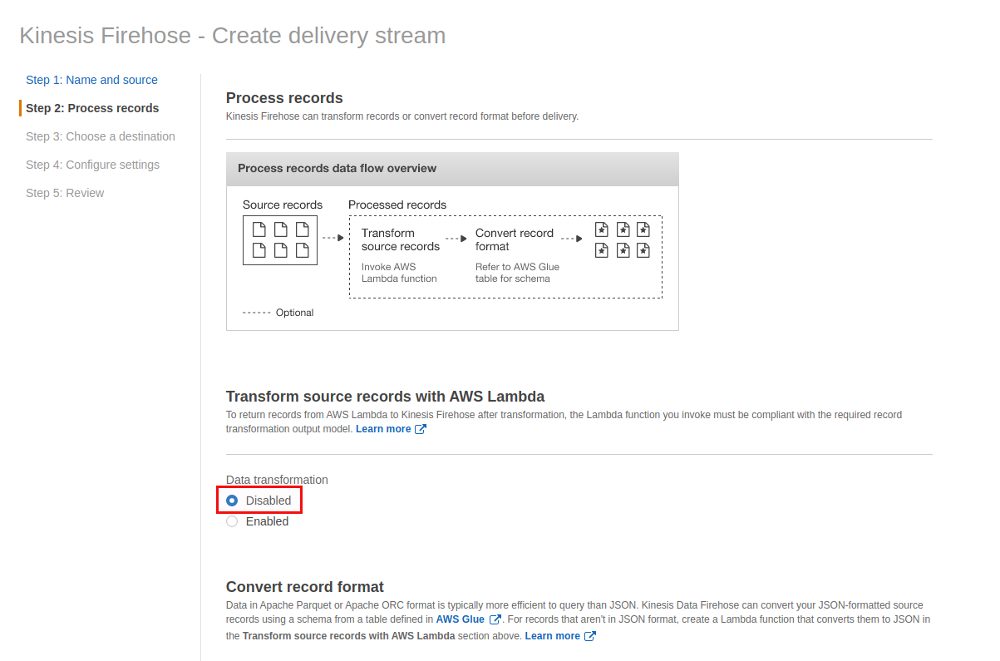
We could go ahead and transform the data with an AWS Lambda function but we’re going to keep it simple for now and skip this option:
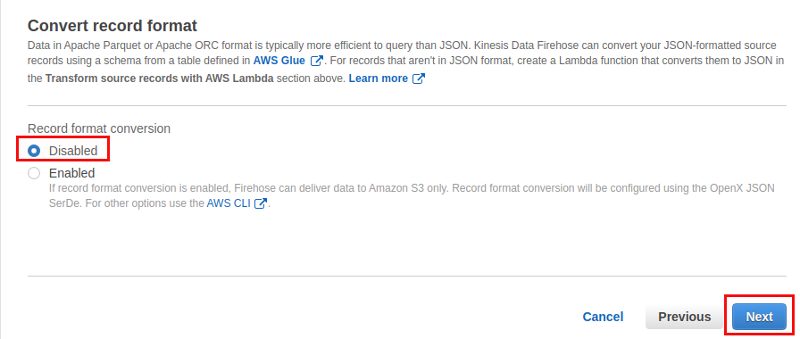
The next screen is about the target for the data. This could be AWS Redshift, AWS Elasticsearch, Splunk or AWS S3, what we’ll be doing here:
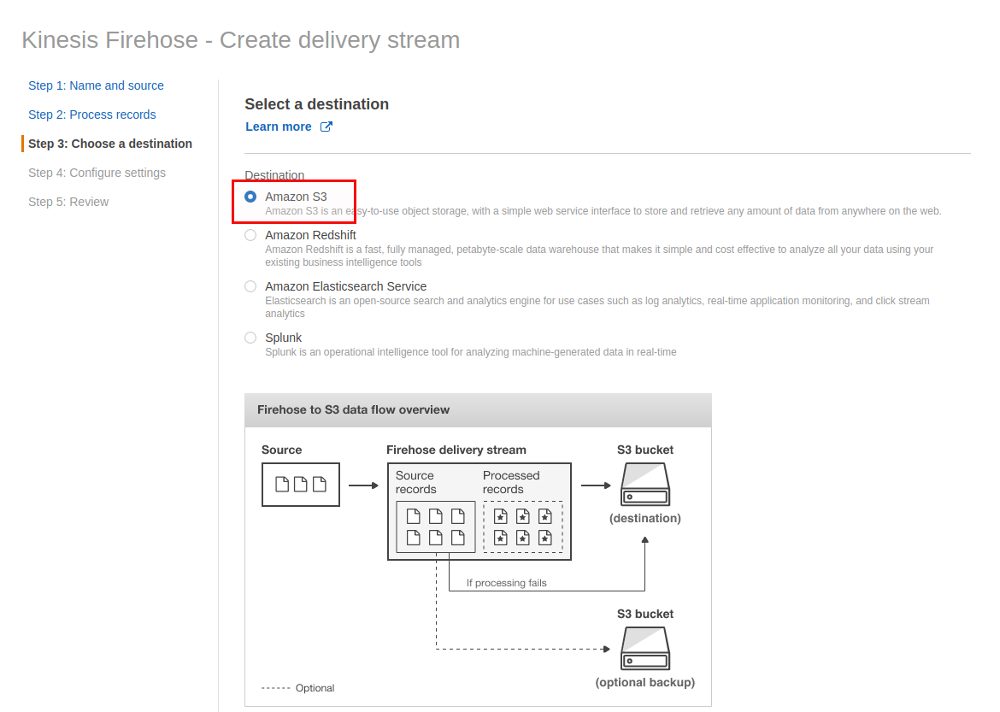
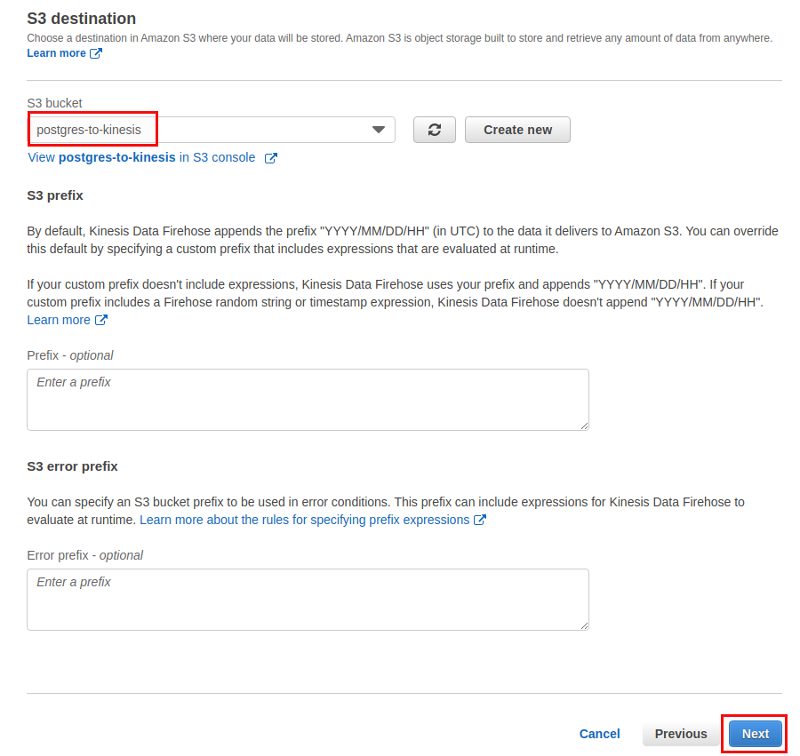
Finally specifying the target S3 bucket:
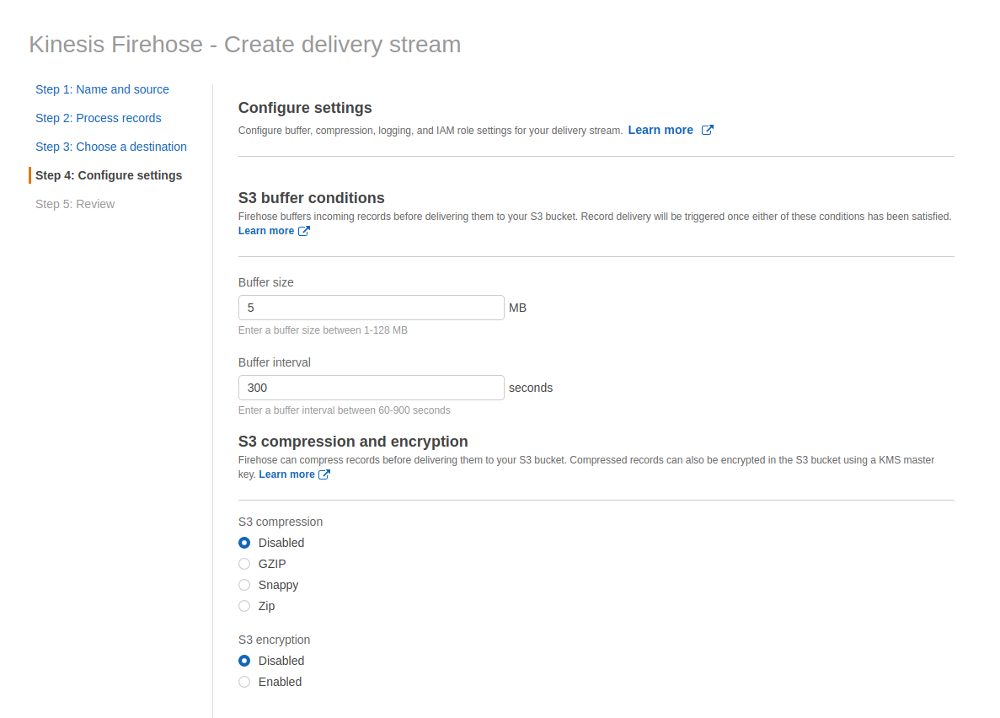
The settings for buffering at not really important for this test but will matter for real systems as these settings determine how fast your data is delivered to S3 (we also do not care about encryption and compression for now):
