Have you ever faced to timeout issues with SQL Server availability groups? If you take a look at the timeout parameters for an availability group, you will find a plenty of configuration settings. Indeed, you have timeout parameters for the availability group itself, for the replicas and for cluster itself as well.
Well …a lot of parameters in order to deal with timeout issues. In fact, some of them can be very helpful regarding the scenario but we have to be aware of their downsides.
First of all, let me begin a preliminary work by illustrating the timeout parameters at the different layers with the following picture:
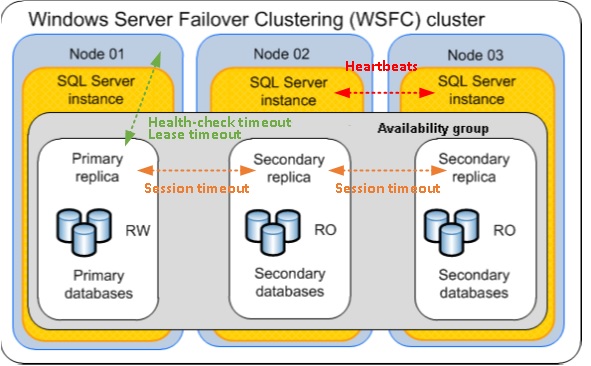
- Session timeout (replica layer)
- Health-check and lease time (between the WSFC and the primary replica)
- Heartbeat mechanism between cluster nodes
In this first blog post we’ll focus on the session timeout parameter.
Have you ever seen a message related to the session timeout issue like as follows in the SQL Server error log?
A connection timeout has occurred on a previously established connection to availability replica ‘WIN20162\SQL14’ with id [B9B83D6D-1F6C-4FA8-AF04-C734005B5D80]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
From my part, since one year, I began to face this error message at several customer places. The problem was almost the same and issued by a third party tool – Veeam backup- while performing a virtual machine snapshot either on the primary or the secondary replicas (Note that on the primary the side effect may be more important than a simple record in the error log). It is important to precise that Veeam backup software runs on the top of VMWare and the problem is often caused by the lack of connectivity that can occur in VMware vSphere during the snapshot operations (aka the stun period. Please refer to the VMWare KB here for more details). During the stun period, the virtual machine may hang and lost the connectivity with others replicas if it reaches the session timeout threshold (10s by default).

In this blog post, I used this example because it was relevant in most cases and it will help me to illustrate the side effect of a poorly configuration but of course you may be concerned by other problems in your case.
Generally speaking, the session timeout protects a SQL Server instance against soft errors by avoiding waiting indefinitely a response from the other replicas in the same session. Softs errors are not generally on the scope of the SQL Server issue detection. Basically, the mechanism consists of a ping detection between replicas. On receiving a ping, an availability replica resets its session-timeout counter on that connection. Otherwise, the replica times out and disconnects. Note that unlike the mirroring feature, this parameter doesn’t affect the failover behavior of an availability group.
By the way, it is possible to increase the timeout period in some scenarios – e.g. with multi-subnet scenarios but to be honest I had very few opportunities to play with this parameter because I was often lucky with customers that have a good inter site connections J- However, we should be aware with the side effect of changing this parameter. To illustrate the problem let’s come back to my virtual machine hanging scenario. We may think that increasing the session timeout threshold may solve quickly our problem. After all, this is a false positive problem in this case right? But let’s precise that we are in a synchronous replication and in this case configuring a very high value can have a negative impact on your workload in the case of unresponsive secondary replica scenario.
Let’s perform a pretty simple test and by inserting a record in the table as follows:
insert dbo.t1 default values;
At the same time, a network issue occurs on the secondary replica side. After 10 seconds, the session times out and the state of the secondary (WIND20126\SQL14) is changed to DISCONNECTED.

And as expected, my query finished after roughly 10s.

But how about increasing more the session timeout?
Well let’s increase the value to 360 seconds as a real customer case. The idea behind was to get rid of the disconnection error message on the secondary that triggered email alerts to the IT infrastructure during the Veeam backup process. Yes, we don’t like to wake up during the night for a false positive alert 🙂
use [master]; go alter availability group AG2014 modify replica on 'WIN20162\SQL14' with (session_timeout = 360); go
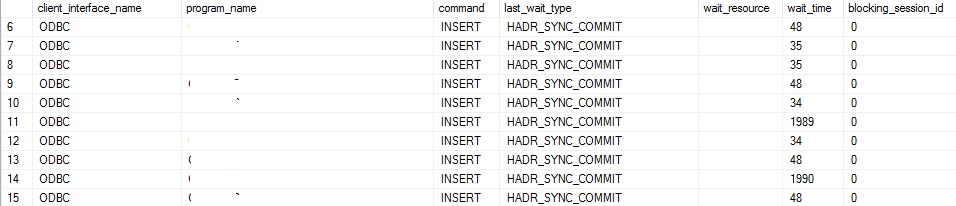
In this specific context, we noticed after a couple of weeks that the significant part of the wait statistics concerned the HADR_SYNC_COMMIT as follows:

According to the Microsoft documentation, it seemed we experienced slow synchronization performance but we found out nothing during the business hours. However, after further investigations, we got a clue from a lot of batch processes during the night that were abnormally “frozen” at the same time of the Veeam backup operation on the secondary. We got a similar picture of the situation than below:
We also experienced some kind of hanging scenarios where the primary appears to be blocked because we ran out of worker threads. We got this information from the SQLDIAG file as shown below:
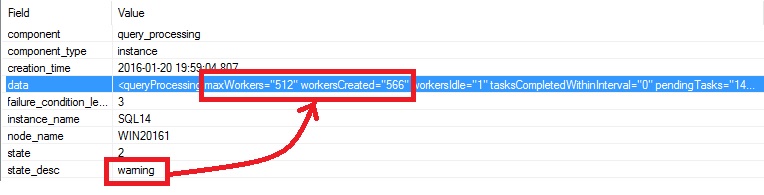
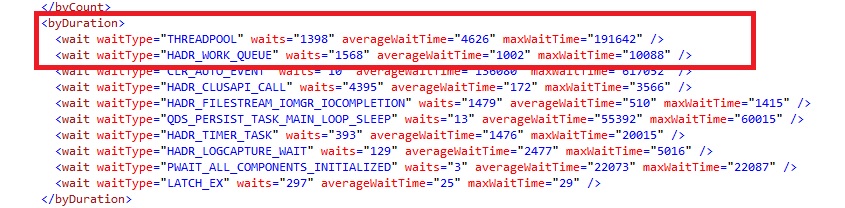
THREADPOOL wait type is often symptomatic of worker threads exhaustion issue.
Anyway … fortunately in my case the impact was not too big but I let you imagine the scenario with this kind of issue during the business hours …
In a nutshell, take care of the final value when you configure the session timeout parameter. It can save the situation in some specific scenarios or completely lead to a very negative experience!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)