I wrote this blog in conjunction with the one about the Solr Sharding – Concepts & Methods a year ago and it was 95% completed but then I had other stuff to do and just forgot I didn’t publish it. It might be a little bit late but well, better late than never… It will complete the overview I wanted to share around the Alfresco Clustering and in particular around the Solr Sharding. In this blog, I will talk about the creation of Shards. This includes the distribution of the different Instances, explaining the global parameters that can be used and showing some examples of what can be done with the concrete commands to achieve that.
I. Shard distribution
One of the strong points of using the Solr Sharding is that you can do pretty much what you want with the distribution of the Shards. It means that you can choose the best distribution of Shards based on your requirements, based on the resources available (Number of Solr Servers, RAM, I/O, …) and then Alfresco can just work with that seamlessly. Let’s consider some situations:
- 1 Solr Server – 2 Shards – No HA (1 Shard Instance per Shard)
- 2 Solr Server – 2 Shards – No HA (1 Shard Instance per Shard)
- 2 Solr Server – 2 Shards – HA (2+ Shard Instances per Shard)
- 6 Solr Server – 3 Shards – HA (2+ Shard Instances per Shard)
For the above examples, there are several possible representation of the Shards repartitions across the different Solr Servers. If we consider all Shards in the same way (same number of Shard Instance for each), then you can represent the above examples as follow:
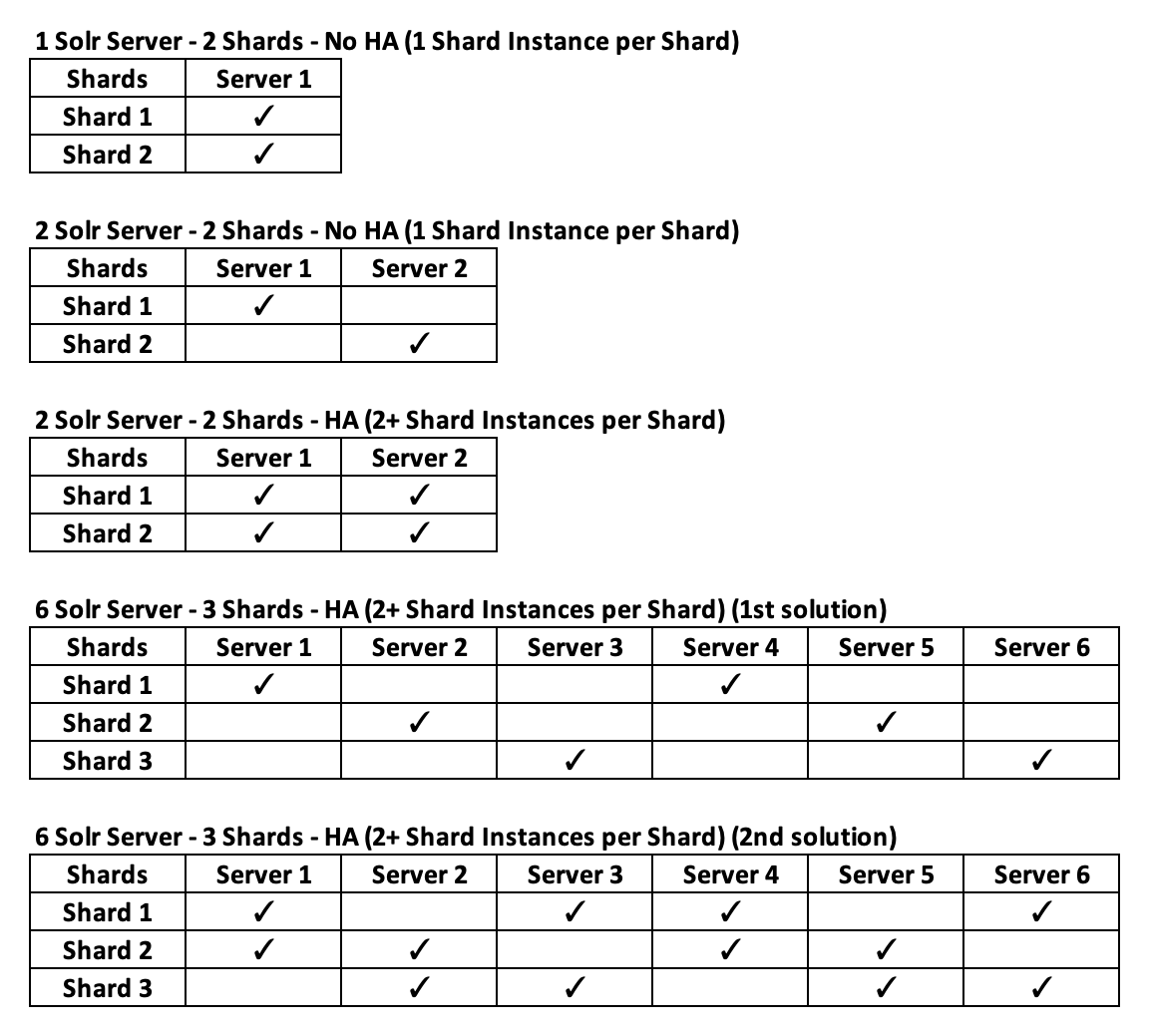
If the Shard N°1 is the most important one and you want this one to be available on all Solr Servers with a maximum of 2 Shards per Solr Server, then this is another possible solution:
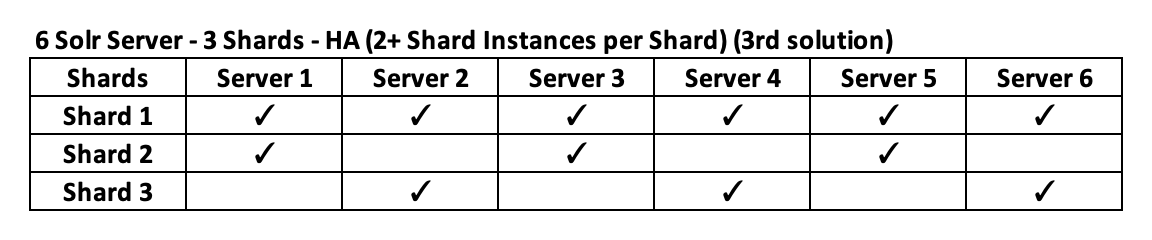
There are several ways to distribute the Shards and the good thing is that it is not really linked with the Sharding Method used. What I mean is that you can define the distribution that you want and it will be possible whatever the Sharding Method is. However, in some cases, the Method used might have an impact on whether or not the chosen distribution make sense. If I take the above example again where the Shard N°1 would be considered he most important one, then it means that you should know exactly what is inside this Shard N°1 but if DB_ID is used, then the content of this Shard will be random… Therefore, even if there is no hard link, some choice might not make a lot of sense if both aspects aren’t considered ;).
