In this blog post I just want to clarify values that we may find from the is_failover_ready column of the sys.dm_hadr_database_replica_cluster_states DMV. A couple of days ago, I had an interesting discussion with one of my customers during which he explained he was not confident about the availability group state after facing some unavailability issues.
The main source of uncertainty was the result from the following query that he used to check if everything was ok.
SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.availability_replicas)
I’m not able to expose directly the real customer context but I may easily reproduce the same result with my environment. So let’s say that my environment includes two availability replicas in synchronous mode and a third in asynchronous mode. An availability group testGrp has been configured and hosts an availability database named test. I have run the same query as my customer and here the result:
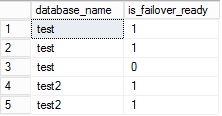
Referring to the BOL, the sys.dm_hadr_database_replica_cluster_states contains information intended to provide us with insight into the health of the availability databases in each Always On availability group including which databases in an availability group ready for a failover.
My customer was precisely confused by this last point because he found out a lot of value equal 0 for some databases and thought that his entire availability group was unhealthy.
But first things first. The main problem with the above query is probably the lack of information about the involved replicas. Therefore, I asked my customer to execute a modified version of his initial script:
select ag.name, ar.replica_server_name, ar.availability_mode_desc as [availability_mode], ars.synchronization_health_desc as replica_sync_state, rcs.database_name, drs.synchronization_state_desc as db_sync_state, rcs.is_failover_ready, rcs.is_pending_secondary_suspend, rcs.is_database_joined from sys.dm_hadr_database_replica_cluster_states as rcs join sys.availability_replicas as ar on ar.replica_id = rcs.replica_id join sys.dm_hadr_availability_replica_states as ars on ars.replica_id = ar.replica_id join sys.dm_hadr_database_replica_states as drs on drs.group_database_id = rcs.group_database_id and drs.replica_id = ar.replica_id join sys.availability_groups as ag on ag.group_id = ar.group_id
And the result was the same as below:

So the situation is clearer now and we may easily understand that this value is basically normal here. Indeed, the involved replica (WIN20123SQL16\SQL16) is running in asynchronous commit mode and the enrolled database cannot be ready for failover by design.
Then, let’s deal with a disaster recovery scenario that includes restarting the WSFC in forced quorum mode. Let’s say we have lost both WIN20121SQL16\SQL16 and WIN20122SQL16\SQL16 replicas at the same time during an entire datacenter failure. The normal step will probably consist in performing a manual failover (and allow data loss) of the concerning availability group from the WIN20123SQL16\SQL16 replica.
The new picture is:

The WIN20123SQL16\SQL16 replica has become the new “forced” primary. However let’s have a look at its synchronization state that is SYNCHRONIZED here whereas other replicas are not health. State of WIN20121SQL16\SQL16 and WIN20122SQL16\SQL16 are obvious here but it may be a little bit surprising about WIN20123SQL16\SQL16 replica state. The previous synchronization state of this replica before the general failure was SYNCHRONIZING and not ready for failover. Therefore in this case we may not trust blindly the value of is_failover_ready column.
Go ahead and after fixing the situation (failing datacenter is now online), we just have to resume the test database. The new situation is as follows:

Replicas and synchronization states are all healthy but because the new primary is in asynchronous mode, the test databases on the new secondaries are not ready for failover (even if the availability mode is in synchronous commit mode). At this point changing only the availability mode of the new secondaires to SYNCHRONOUS COMMIT may change the game as shown below:

As an aside, this is what I recommend to my customers in order to switchover smoothly from a DR replica in asynchronous replica to another synchronous replica. Indeed, keeping the asynchronous availability mode in this case will lead to keep the database not ready for failover if we force failover with allow data loss. So, here the final picture of our scenario:

In this last section, let’s talk about another interesting scenario where the third replica (WIN20131SQL16\SQL16) previously in asynchronous mode is synchronous now and let’s replay the same disaster recovery scenario as previously. Firstly, let’s say the third replica becomes unhealthy caused by a network failure between the two datacenters. In fact, after reaching the session timeout threshold, this synchronous replica becomes asynchronous temporarily. At the same time, DML workload still occurs on other replicas (WIN20121SQL16\SQL16 and WIN20122SQL16\SQL16). Regarding the last_commit_lsn and last_commit_time values from the sys.dm_hadr_database_replica_states DMV, we may notice that the third replica is now far behind from others as shown below:

Let’s say now we still get unlucky with the first datacenter failure that includes the WIN20121SQL16\SQL16 and WIN20122SQL16\SQL16 replicas. In this case, the WSFC has lost the quorum and forcing quorum from the remaining WIN20123SQL16\SQL16 replica (that was previously disconnected) doesn’t reflect the real cluster state at the moment of the first datacenter failure.
select ag.name, ar.replica_server_name, ar.availability_mode_desc as [availability_mode], ars.synchronization_health_desc as replica_sync_state, rcs.database_name, drs.synchronization_state_desc as db_sync_state, rcs.is_failover_ready, rcs.is_pending_secondary_suspend, rcs.is_database_joined from sys.dm_hadr_database_replica_cluster_states as rcs join sys.availability_replicas as ar on ar.replica_id = rcs.replica_id join sys.dm_hadr_availability_replica_states as ars on ars.replica_id = ar.replica_id join sys.dm_hadr_database_replica_states as drs on drs.group_database_id = rcs.group_database_id and drs.replica_id = ar.replica_id join sys.availability_groups as ag on ag.group_id = ar.group_id select ag.name as aag_name, ar.replica_server_name, d.name as [database_name], hars.is_local, hars.synchronization_state_desc as synchronization_state, hars.synchronization_health_desc as synchronization_health, hars.database_state_desc as db_state, hars.is_suspended, hars.suspend_reason_desc as suspend_reason, hars.last_commit_lsn, hars.last_commit_time from sys.dm_hadr_database_replica_states as hars join sys.availability_replicas as ar on hars.replica_id = ar.replica_id join sys.availability_groups as ag on ag.group_id = hars.group_id join sys.databases as d on d.group_database_id = hars.group_database_id order by aag_name, replica_server_name

Indeed, we may notice the WIN20123SQL16\SQL16 synchronization state is now SYNCHRONIZED and ready for failover but in fact it is not. Once again we may not trust the is_failover_ready column value. As stated by Microsoft here, the is_failover_ready value for a particular database is available only if the related host replica is up at the time of the failure.
So if we revert back to the initial picture, we will face data loss because commit_lsn value of new secondary replicas will be revert back to the out-of-date commit_lsn value from the new primary.

Hope it helps!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)