This time, I will talk about distributed availability groups. What’s that? In short, a group of availability groups. Sounds good right? But in which cases may we need such architecture? Firstly, let’s say that distributed availability groups will run on the top of two distinct availability groups meaning that they reside on two distinct WSFCs with their own quorum and voting management. Referring to the Microsoft documentation here, we may think that this new feature will be mainly used in DR scenario but I’m not sure to understand Microsoft about this sentence:
You want the data to continually replicate to the DR site, but you don’t want a potential network problem or issue at the DR site to bring down your primary site
Indeed, we don’t need this new feature to avoid a DR site or a network failure bringing down the primary site. We may simply exclude cluster nodes at the DR site for voting. Maybe I missed something here and I will probably go back when I will get more information.
Moreover, I may not image my customer using an additional cluster just only for DR purpose. Supposing that the DR site is costless from SQL Server license perspective, we need to maintain a “complex” architecture (WSFC) only for that.
After discussing with one another French MVP Christophe Laporte (@Conseilit), we began to draw some pictures of potential scenarios where using DAG may be a good solution. Firstly, let’s say a customer that have many applications. Some of them may run on the primary site and other ones on the DR site because there is a high latency between the two datacenters. In this specific context, you may implement one availability group on each datacenter for HA purpose and add a distributed availability group for DR recovery.
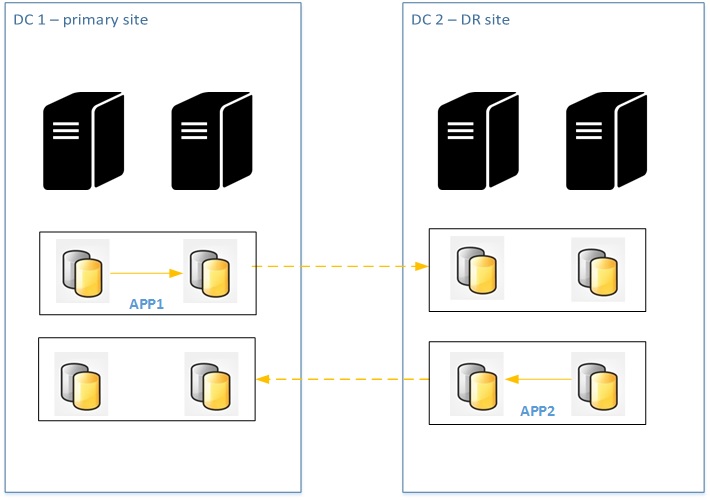
Let’s say now a big company that bought another business that includes an existing datacenter infrastructure with availability groups used by the old company. They may want to introduce HA + DR by using a distributed availability group at the both sides without performing any big changes. Of course, we have to keep in mind the cost of such architecture …
Probably one another advantage of distributed availability groups is that the primary replica has only to send log blocks to one primary replica on another availability group. Let’s imagine a traditional implementation with 2 synchronous replicas at the primary site and 4 or maybe 6 asynchronous replicas at the DR site used for scale-out reporting purpose. In this case, even if we are in a situation where all the read-only replicas are asynchronous, the failure of one may impact the primary replica because the transaction log file won’t be truncated by backup log operations until we fix the issue.
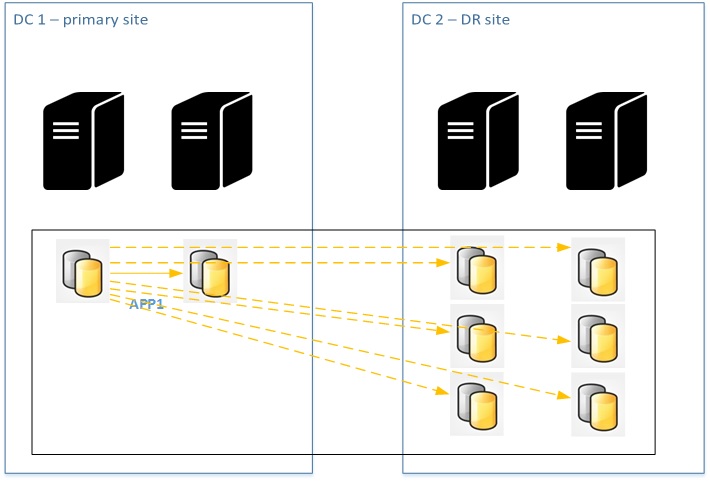
We may have potentially up to 6 replicas that may lead to transaction log issue management in this specific context. Let’s say now we change the game by including all of the read-only replicas in one specific availability group at the DR site that is included itself in a DAG. The failure of one read-only replica on the DR site may impact only the primary on the DR availability group.
