A couple of months ago, we experienced with my colleague Nathan Courtine a weird issue at one of our customers. This issue concerned an AlwaysOn availability group and more precisely to the WSFC cluster layout. I can’t say strongly enough that the AlwaysOn availability group runs on the top of the WSFC and having a good understanding of the internal stuff can help a lot for troubleshooting.
First of all, let me introduce the issue that began by an SQL Server alert and the error 35262 meaning that we potentially face an availability group failover. So the environment was pretty basic and consisted of several availability groups that run with SQL Server 2012 SP1 and hosted by several replicas. Furthermore, the SQL Server environment runs on the top of a WSFC that consist in two cluster nodes on the same subnet.
The first investigation led us to conclude that a third party backup software was the root cause of availability group instability. In fact, during the backup time frame, the third party tool had frozen the concerned primary replica long enough to trigger a failover of the availability groups to the secondary cluster node. I also faced the same kind of issue which is described here.
However, the most interesting part of the story is not here. So keep reading… After the availability group’s failover, the normal process would be to bring it online on the new primary replica as well as its respective resources on the WSFC side. However, that didn’t happen in our case: the corresponding cluster resources failed over on the second cluster node but the WSFC service restarted continuously all the night until the customer decided to restart completely the node the morning after. We noticed a lot of related errors in the Windows error log as shown below:
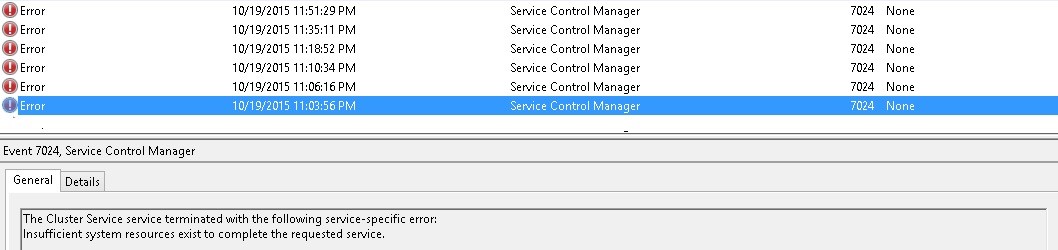
Referring to the above errors, we may think first to an out of memory issue but after checking my colleague told me the problem was not there. In fact, there was enough memory on the concerned server (some gigabytes). Then we decided to take a look at the cluster log and we noticed some interesting information inside. Here one sample among others with the same pattern. Let’s focus on the records in bold.
00000624.00000ee0::2015/10/19-21:03:41.107 INFO [RCM] rcm::RcmGum::GroupMoveOperation(AAG_XXXX,2)
00000624.000014d4::2015/10/19-21:03:56.875 INFO [RCM] Group move for ‘AAG_XXXX’ has completed.
0000163c.000013a8::2015/10/19-21:03:56.721 INFO [RES] SQL Server Availability Group <AAG_XXXX>: [hadrag] Current SQL Instance is not part of Failover clustering
0000163c.000013a8::2015/10/19-21:03:56.721 INFO [RES] SQL Server Availability Group: [hadrag] Starting Health Worker Thread
0000163c.00001528::2015/10/19-21:03:56.730 INFO [RES] SQL Server Availability Group: [hadrag] XEvent session XXXX is created with RolloverCount 10, MaxFileSizeInMBytes 100, and LogPath ‘C:\Program Files\Microsoft SQL Server\MSSQL11.XXXX\MSSQL\LOG\’
0000163c.00001528::2015/10/19-21:03:56.730 INFO [RES] SQL Server Availability Group: [hadrag] Extended Event logging is started
0000163c.00001528::2015/10/19-21:03:56.730 INFO [RES] SQL Server Availability Group: [hadrag] Health worker started for instance XXXX\XXXX
00000624.000016d4::2015/10/19-21:03:56.884 INFO [RCM] rcm::RcmApi::AddPossibleOwner: (AAG_XXXX, 2)
00000624.000016d4::2015/10/19-21:03:56.884 INFO [RCM] rcm::RcmGum::AddPossibleOwner(AAG_XXXX,2)
00000624.000016d4::2015/10/19-21:03:56.886 ERR [DM] Dm::Hive::PerformReplicatedOperation: STATUS_INSUFFICIENT_RESOURCES(c000009a)’ because of ‘::NtRestoreKey( reinterpret_cast<::HANDLE>( hiveHandle.handle ), nullptr, RegistryOptions::RefreshHive)’
00000624.000016d4::2015/10/19-21:03:56.886 ERR Operation failed on a local hive (status = 1450)
00000624.000016d4::2015/10/19-21:03:56.886 ERR Operation failed on a local hive (status = 1450), executing OnStop
00000624.000016d4::2015/10/19-21:03:56.886 INFO [DM]: Shutting down, so unloading the cluster database.
