I would like to share with you an interesting issue you may face while using SQL Server AlwaysOn availability groups and secondary read-only replicas. For those who use secondary read-only replicas as reporting servers, keep reading this blog post because it is about update statistics behavior on the secondary replicas and as you may know cardinality estimation accuracy is an important part of the queries performance in this case.
So a couple of days ago, I had an interesting discussion with one of my MVP French friend about an availability group issue he faced at a customer shop and related to the above topic. Without going into details now, he was surprised to see a difference between the primary replica and one secondary about last update statistic dates as well as rows sampled value for specific statistics. The concerned environment runs with SQL Server 2014 SP2.
First of all, let’s say that having different updated statistic dates between a primary and a secondary is part of a normal process. Indeed, changes related to statistic objects are replicated over the time from the primary to secondaries but it is not uncommon to encounter situation where data from the primary is updated until reaching the update statistic threshold value and to notice auto update statistics triggered by SQL Server on the secondary replica from Reporting queries. But what is more surprising is that this behavior noticed by my friend was exacerbated in his specific context with large tables.
Let’s demonstrate with an example. I was able to easily reproduce the issue on my environment but I was also interested in testing behaviors from different versions of SQL Server in response to this specific issue. In fact, I tried to figure out if the problem concerned only a specific build of SQL Server – SQL Server 2014 SP2 in this case – or if the problem concerns all the SQL Server versions.
Let’s use the AdventureWorks2012 database with the bigTransactionHistory table that contains roughly 34 million of rows (343910073 rows).
Let’s say statistic information you will see later in this blog post came from each secondary that runs on a specific SQL Server version (respectively 2012, 2014 and 2016) by using the following T-SQL script on each secondary replica.
use AdventureWorks2012;
select
object_name(s.object_id) as table_name,
s.name as stat_name,
s.is_temporary,
ds.last_updated,
ds.modification_counter,
ds.rows,
ds.rows_sampled,
CAST(ds.modification_counter * 100. / ds.rows AS DECIMAL(5,2)) AS modif_ratio,
ds.steps
from sys.stats as s (nolock)
cross apply sys.dm_db_stats_properties(s.object_id, s.stats_id) as ds
where s.object_id = object_id('dbo.bigTransactionHistory');
go
Let’s begin with the starting scenario where I inserted approximatively 20% of the initial data in the bigTransactionHistory table as you may notice below. During the test we will focus only on the idx_cl_big_TransactionHistoryTransactionDate statistic related to the clustered index on the bigTransactionHistory table.
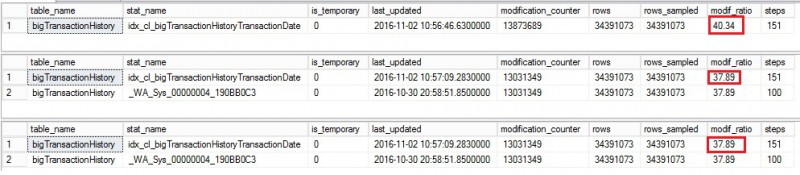
Let’s update then the idx_cl_big_TransactionHistoryTransactionDate statistic with FULLSCAN from the primary replica. This operation may be part of a maintenance plan on daily / monthly basis depending on your scenario. Here a picture of statistic information from each secondary:
Regarding this first output, we may notice that the modification counter from thesys.dm_db_stats_properties DMF did not drop to zero. To be honest I expected a value equal to 0 here. In addition, executing a Reporting query from each secondary did not have effect in this case. The reporting query is as follows and it is designed to use specifically the idx_cl_big_TransactionHistoryTransactionDate statistic.
