This blog post is focused on the new supportability of clustered columnstore index on the high- availability read-only replicas.
Others studies are available here:
- New database issue level detection for automatic failover
- Potential features in standard edition
- Automatic failover enhancements
- New load balancing features with read-only replicas
After reading some improvements from the columnstore index feature side, I was very surprised to see the following section:

Clustered columnstore indexes are now supported on AlwaysOn readable secondary replicas! Wonderful! And I guess that the new support of both SI and RCSI transaction isolation level have something to do with this improvement.
So let’s create a clustered columnstore index on my lab environment. I will use for my tests the AdventureWorksDW2012 database and the FactProductInventory fact table.
A first look at this fact table tells us that we’ll probably face an error message because this table contains some foreign keys and one primary key that are not supported on SQL Server 2014. Fortunately, SQL Server 2016 has no such limitations and we’ll able to create the clustered columnstore index.

We can notice two foreign keys and one primary key. The latter is clustered so before creating the clustered columnstore, I will have to change the primary key to a unique constraint.
Let’s add 2 rows in the dbo.FactProductInventory …
… and let’s take a look at this columstore index configuration:

Finally let’s add this AdventureWorks2012DW database to my availability group named 2016Grp:
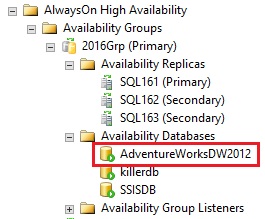
Now, let’s try to query my columnstore index on the SQL162 replica configured as secondary read-only replica:
Do you remember this error message with SQL Server 2014?
With SQL Server 2016 it seems to be another story and it appears to be working properly and this is because snapshot is now supported for clustered columnstore indexes. Let’s have a look at the result of the following query:
![]()
The session with id = 65 concerns my query here. We may notice that it is using snapshot without specifying anything transaction isolation level parameter from my side. As a reminder all read-only queries on a secondary replica are automatically overridden to snapshot isolation and row version mechanism to avoid blocking contention.
But I’m also curious to know if we will face the same blocked redo thread issue in this case? As you know, snapshot isolation prevents read-only queries on the secondary replicas from taking locks and preventing other DML statements against the database from executing, but it doesn’t prevent the read-only queries from taking schema stability locks and blocking DDL statements.
So I wondered if operations issued by the tuple mover in order to switch data from delta store to a row group could stuck the redo thread from executing correctly. To create such situation we may use a long running query on the columnstore index from the secondary replica and in the same time we may insert sufficient data to close a delta store from the primary replica.
Here my horrible and inefficient query that I executed from the secondary. The idea is to hold a schema stability lock during my test.
And the locks hold by my query:

Then I inserted sufficient data to close my delta store:
![]()
After calling manually the tuple mover by using the ALTER INDEX REORGANIZE command, I didn’t face a blocking redo thread situation.
![]()
In fact, we can expect to this result because according to the Microsoft documentation, ALTER INDEX REORGANIZE statement is always performed online. This means long-term blocking table locks are not held and queries or updates to the underlying table can continue during this operation.
So the new situation is the following on both replicas:

Note the new delta store state TOMBSTONE here. I got some information from the Niko Neugebauer (@NikoNeugebauer) blog post here. In fact row group in TOMBSTONE state are delta stores that got compressed (row_group_id = 16 to row_group_id = 18 in my context). This unused row group will be dropped asynchronously by the garbage collector by the tuple mover.
Finally, let’s try to rebuild my columnstore index. In this case we may expect to be in a situation where the redo thread will be blocked by this DDL operation.
Let’s take a look at the redo queue from my secondary replica:
![]()
This time, the ALTER INDEX REBUILD operation has a negative effect on the redo thread which is now stuck while the reporting query execution.

The blocking session concerns my reporting query here:
The bottom line
Introducing the new clustered columnstore index in AlwaysOn availability groups will be definitively a good improvement in several aspects. Indeed, even if clustered columnstore indexes are designed to save a lot of resources, it is always interesting to benefit this feature to offload reporting activities in some scenarios. Moreover, it will be also a good answer to the existing lack of both SI and RCSI transaction isolation levels and the reporting data consistency without locking. I’m looking forward to see these both features in action in production environments soon!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JDU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JOC_web-scaled.jpg)