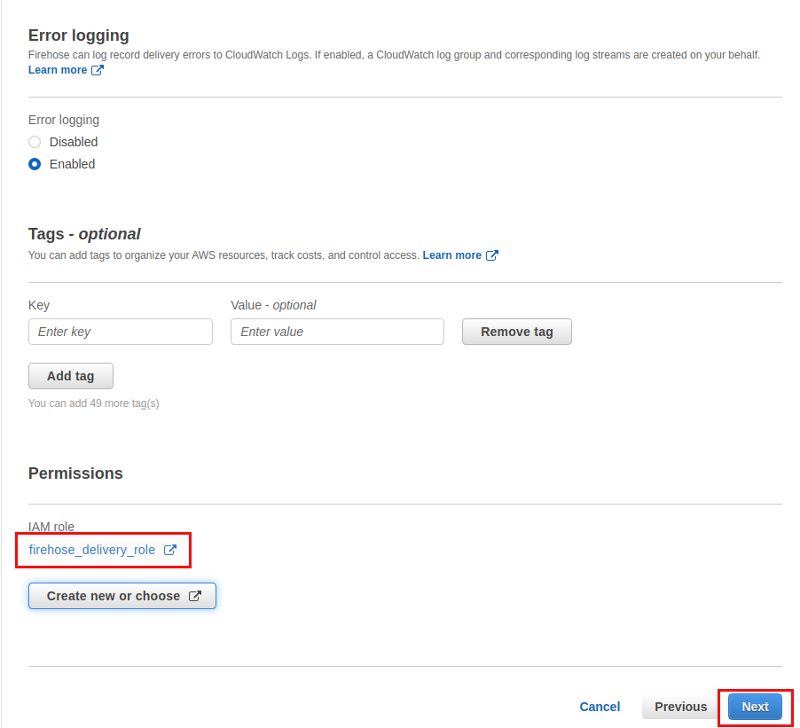
Error logging should of course be enabled and we need an IAM role with appropriate permissions:
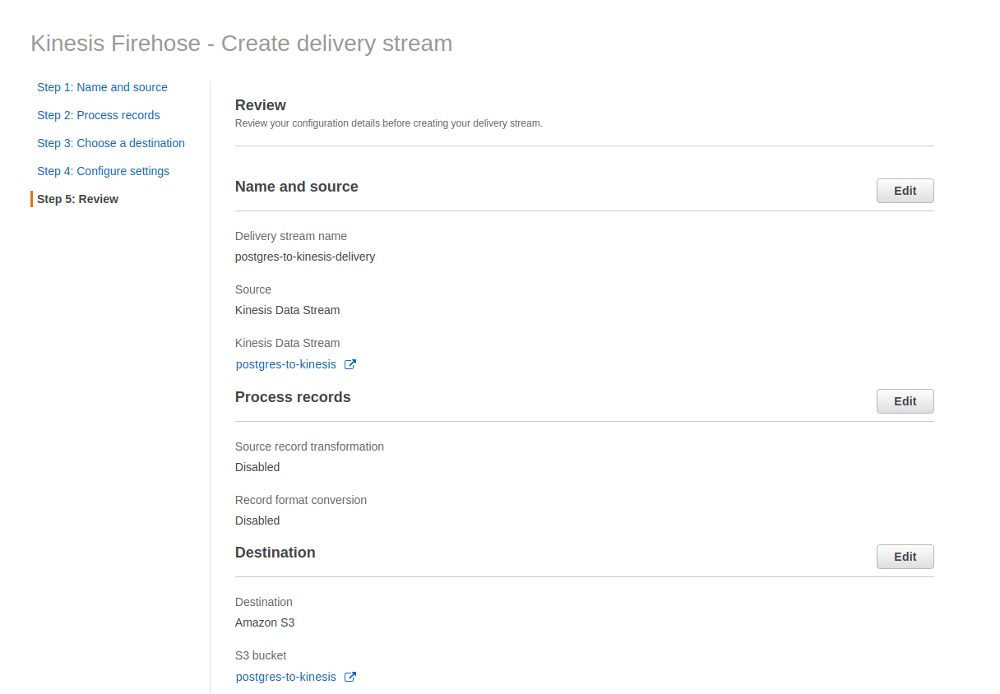
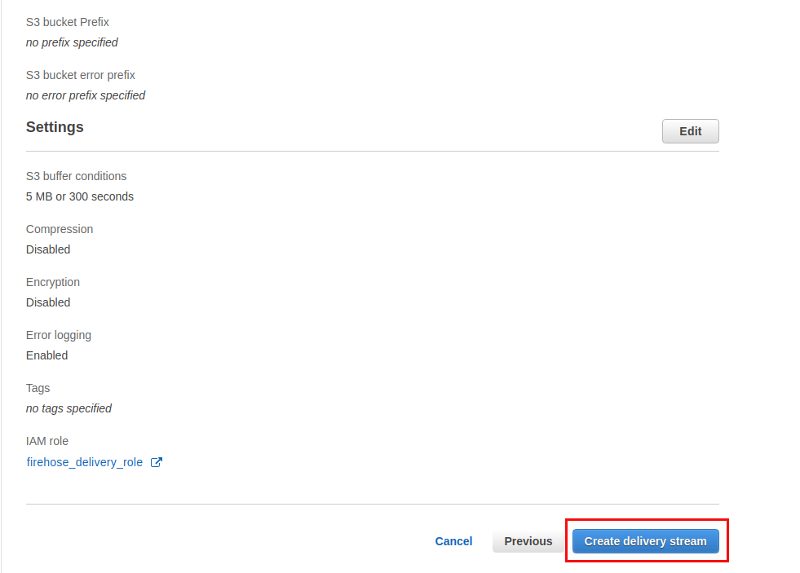
Final review:
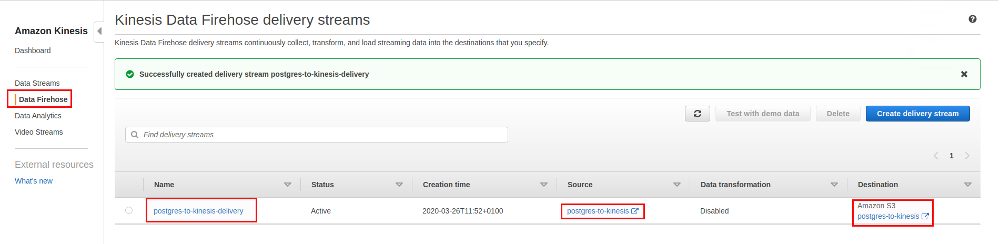
… and the stream and delivery stream are ready to use:
That’s it for the setup on the AWS side and we can continue with configuring PostgreSQL to call the AWS command line utility to write data to the stream. Callling system commands from inside PostgreSQL can be done in various ways, we’ll be using pl/Perl for that, and even the untrusted version so only superusers will be able to do that:
