As you probably know Microsoft announced an official name for SQL Server vNext during the last Microsoft Data Amp event on April 19 2017. It becomes officially SQL Serve 2017.
In my first blog post, I wrote about SQL Server on Linux and the introduction of availability groups features. At this moment the SQL Server release version was CTP 1.3. As a reminder, with previous CTP releases, listeners were unusable because they did not persist when switch over events occurred as well as they didn’t provide any transparent redirection capabilities. Today, we are currently on the CTP 2.0 and this last CTP release comes with an important improvement concerning AGs with the support of listeners.
In this blog post I don’t want to write about creating an AG listener on Linux environment. The process is basically the same that creating a listener on Windows and it is well documented by Microsoft for a while. But several things shipped with the last CTP 2.0 have drawn my attention and will allow extending some scenarios with AGs.
First of all, from the Microsoft documentation we may notice a “Create for read-scale only” section. In a nutshell, we are now able to create a cluster-less availability group. Indeed, in this context we want to prioritize scale-out scenarios in favor of HA meaning the cluster layer is not mandatory here. That’s the point. Using Linux or Windows operating system in this case? Well, we may have a long debate here but let’s say we will use a Linux operating system for this scenario.
You also probably noticed that the CLUSTER_TYPE parameter includes now a new EXTERNAL value. So we may create an availability group? by using one of the following values:
- WSFC = A Windows Server Failover Cluster will manage the availability group
- EXTERNAL = An external entity will manage the availability group (pacemaker on Linux so far)
- NONE = No cluster entity will manage the availability group
In my opinion, introducing the EXTERNAL value does make sense regarding the previous CTP releases. Indeed we were able only to specify NONE value to either use an external entity to manage AGs or to use nothing for read-scale scenarios making it meaningless.
At the same time FAILOVER_MODE parameter includes also a new EXTERNAL value which must be specified when using an external entity to manage AGs failover. Before going further in this blog post let’s set the scene. A pretty basic environment which includes 3 high available replicas on Linux involved in a read-scale scenario meaning no extra layer of HA management and asynchronous mode as well.
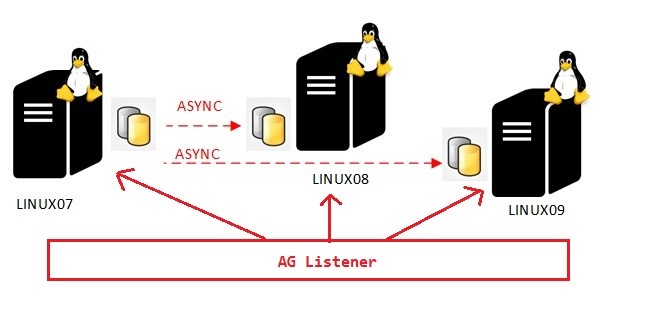
As a reminder, implementing a listener with corresponding read-only routes is very useful for the following reasons:
- Applications are transparently redirected to the corresponding read-only replica when read intent parameter is specified
- Since SQL Server 2016 applications may be redirected in a round-robin fashion, there’s no need to implement extra component (ok .. round-robin algorithm is pretty basic but that’s not so bad actually)
- Application does not need to know the underlying infrastructure. They have to connect to the AG listener and that’s it.
But in such scenario where no cluster layer is installed, we are not able to benefit from a floating virtual IP which is part of the automatic redirection to the primary replica in case of a failover event and as you already know, connections must be redirected to the primary in order to benefit from transparent redirection / round robin capabilities. So the remaining question is how to achieve redirection without a floating IP address in this case?
Firstly let’s say creating an AG listener on Linux doesn’t imply creating a corresponding virtual IP and Network Name on the cluster side and especially in this case where AG doesn’t rely on the cluster layer. However creating an AG listener that relies on the primary replica IP address to benefit from transparent / round-robin redirection remains a viable option. This is only the first part of the solution because we have also to address scenarios that include switchover events. Indeed, in this case, primary replica may change regarding the context and the current listener’s configuration becomes invalid (we refer to the previous primary’s IP address). At this stage, I would like to thank again @MihaelaBlendea from Microsoft who put me on the right track.
