During the last MVP summit, we had some interesting discussions about availability groups with the SQL Server team and I remember someone asked for managing scenarios like Oracle cascaded destinations and the good news is that SQL Server 2016 already addresses this kind of scenario with distributed availability groups. For example, let’s say you have to manage heavily reporting activity on your application and a solution would be to offload this activity across several secondary read-only replicas. So, a typical architecture as follows:
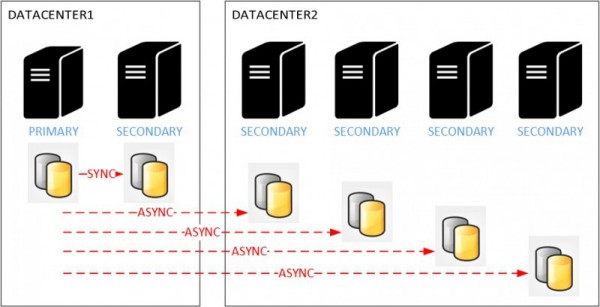
We basically want to achieve high availability on the primary datacenter (DATACENTER1) and to use the secondary datacenter as DR and at the same time to offload reporting activity on secondary replicas. But let’s say you get a low network bandwidth – (WAN classified with ~= 150 / 200 mbps) between your two datacenters which are geographically dispersed from each other. Regarding your current workload against the availability group, we may potentially experience high network traffic when the number of secondary replicas increases on the DR site. Indeed, the number of log blocks to replicate is directly proportional to the number of secondary replicas for the same payload.
I decided to simulate this scenario on my lab environment which reflects the above scenario (2 replicas on the first datacenter and four other replicas on the second datacenter). I used two Lenovo T530 laptop with Hyper-V to simulate the whole environment with a cross datacenter network connection handled by two RRAS servers.
In addition, for a sake of precision, let’s describe the test protocol:
- I used a script which inserts a bunch of data from the primary replica (~ 900MB of data)
- I ran the same workload test after adding one asynchronous read-only replica at time on each test up to 4 replicas.
- I collected performance data from various perfmon counters focused on the availability group network stack (both primary site and DR site)
Here the output of the whole test.
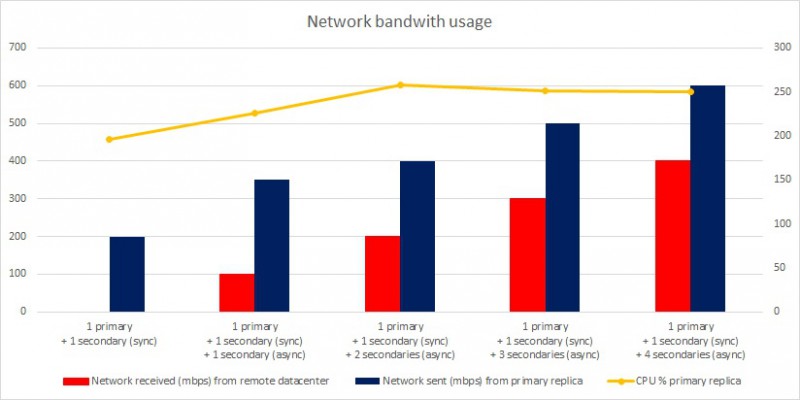
The picture above is pretty clear here. We notice the network bandwidth grows up when adding secondary replicas. In the last test, the network bandwidth reached 400 Mbps (received traffic) on the remote datacenter while that reached for primary replica 600 Mbps (send traffic). Why have we got a difference between network bandwidth consumption between the primary replica and remote datacenter? Well, the answer is simple: network bandwidth consumption on remote datacenter doesn’t include network traffic from the secondary located on the first datacenter for high-availability.
We may also notice the third iteration of the test (1 primary + 1 secondary sync + 2 secondaries async) is showing up a critical point if we have to face a scenario that includes a WAN connection between the two datacenters with a maximum network bandwidth of 200 Mbps. Indeed in this case, the network bandwidth could be quickly saturated by the replication traffic between all the replicas and here probably the first symptoms you may encountered in this case:

A continuous high log send queue size for each concerned secondary replica on the remote datacenter (250 MB on average in my case)…

You may minimize the network overhead by isolating the replication traffic to its own network but in some cases if you’re unlucky it will not be enough. This is a situation which may be solved by introducing distributed availability groups and the cascaded destinations principle as shown below:
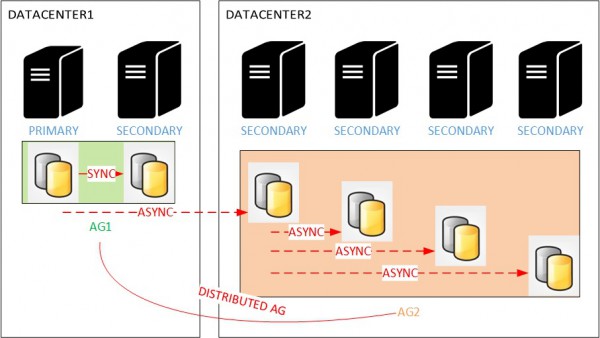
Distributed availability group feature will permit to offload the replication traffic from the primary to the read-only secondaries by using a replica on the second datacenter. Thus, we are able to reduce drastically the network bandwidth from 4 replicas to only one. In addition, adding one or several other replicas may be considered because this new architecture is more scalable and we will only impact local network bandwidth on the second datacenter.
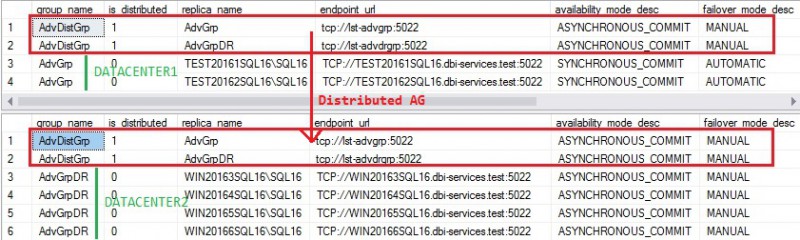
Here my new lab configuration after applying distributed availability groups on the previous architecture.
- In the first datacenter, one availability group AdvGrp that includes two replicas in synchronous replication and automatic failover for HA purpose
- In the second datacenter, one availability AdvGrpDR that includes four replicas enrolled as read-only.
- One distributed availability group AdvDistGrp which makes the cascade between the two aforementioned availability groups
Let’s run the same workload test on the new architecture and let’s have a look at the new output:
The log send queue size got back to normal at the primary replica level on the first datacenter by cascading all the previous replication traffic from the primary replica located to the second datacenter (AdvGrpDR availability group).
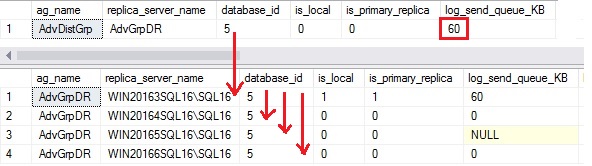
From a wait statistics perspective, we got rid of HADR_DATABASE_FLOW_CONTROL meaning we did not saturated the network link between the 2 datacenters

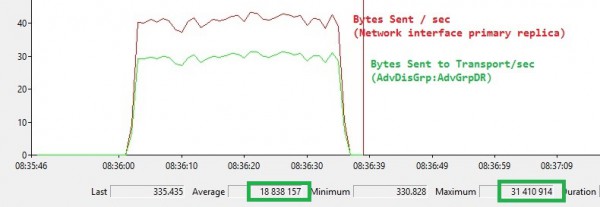
The picture below confirms the replication traffic dropped drastically with this new configuration (150 Mbps vs 400 Mbps from the first architecture).
Bottom line
In this blog post I tried to demonstrate using distributed availability groups to cascade the replication traffic to another replica may be a good idea in order to address scenarios which include many secondary replicas on a remote location with a Bylow network bandwidth. However introducing distributed availability groups has a cost in terms of management because we have to deal with an additional layer of complexity. But if the rewards make the effort worthwhile we should consider this kind of architecture.
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)