postgres=# create extension plperlu;
CREATE EXTENSION
postgres=# \dx
List of installed extensions
Name | Version | Schema | Description
---------+---------+------------+----------------------------------------
plperlu | 1.0 | pg_catalog | PL/PerlU untrusted procedural language
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)
Next we need a table that will contain the data we want to send to the stream:
postgres=# create table stream_data ( id serial primary key
, stream text );
A trigger will fire each time a new row is inserted and the trigger function will call the AWS command line interface:
create or replace function f_send_to_kinesis()
returns trigger
language plperlu
AS $$
system('aws kinesis put-record --stream-name postgres-to-kinesis --partition-key 1 --data '.$_TD->{new}{stream});
return;
$$;
create trigger tr_test
after insert or update
on stream_data
for each row
execute procedure f_send_to_kinesis();
This is all we need. Let’s insert a row into the table and check if it arrives in AWS S3 (remember that it will take up to 300 seconds or 5MB of data):
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# insert into stream_data (stream) values ('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa');
INSERT 0 1
postgres=# select * from stream_data;
id | stream
----+----------------------------------
1 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
2 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
3 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
4 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
5 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
6 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
7 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
8 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
9 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
(9 rows)
You will also notice that the insert takes quite some time because calling the AWS command line utility and waiting for the result takes ages compared to a normal insert.