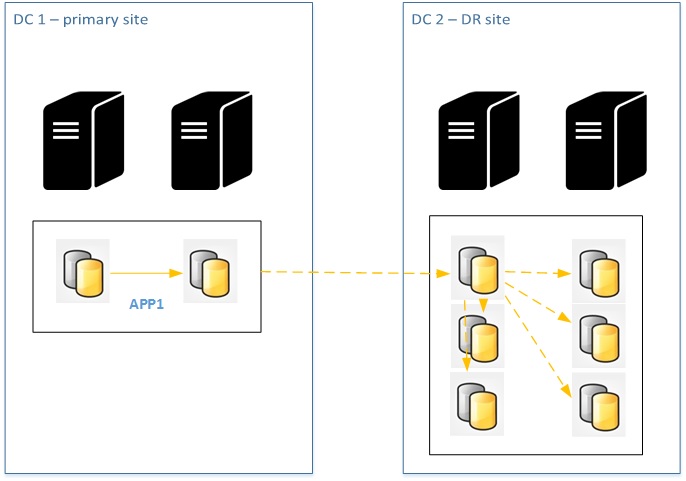
I believe that others scenarios are possible and we will discover some of them through experience. Please feel free to comment or add your thoughts J
Ok it’s time to implement our first DAG. On my lab environment I implemented two additional virtual machines and then I configured another WSFC that includes my two virtual machines. So I finally get an environment that includes two WSFCs with two nodes on each. The first is already installed and used for direct seeding (see direct seeding at the beginning). We will also leverage direct seeding when implementing a DAG in order to replicate the WideWorldImporters between the two availability groups.
But before installing the DAG itself, let’s install the second availability group.
:CONNECT WIN20123SQL16\SQL16
Use master;
-- primary replica
CREATE AVAILABILITY GROUP [testGrp2]
FOR
REPLICA ON
N'WIN20123SQL16\SQL16'
WITH (ENDPOINT_URL = N'TCP://WIN20123SQL16.dbi-services.test:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL),
SEEDING_MODE = AUTOMATIC)
,
N'WIN20124SQL16\SQL16'
WITH (ENDPOINT_URL = N'TCP://WIN20124SQL16.dbi-services.test:5022',
FAILOVER_MODE =MANUAL,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL),
SEEDING_MODE = AUTOMATIC);
GO
ALTER AVAILABILITY GROUP [testGrp2]
ADD LISTENER 'lst-testgrp2'
(
WITH IP ( ('192.168.5.121', '255.255.255.0') ) ,
PORT = 1433);
GO
:CONNECT WIN20124SQL16\SQL16
USE master;
-- secondary replica
ALTER AVAILABILITY GROUP [testGrp2] JOIN
ALTER AVAILABILITY GROUP [testGrp2] GRANT CREATE ANY DATABASE
GO
And finally the distributed availability group
:CONNECT WIN20121SQL16\SQL16 USE master; -- Primary cluster --DROP AVAILABILITY GROUP [distributedtestGrp] CREATE AVAILABILITY GROUP [distributedtestGrp] WITH (DISTRIBUTED) AVAILABILITY GROUP ON 'testGrp' WITH ( LISTENER_URL = 'tcp://lst-testgrp:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'testGrp2' WITH ( LISTENER_URL = 'tcp://lst-testgrp2:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ); GO :CONNECT WIN20123SQL16\SQL16 USE master; -- secondary cluster ALTER AVAILABILITY GROUP [distributedtestGrp] JOIN AVAILABILITY GROUP ON 'testGrp' WITH ( LISTENER_URL = 'tcp://lst-testgrp:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'testGrp2' WITH ( LISTENER_URL = 'tcp://lst-testgrp2:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ); GO
You may notice the special syntax DISTRIBUTED. In addition, the replicas have been replaced by the listeners of each availability group.