use AdventureWorks2012; select count(*) from dbo.bigTransactionHistory where TransactionDate between '20060101' and '20080101'; go
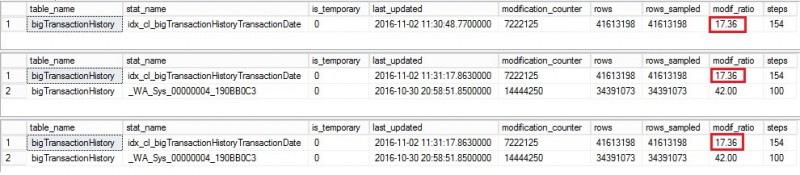
Keep going and let’s continue by inserting a new bunch of data (approximatively 10% more). After running a new update statistics operation with FULLSCAN from the primary (let’s say we are again in the situation where a maintenance plan comes into play) here the corresponding statistic information output from each secondary:
As expected, the modification of the rows counter value increased up to 24% but once again we may only notice that running update statistics with FULLSCAN on the primary doesn’t reset correctly the modification rows counter on the secondary regardless the SQL Server version. Let’s run the Reporting query from each secondary and let’s have a look at the statistic information output
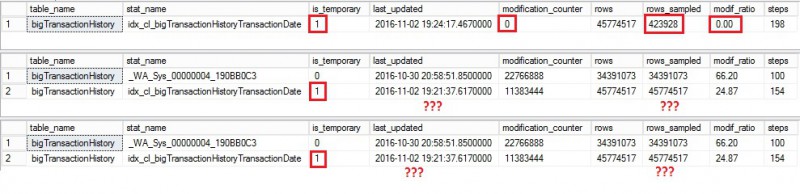
Well, it seems that some update statistics stuff came into play but surprisingly we get different results between versions. Let’s focus first on SQL Server 2012 (first line) where an auto update statistics operation was triggered by SQL Server. Thus the last_updated column value was updated, the concerned statistic is now defined as temporary on the concerned secondary replica and the rows sampled value is different from the previous step (423928 vs 45774517). This is because SQL Server used a default sampling algorithm in this case which does not correspond to that using in the previous step with FULLSCAN method.
Then if we move quickly to the last two lines (respectively SQL Server 2014 and 2016), we may notice only one change that concerns the is_temporary column and no changes concerning either the last update statistic date, the modification counter value or sampled rows. At this point, I’m not sure to understand the reason. Is it a metadata issue? Is it a normal behavior? Well, I will go back there to update this section if I get further information.
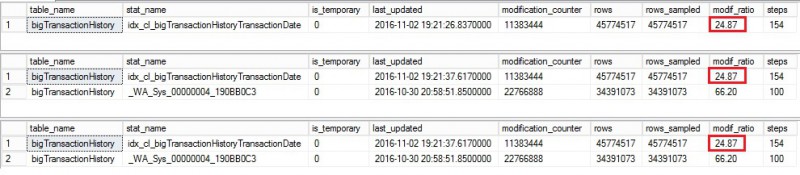
Let’s continue by performing the same previous tasks (insert a bunch of data and then update statistics with FULLSCAN from the primary). The statistic output from each secondary is as follows:
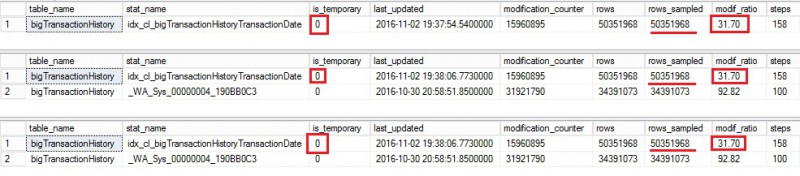
I’m sure you are beginning to understand what’s happening here. The update statistic with FULLSCAN from the primary replica seems to never reset the modification counter on each secondary. This is a big problem here because if we execute the Reporting query on each secondary we have now good chance to invalidate quickly what has been done by the update statistics operation with FULLSCAN from the primary. In our context, the main concern is the sampled rows value that can lead to inaccurate cardinality estimations. Let’s run again the Reporting query from each secondary and let’s have a look at the corresponding statistics information output
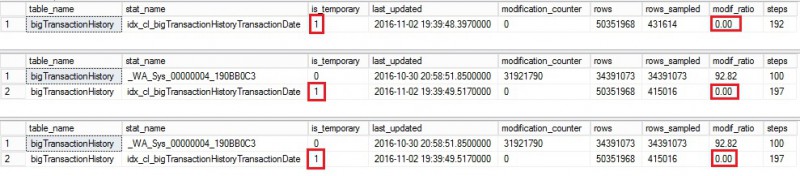
Got it! This time, each concerned statistic switched to temporary and the modification counter was reset to 0. Note also that a default sampling was used in this case in contrast to previous picture that concerned update statistic with FULLSCAN. And if I continue ever and ever in this way I will face every time the same behavior for all versions of SQL Server since 2012.
Let’s summarize the situation: in common scenarios, we would probably not pay attention to this specific issue because cardinality estimation will not be affected and statistics concerned by Reporting queries on the secondaries are fewer in order of magnitude. But my friend encountered a specific scenario with large tables where the issue is magnified.
As workaround, you may consider to exclude the concerned statistic(s) from the auto update statistics algorithm (NORECOMPUTE option). You may also vote for the following connect item opened by my friend if it makes sense for you!
Update 22.02.2018 (thanks Balmukund): Issue is fixed (cf. KB4013236)
Hope it helps!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)