Alfresco (ACS only, not community) provides a graphical representation of the Solr Shards on the Alfresco Administration Console (https://alfresco-dns.domain/alfresco/s/enterprise/admin/admin-flocs). This is very useful to quickly see what is setup, how it is organized and what is the status of each and every Shards: whether they are up-to-date, lagging behind or not running at all. Here is an example of 1 Shard Group composed of 5 Shards with 2 Instances each:
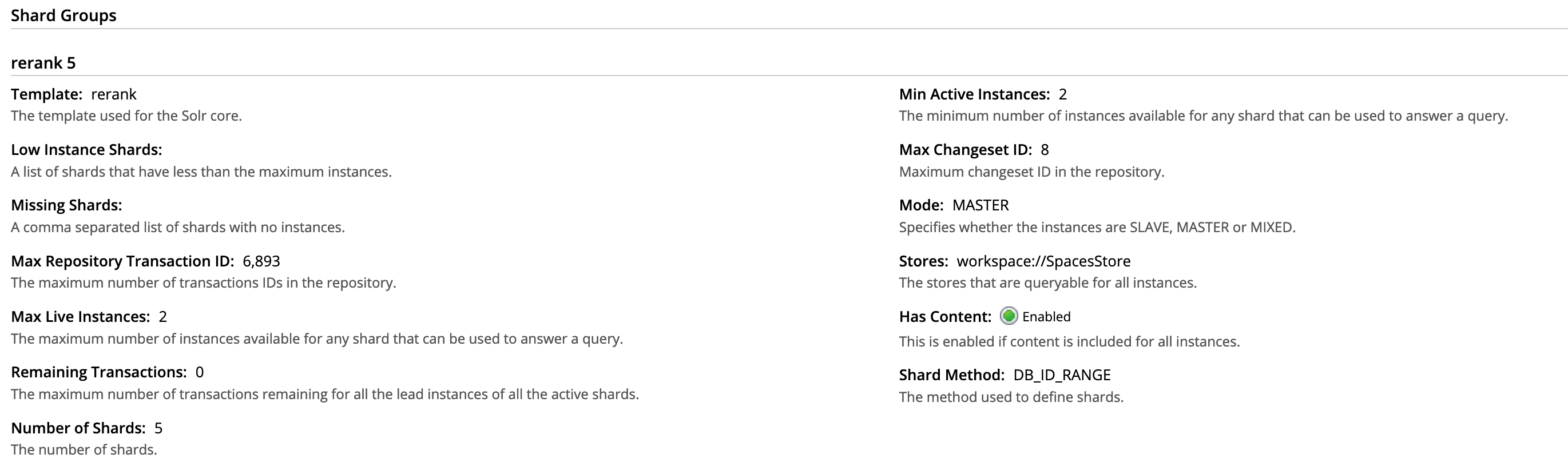
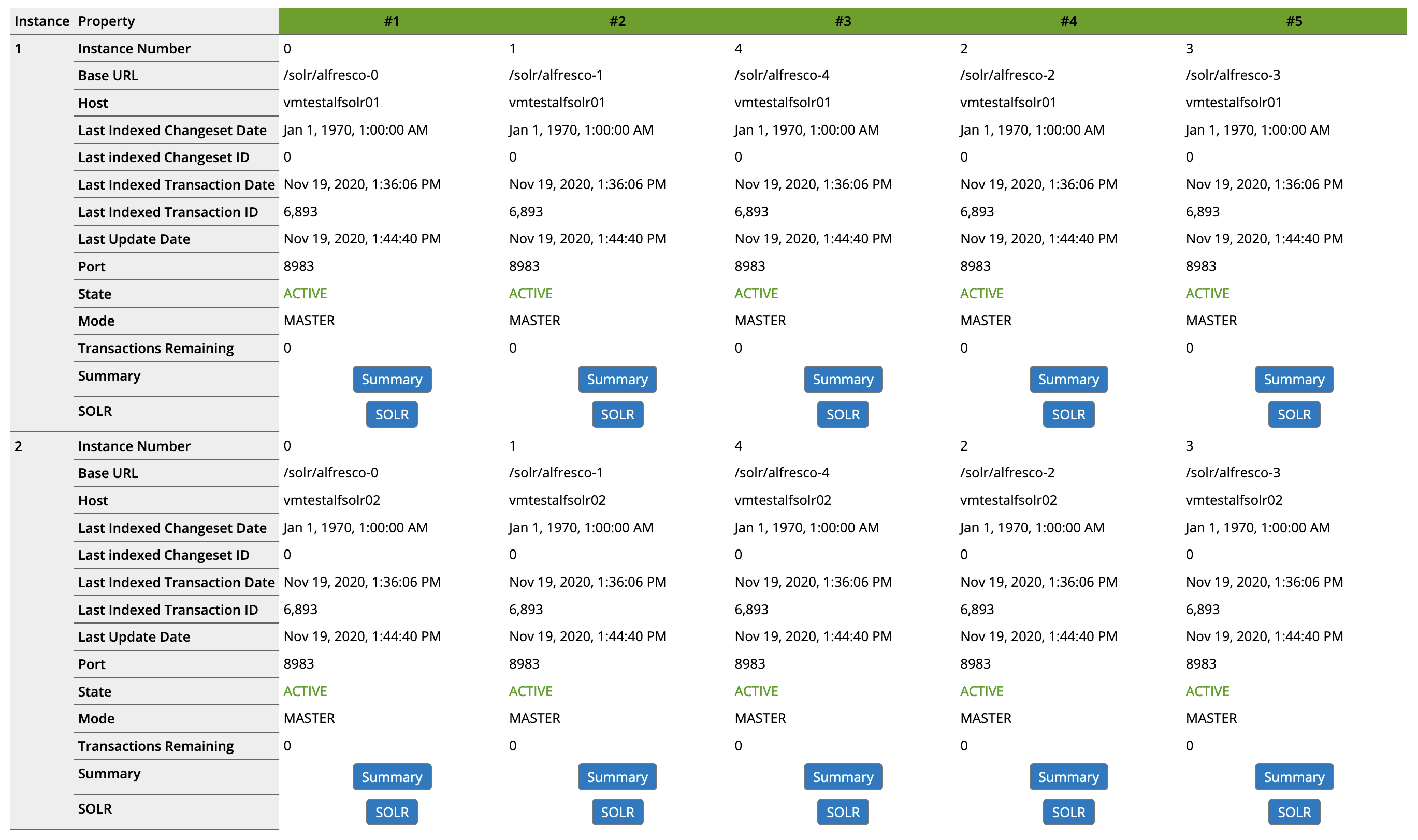
In addition to that, I always find it very useful to look at the Solr reports (https://solr-dns.domain/solr/admin/cores?action=REPORT and https://solr-dns.domain/solr/admin/cores?action=SUMMARY) since it gives an overview of exactly how many acls and nodes are indexed. These are well known reports for Alfresco but in case you never saw these, I would advise you to take a look.
II. Shard creation parameters
As mentioned in the previous blog related to the Sharding Methods, when creating a Shard Instance, you will need to define some parameters. Here, I will only define them in the URL/Command because it is easier to have everything there. In addition to these parameters specific to each Method, there are some that are global. Before diving into the commands, let’s take a look at a few parameters and what they represent:
- storeRef: Which Alfresco Store should this Shard index
- numShards: Maximum number of different Shards that can be created
- For DB_ID_RANGE, even if you need only 2 Shards at the moment, put more here (like 10/20) to be able to create new Shards in the future as the index grows. Once this limit is defined, you cannot exceed it so keep some margin
- For all other Methods, set that to the number of Shards needed
- numNodes: Maximum number of Solr Servers that can be used
- For DB_ID_RANGE, even if you have only 2 Solr Servers at the moment, put more here (like 10/20) to be able to install new Solr Servers and create Shard Instances in the future. Once this limit is defined, you cannot exceed it so keep some margin