00000624.000016d4::2015/10/19-21:03:56.886 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
00000624.000016d4::2015/10/19-21:03:56.887 ERR [DM] Error while restoring (refreshing) the hive: STATUS_INSUFFICIENT_RESOURCES(c000009a)
We can notice that the system has detected that the primary node is no more reachable and has performed a failover of the concerned availability group by using the rcm::RcmGum::GroupMoveOperation API. Moreover, let’s have a look at the STATUS_INSUFFICIENT_RESOURCES message that is related to a cluster registry issue – NtRestoreKey( reinterpret_cast<::HANDLE>( hiveHandle.handle ), nullptr, RegistryOptions::RefreshHive .
RegistryOptions::RefreshHive is probably part of the internal registry process handled by the database manager itself. There is also an additional registry WFSC check-pointing process for non-cluster aware applications. Indeed, when a resource comes online, the checkpoint manager is responsible to synchronize the cluster registry hive between nodes and this is also the case with SQL Server FCI and important registry keys. You can get an idea of these registry keys replicated by the checkpoint manager by using the PowerShell cmdlet Get-Clustercheckpoint as follows:
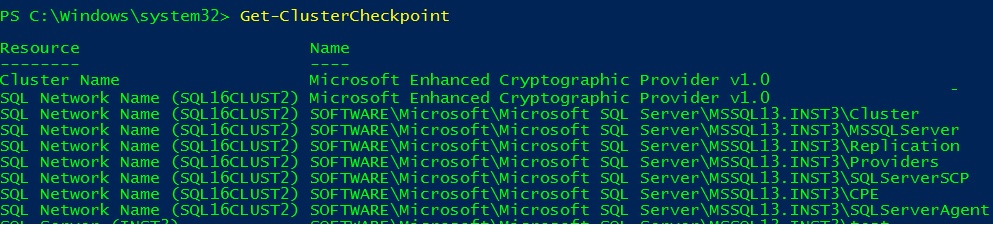
Let’s have a quick idea of this process by adding a registry key named “test” to my existing SQL Server FCI named SQL16CLUST2\INST3.
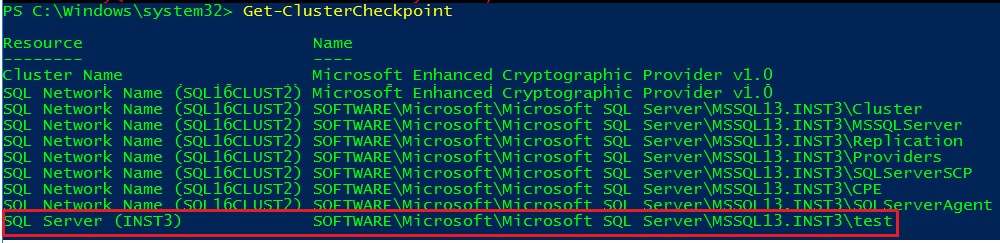
Add-ClusterCheckpoint - ResourceName “SQL Server (INST3)” -RegistryCheckPoint “SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL13.INST3\test”
You can see the new key added to the list of replicated registry keys by the checkpoint manager
You may test by yourself to verify if the registry is correctly replicated after initiating a failover of your SQL Server FCI or other role. Notice that in my case we used a FSW and the system will use a paxos tag to understand which node has the most up-to-date version of the cluster database.
So let’s go back to the issue. The billion dollar question here is why the database manager is not able to refresh correctly the cluster registry hive? To answer, we had to move on the registry side. I asked my colleague to get the size of the registry on this cluster node and here what he found:
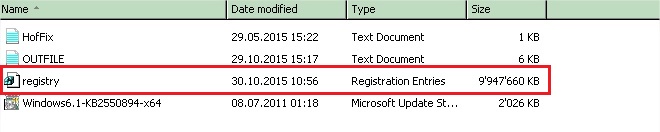
Yes, you’re not dreaming! The registry has roughly reached the total size of 9GB and it was exactly the root cause of our issue. I remembered to face the same issue in the past in other context and have read this very interesting technet blog post. Referring to this blog post, we know that the registry hive is limited to 2GB even on x64 systems. In the context of our customer, the registry was bloated with a lot of records related to the same issue:
Description: Detection of product ‘{A7037EB2-F953-4B12-B843-195F4D988DA1}’, feature ‘SQL_Tools_Ans’, Component ‘{0CECE655-2A0F-4593-AF4B-EFC31D622982}’ failed. The resource” does not exist.
After some investigations, we found out a related KB2793634 to solve it but unfortunately it was too late in our context. Indeed, we decided finally with the customer that the safest solution would be to perform a new fresh installation and applying the hotfix rather than attempting to clear the registry.
I admit that this issue is the exception but for us it was a good opportunity to learn further about how the cluster registry and the checkpoint manager work. We’ve seen that the registry check-pointing is an important part but often obscured in order to the failover cluster works properly.
Happy clustering!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)