This is not an official / supported solution but it seems to work well according to my tests. Update 21.04.2017 : Mihaela has confirmed this is a supported solution from Microsoft.
The solution consists in including all the replica IP addresses included in the topology in the listener definition and we may use a DNS record to point to the correct primary replica after a manual failover event. Therefore, applications do have only to know the DNS record to connect to the underlying SQL Server infrastructure.
Here the definition of my availability group including the listener:
CREATE AVAILABILITY GROUP [AdvGrpDRLinux]
WITH
(
DB_FAILOVER = ON, --> Trigger the failover of the entire AG if one DB fails
CLUSTER_TYPE = NONE
)
FOR REPLICA ON
N'LINUX07'
WITH
(
ENDPOINT_URL = N'tcp://192.168.40.23:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC, --> use direct seeding
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'LINUX08'
WITH
(
ENDPOINT_URL = N'tcp://192.168.40.24:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC, --> use direct seeding
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'LINUX09'
WITH
(
ENDPOINT_URL = N'tcp://192.168.40.25:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC, --> use direct seeding
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
);
GO
ALTER AVAILABILITY GROUP [AdvGrpDRLinux] GRANT CREATE ANY DATABASE;
GO
ALTER AVAILABILITY GROUP [AdvGrpDRLinux]
ADD LISTENER 'lst-advgrplinux'
(
WITH IP ( ('192.168.40.23', '255.255.255.0'), --> LINUX07 IP Address
('192.168.40.24', '255.255.255.0'), --> LINUX08 IP Address
('192.168.40.25', '255.255.255.0') --> LINUX09 IP Address
)
, PORT = 1433
);
GO
Notable parameters are:
- CLUSTER_TYPE = NONE
- AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT
- FAILOVER_MODE = MANUAL
- Direct seeding is enabled.
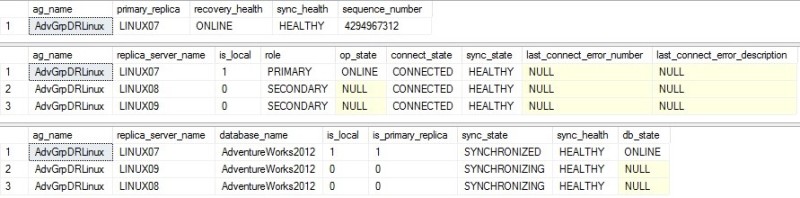
Let’s have a look at the AG configuration by using AG DMVs:
Then here the listener configuration:

And finally the configuration of my read-only routes and the priority list for redirection:
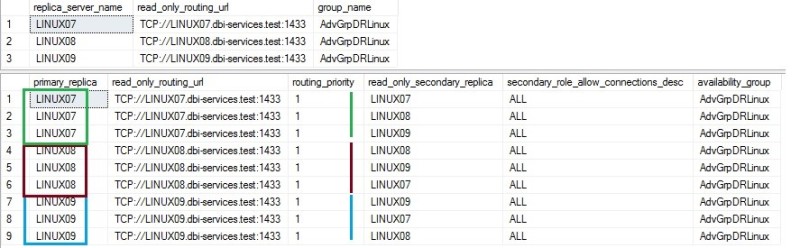
You may notice that I use round-robin capabilities for each replica.
I also created a DNS A record with the address of the current primary replica (lst-advgrplinux – 192.168.40.23). DNS record will be used by applications to connect the AdvGrpDRLinux AG.