- For all other Methods, even if you have only 2 Solr Servers at the moment, put more here (like 10/20). Maybe in the future you will want to have the same Shards (fix number) on more Solr Servers. Once this limit is defined, you cannot exceed it so keep some margin
- nodeInstance: The “ID/Number” of the Solr Server on which the command is going to be executed, from 1 to numNodes, included
- template: Which template should be used as base to create the new Core. The templates can be found under <SOLR_HOME>/solrhome/templates/
- coreName: The base name of the Solr Core that this Shard should be part of. If you do not specify one, it will be generated from the Alfresco storeRef (E.g.: “workspace-SpacesStore”). Usual names can be “alfresco” or “archive” for example (Name of the default non-sharded cores)
- shardIds: An ID that controls the generated Core Name, Base URL and Solr Data storage. This is to differentiate instances of Shards on a single Solr Server. You might think that this is the “ID/Number” of the Shard but not necessarily: with the DB_ID_RANGE for example, you can have the same shardIds used on two different Solr Servers for different Shards because the important thing is the range, it’s not the shardIds parameter in this case. So be careful here, this might be confusing. A best practice is however to have this shardIds set to the real “ID/Number” of the Shard so that it avoids confusion in all cases
- replicationFactor: Technically speaking, the replication of a Shard Instance is another Shard Instance indexing the same set of nodes (so from the same Shard). You can normally mention the “replicationFactor” parameter in Solr but with the way it was implemented for Alfresco, you don’t need to care about that actually. You will see in the example below that to have several Shard Instances for the same Shard, you only need to execute the same commands on different servers
- property.XXX: All the properties that can be set in the template’s solrcore.properties as well as the Sharding Method specific ones like:
- property.data.dir.root: The place where the index will be put
- property.shard.method: The Sharding Method to be used to create this Shard Instance
- property.shard.instance: This is supposed to be the real “ID/Number” of the Shard for which a Shard Instance should be created (from 0 to numShards-1)
In summary, with the above parameters:
- The name of the Core will be: ${coreName}-${shardIds}
- The Solr Data will be put under: ${data.dir.root}/${coreName}-${shardIds}
- The Solr Home will be put under: ${solr.solr.home}/${template}–${coreName}–shards–${numShards}-x-${replicationFactor}–node–${nodeInstance}-of-${numNodes}/${coreName}-${shardIds}
- The Base URL will be: ${solr.baseurl}/${coreName}-${shardIds}
- The Shard that will be created (unless otherwise): ${property.shard.instance}
One final note about the parameters: you need to be extra careful with these. I will say it again but in case of DB_ID_RANGE for example, Solr will not care about the shardIds or the property.shard.instance, it will only care about what it needs to index and that is based on the range… If you are using the Dynamic Registration, Alfresco will (and this is where the confusion can start) show you (in the Admin Console > Search Services Sharding) wrong information because it will base itself on the “property.shard.instance” to know to which Shard this instance belongs to (or at least supposed to…). This is just a graphical representation of the Shard Instances (so normally no impact on searches) but still, if you want an efficient and correct graphical view, keep things consistent!
III. Examples
a. DB_ID_RANGE
I will use the “High Availability – 6 Solr Server – 3 Shards (2nd solution)” as working example to show which commands can be used to create these: 3 different Shards, 4 Shard Instances for each on the 6 Solr Servers. I will use the DB_ID_RANGE Method so it is easy to see the differences between each command and identify for which Shard an Instance will be created. I will use a range of 50 000 000, assume that we can go up to 20 Shards (so 1 000 000 000 at maximum) on up to 12 Solr Servers.