While waiting for the data to arrive you can check the monitoring section of both, the stream and the delivery stream:
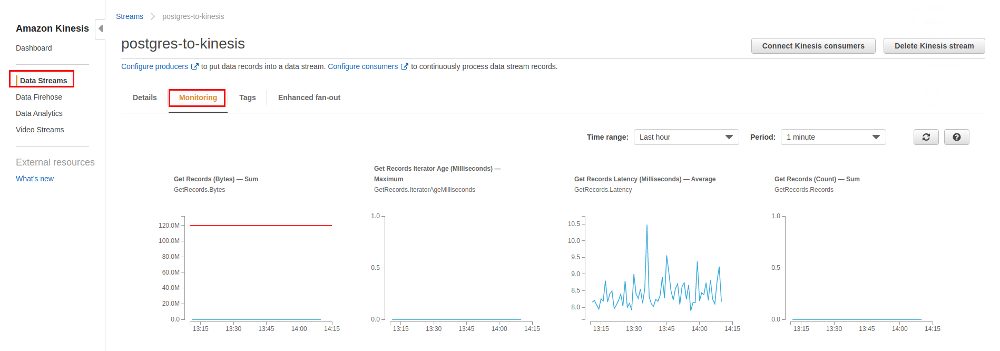
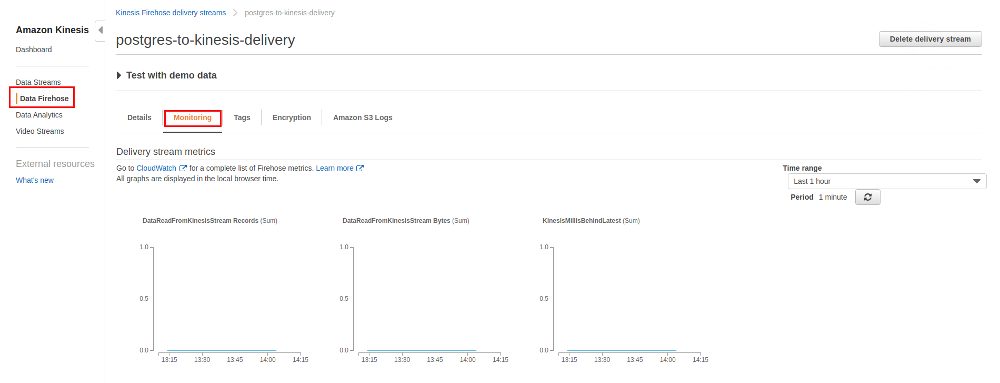
After a while the data appears in S3 and it is organized in [YEAR]/[MONTH]/[DAY]/[HOUR]:
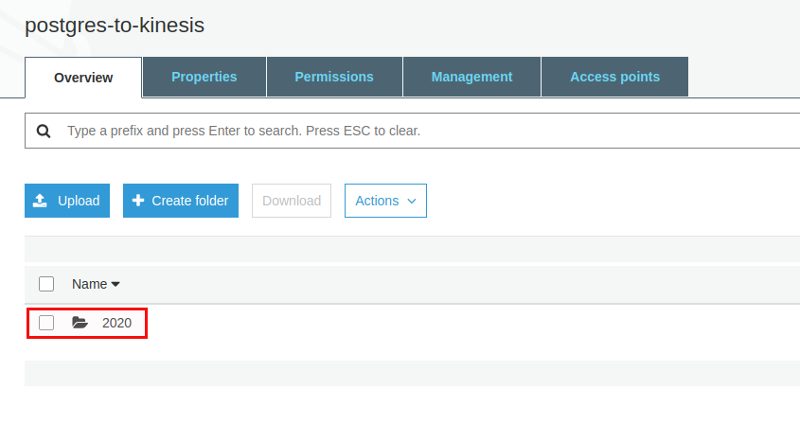
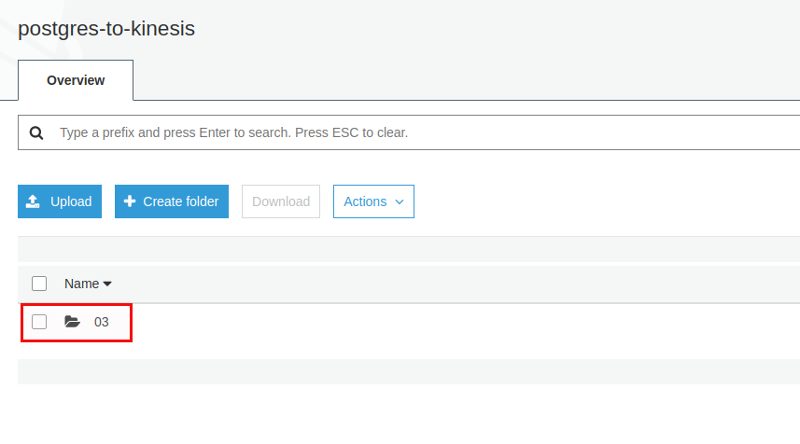
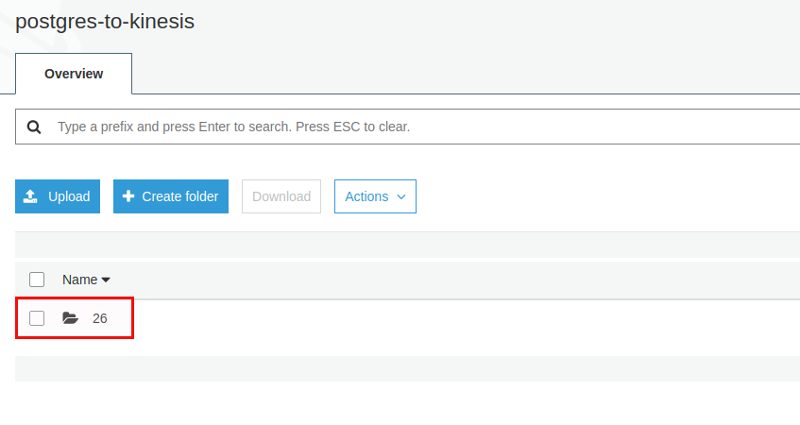
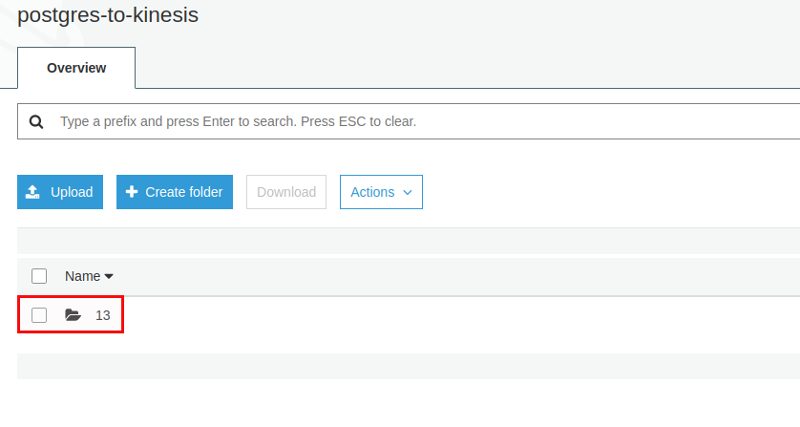
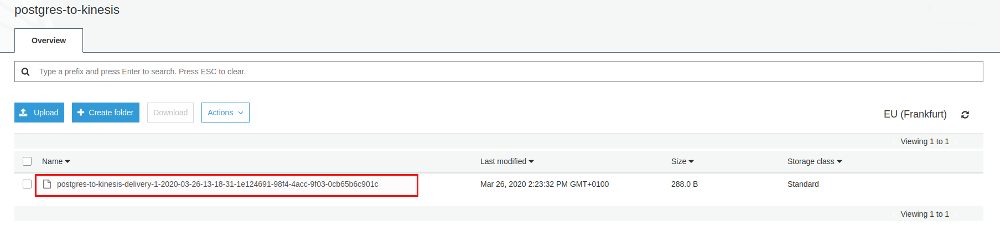
Looking at the file itself all our data is there:

So, actually it is quite easy to send data to an AWS Kinesis stream. If you really need to send data out of PostgreSQL I probably would go for listen/notify to make the calls to the AWS command line utility not blocking the inserts or updates to the table that holds the data for the stream. Anyway, currently I am not aware of a good use case for sending streams of data out of PostgreSQL directly to AWS Kinesis. Maybe you do something like that and how?
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ENB_web-min-scaled.jpg)