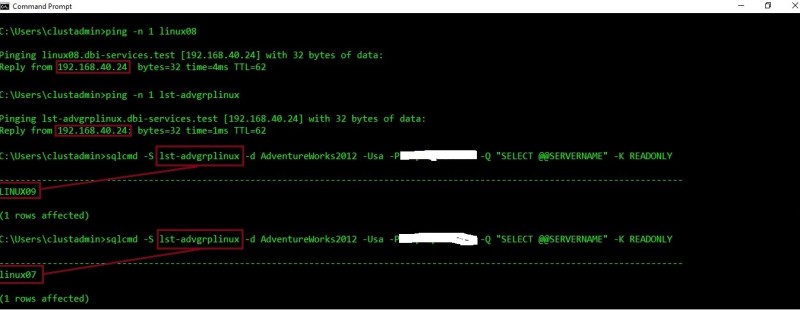
Let’s test the new configuration by using SQLCMD tool with –K READONLY option. Redirection and round-robin feature come into play. First test is conclusive.
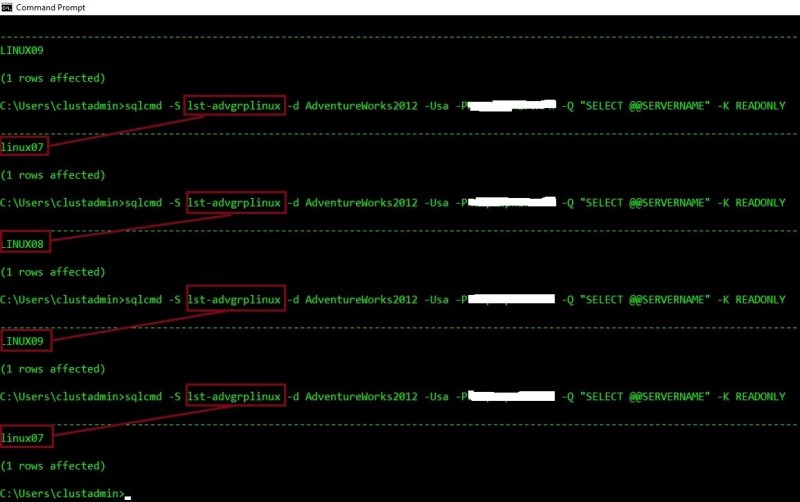
Go ahead and let’s perform a manual failover. In this case, the primary replica is still available, so I just switched momentary on synchronous mode to avoid resuming replication databases from secondary replicas afterwards. Then I performed a switch over to the LINUX08 replica. According to the Microsoft documentation, in order to guarantee no data loss I also changed temporary the REQUIERED_COPIES_TO_COMMIT to 1. Finally, after performing the manual failover successfully, I switched back to asynchronous mode (REQUIERED_COPIES_TO_COMMIT must be reverted to 0 in this case).
USE [master] GO -- switch momentary to synchronous mode ALTER AVAILABILITY GROUP [AdvGrpDRLinux] MODIFY REPLICA ON N'LINUX07' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [AdvGrpDRLinux] MODIFY REPLICA ON N'LINUX08' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [AdvGrpDRLinux] MODIFY REPLICA ON N'LINUX09' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [AdvGrpDRLinux] SET (REQUIRED_COPIES_TO_COMMIT = 1) -- demote old primary replica LINUX07 ALTER AVAILABILITY GROUP [AdvGrpDRLinux] SET (ROLE = SECONDARY); -- switch to new primary replica LINUX08 :CONNECT LINUX08 -U sa -PXXXXX ALTER AVAILABILITY GROUP [AdvGrpDRLinux] FAILOVER; GO -- revert back to asynchronous mode :CONNECT LINUX08 -U sa -PXXXXX ALTER AVAILABILITY GROUP [AdvGrpDRLinux] SET (REQUIRED_COPIES_TO_COMMIT = 0) ALTER AVAILABILITY GROUP [AdvGrpDRLinux] MODIFY REPLICA ON N'LINUX07' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [AdvGrpDRLinux] MODIFY REPLICA ON N'LINUX08' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [AdvGrpDRLinux] MODIFY REPLICA ON N'LINUX09' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
After updating the DNS record to point to the new primary replica – LINUX08 with IP address equal to 192.168.40.24, transparent redirection and round-robin capabilities continued to work correctly.
See you soon for other interesting new scenarios with availability groups on Linux!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)