- For the Solr Server 1 – Shards 0 & 1:
- curl -v “http://solr1:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=1&template=rerank&coreName=alfresco&shardIds=0&property.shard.method=DB_ID_RANGE&property.shard.range=0-50000000&property.shard.instance=0“
- curl -v “http://solr1:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=1&template=rerank&coreName=alfresco&shardIds=1&property.shard.method=DB_ID_RANGE&property.shard.range=50000000-100000000&property.shard.instance=1“
- For the Solr Server 2 – Shards 1 & 2:
- curl -v “http://solr2:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=2&template=rerank&coreName=alfresco&shardIds=1&property.shard.method=DB_ID_RANGE&property.shard.range=50000000-100000000&property.shard.instance=1“
- curl -v “http://solr2:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=2&template=rerank&coreName=alfresco&shardIds=2&property.shard.method=DB_ID_RANGE&property.shard.range=100000000-150000000&property.shard.instance=2“
- For the Solr Server 3 – Shards 0 & 2:
- curl -v “http://solr3:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=3&template=rerank&coreName=alfresco&shardIds=0&property.shard.method=DB_ID_RANGE&property.shard.range=0-50000000&property.shard.instance=0“
- curl -v “http://solr3:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=3&template=rerank&coreName=alfresco&shardIds=2&property.shard.method=DB_ID_RANGE&property.shard.range=100000000-150000000&property.shard.instance=2“
- For the Solr Server 4 – Shards 0 & 1:
- curl -v “http://solr4:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=4&template=rerank&coreName=alfresco&shardIds=0&property.shard.method=DB_ID_RANGE&property.shard.range=0-50000000&property.shard.instance=0“
- curl -v “http://solr4:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=4&template=rerank&coreName=alfresco&shardIds=1&property.shard.method=DB_ID_RANGE&property.shard.range=50000000-100000000&property.shard.instance=1“
- For the Solr Server 5 – Shards 1 & 2:
- curl -v “http://solr5:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=5&template=rerank&coreName=alfresco&shardIds=1&property.shard.method=DB_ID_RANGE&property.shard.range=50000000-100000000&property.shard.instance=1“
- curl -v “http://solr5:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=5&template=rerank&coreName=alfresco&shardIds=2&property.shard.method=DB_ID_RANGE&property.shard.range=100000000-150000000&property.shard.instance=2“
- For the Solr Server 6 – Shards 0 & 2:
- curl -v “http://solr6:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=6&template=rerank&coreName=alfresco&shardIds=0&property.shard.method=DB_ID_RANGE&property.shard.range=0-50000000&property.shard.instance=0“
- curl -v “http://solr6:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=20&numNodes=12&nodeInstance=6&template=rerank&coreName=alfresco&shardIds=2&property.shard.method=DB_ID_RANGE&property.shard.range=100000000-150000000&property.shard.instance=2“
b. DATE
In this section, I will use the same setup but with a DATE Sharding Method. I will keep the same details as well (3 Shards) and therefore, each Shard Instance will contain 4 of the 12 months. There are several ways to obtain this:
- No grouping option (default 1): Shard N°1 will contain the months 1,4,7,10 // Shard N°2 will contain the months 2,5,8,11 // Shard N°3 will contain the months 3,6,9,12
- Grouping of 2: Shard N°1 will contain the months 1,2,7,8 // Shard N°2 will contain the months 3,4,9,10 // Shard N°3 will contain the months 5,6,11,12
- Grouping of 3: Shard N°1 will contain the months 1,2,3,10 // Shard N°2 will contain the months 4,5,6,11 // Shard N°3 will contain the months 7,8,9,12
- Grouping of 4: Shard N°1 will contain the months 1,2,3,4 // Shard N°2 will contain the months 5,6,7,8 // Shard N°3 will contain the months 9,10,11,12
Here, I will be group the months by 4. Since this is not the DB_ID_RANGE Method, all the Shard Instances for a Solr Server can be created by single command. However, when doing so, you cannot specify the “property.shard.instance” because it would contain several values (0,1,2 for example) and it is as far as I know, not supported. Therefore, the Shards will be created based on the “shardIds” parameter which has no problem with comma separated list:
- For the Solr Server 1 – Shards 0 & 1:
- curl -v “http://solr1:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=1&template=rerank&coreName=alfresco&shardIds=0,1&property.shard.method=DATE&property.shard.key=cm:modified&property.shard.date.grouping=4&property.shard.count=3″
- For the Solr Server 2 – Shards 1 & 2:
- curl -v “http://solr2:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=2&template=rerank&coreName=alfresco&shardIds=1,2&property.shard.method=DATE&property.shard.key=cm:modified&property.shard.date.grouping=4&property.shard.count=3″