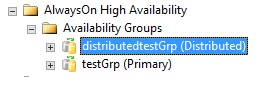
One interesting thing here is that we can’t manage the DAG from SSMS. All options are greyed. So let’s have a look at some DMVs.
select ag.name as group_name, ag.is_distributed, ar.replica_server_name as replica_name, ar.endpoint_url, ar.availability_mode_desc, ar.failover_mode_desc, ar.primary_role_allow_connections_desc as allow_connections_primary, ar.secondary_role_allow_connections_desc as allow_connections_secondary, ar.seeding_mode_desc as seeding_mode from sys.availability_replicas as ar join sys.availability_groups as ag on ar.group_id = ag.group_id; go

Replica names are availability group names for DAG.
We may get information about direct seeding between the two availability groups in the same manner than previously:
select ag.name as aag_name, ar.replica_server_name, d.name as database_name, has.current_state, has.failure_state_desc as failure_state, has.error_code, has.performed_seeding, has.start_time, has.completion_time, has.number_of_attempts from sys.dm_hadr_automatic_seeding as has join sys.availability_groups as ag on ag.group_id = has.ag_id join sys.availability_replicas as ar on ar.replica_id = has.ag_remote_replica_id join sys.databases as d on d.group_database_id = has.ag_db_id
![]()
select local_physical_seeding_id, remote_physical_seeding_id, local_database_name, @@servername as local_machine_name, remote_machine_name, role_desc as [role], transfer_rate_bytes_per_second, transferred_size_bytes / 1024 as transferred_size_KB, database_size_bytes / 1024 as database_size_KB, DATEADD(mi, DATEDIFF(mi, GETUTCDATE(), GETDATE()), start_time_utc) as start_time, DATEADD(mi, DATEDIFF(mi, GETUTCDATE(), GETDATE()), estimate_time_complete_utc) as estimate_time_complete, total_disk_io_wait_time_ms, total_network_wait_time_ms, is_compression_enabled from sys.dm_hadr_physical_seeding_stats
![]()
Ok let’s perform a basic test that consists in creating and inserting data into the WideWorldImporters database from each listener.
:CONNECT lst-testgrp use [WideWorldImporters]; create table dbo.test (id int identity); go insert dbo.test default values; go :CONNECT lst-testgrp2 use [WideWorldImporters]; create table dbo.test (id int identity); go insert dbo.test default values; go
Connecting to lst-testgrp…
(1 row(s) affected)
Disconnecting connection from lst-testgrp…
Connecting to lst-testgrp2…
Msg 3906, Level 16, State 2, Line 14
Failed to update database “WideWorldImporters” because the database is read-only.
Msg 3906, Level 16, State 2, Line 18
Failed to update database “WideWorldImporters” because the database is read-only.
Disconnecting connection from lst-testgrp2…
Ok, as expected the availability group in DR is in READ ONLY mode. I’m not able to create or update anything from there.
Let’s perform a last test after switching over the DAG from testGrp to testGrp2. From the primary availability group:
ALTER AVAILABILITY GROUP [distributedtestGrp] FORCE_FAILOVER_ALLOW_DATA_LOSS
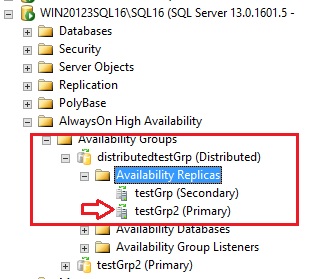
This time I cannot insert data from the first availability group testGrp
Connecting to lst-testgrp…
Msg 976, Level 14, State 1, Line 2
The target database, ‘WideWorldImporters’, is participating in an availability group and is currently not accessible for queries. Either data movement is suspended or the availability replica is not enabled for read access. To allow read-only access to this and other databases in the availability group, enable read access to one or more secondary availability replicas in the group. For more information, see the ALTER AVAILABILITY GROUP statement in SQL Server Books Online.
Disconnecting connection from lst-testgrp…
Connecting to lst-testgrp2…
(1 row(s) affected)
Disconnecting connection from lst-testgrp2…
In this blog we have introduced two new features shipped with SQL Server 2016 and availability groups. At a first glance, they seem to be pretty cool features and will extend the scope of availability group capabilities. I think we will see over time the pros and cons during our other tests and implementation at customer shops. If so, other blog posts will coming soon.
Stay tuned!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)