- For the Solr Server 3 – Shards 0 & 2:
- curl -v “http://solr3:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=3&template=rerank&coreName=alfresco&shardIds=0,2&property.shard.method=DATE&property.shard.key=cm:modified&property.shard.date.grouping=4&property.shard.count=3″
- For the Solr Server 4 – Shards 0 & 1:
- curl -v “http://solr4:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=4&template=rerank&coreName=alfresco&shardIds=0,1&property.shard.method=DATE&property.shard.key=cm:modified&property.shard.date.grouping=4&property.shard.count=3″
- For the Solr Server 5 – Shards 1 & 2:
- curl -v “http://solr5:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=5&template=rerank&coreName=alfresco&shardIds=1,2&property.shard.method=DATE&property.shard.key=cm:modified&property.shard.date.grouping=4&property.shard.count=3″
- For the Solr Server 6 – Shards 0 & 2:
- curl -v “http://solr6:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=6&template=rerank&coreName=alfresco&shardIds=0,2&property.shard.method=DATE&property.shard.key=cm:modified&property.shard.date.grouping=4&property.shard.count=3″
c. ACL_ID (ACL v2)
In this section, I will use the same setup but with an ACL_ID Sharding Method. I will keep the same details as well (3 Shards). Each of the three Shards will get assigned some of the ACLs of the Alfresco Repository and it will index all the Alfresco nodes that have these specific ACLs. Therefore, it will be a random assignment that might or might not be evenly distributed (the more ACLs you have, the more evenly it is supposed to be in theory):
- For the Solr Server 1 – Shards 0 & 1:
- curl -v “http://solr1:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=1&template=rerank&coreName=alfresco&shardIds=0,1&property.shard.method=ACL_ID&property.shard.count=3″
- For the Solr Server 2 – Shards 1 & 2:
- curl -v “http://solr2:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=2&template=rerank&coreName=alfresco&shardIds=1,2&property.shard.method=ACL_ID&property.shard.count=3″
- For the Solr Server 3 – Shards 0 & 2:
- curl -v “http://solr3:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=3&template=rerank&coreName=alfresco&shardIds=0,2&property.shard.method=ACL_ID&property.shard.count=3″
- For the Solr Server 4 – Shards 0 & 1:
- curl -v “http://solr4:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=4&template=rerank&coreName=alfresco&shardIds=0,1&property.shard.method=ACL_ID&property.shard.count=3″
- For the Solr Server 5 – Shards 1 & 2:
- curl -v “http://solr5:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=5&template=rerank&coreName=alfresco&shardIds=1,2&property.shard.method=ACL_ID&property.shard.count=3″
- For the Solr Server 6 – Shards 0 & 2:
- curl -v “http://solr6:8983/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=12&nodeInstance=6&template=rerank&coreName=alfresco&shardIds=0,2&property.shard.method=ACL_ID&property.shard.count=3″
IV. Conclusion & final remarks:
At first, it might be a little confusing to work with Solr Sharding because there are a lot of terms that might overlap each-other a little bit but once you get it, it is such a pleasure to so easily create this kind of indexing architecture. Some final remarks:
- As mentioned previously, you can create all the Instances on a Solr Server using a single command, except if you are using the DB_ID_RANGE because that contains the one variable parameter that needs to change between two different Shards. If the Instances are part of the same Shard (with the same range), then you can create them all in a single command.
- If you want to have different Shards on the same Solr Server, then you need to change “property.shard.instance” (because it is a different Shard) and “shardIds” (because the Core & Base URL needs to be unique per Solr Server). The Shard Instance will belong to the Shard specified in “property.shard.instance” by default. If not present, it will use “shardIds” (as always, unless there is a range specified for the DB_ID_RANGE Method because this takes precedence over anything else).
- If you want to have several Instances of the same Shard on the same Solr Server, then you need to change “shardIds” and keep “property.shard.instance” the same. If you can avoid that, then you should, for simplicity and consistency, but if you have a requirement to have two Instances of the same Shard on the same Solr Server, it is still possible.
If you are interested in playing with the Solr Sharding but you don’t have an existing infrastructure in place, you might want to take a look at this GitHub project from Angel Borroy which should help you to go further. Have fun!
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/OLS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)