In this blog-post I will discuss about my first test with Striim. Striim is a data integration platform which can ingest real-time data from a variety of sources (SQL Server, Oracle, Kafka, Hadoop…) and quickly deliver it to Cloud systems or even to an on-premise infrastructure.
The goal today will be to do the creation of my schema data in my Azure SQL Database and run a first initial load of my data.
The final step will be to execute real time DML on our target once executed on our source to provide for example offloaded live reporting capabilities without affecting the source.
Once Striim platform has been installed and configured, we can open the application via Chrome and see this main screen:
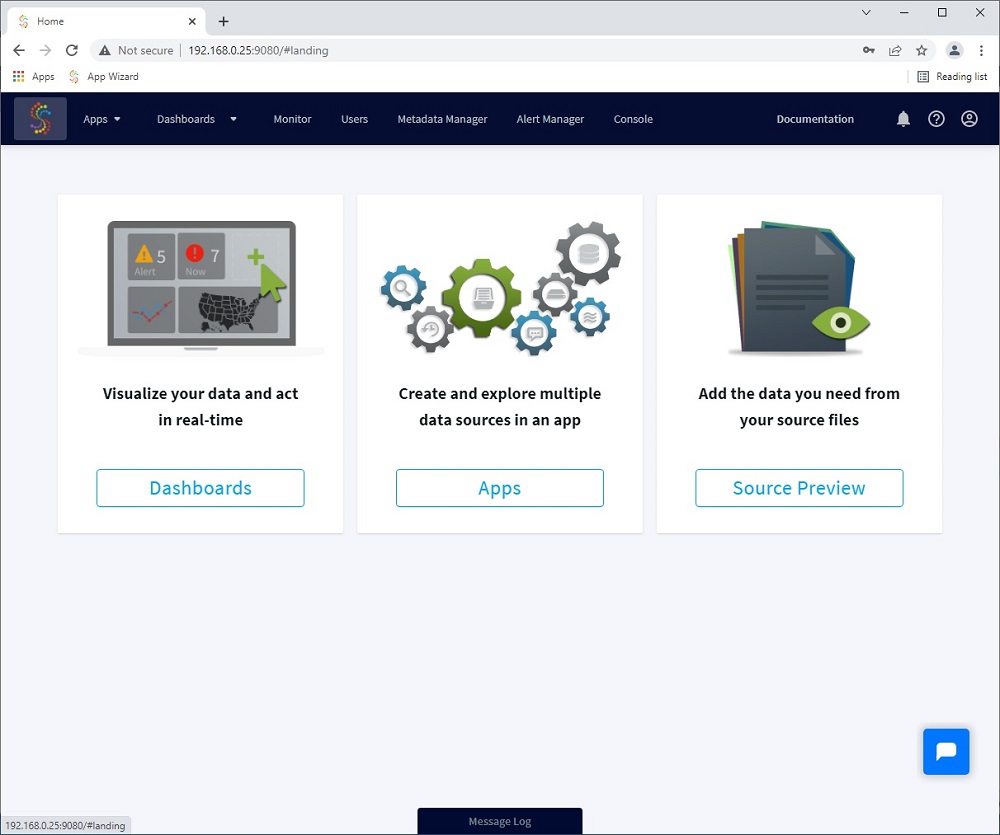
Click on Apps and select “Create new”.
You have the choose to create your flows by dragging in components in the “Build using Flow Designer” part or you can select a faster way with “Build using Wizards” which will propose you predefined wizards based on the source and target you have.
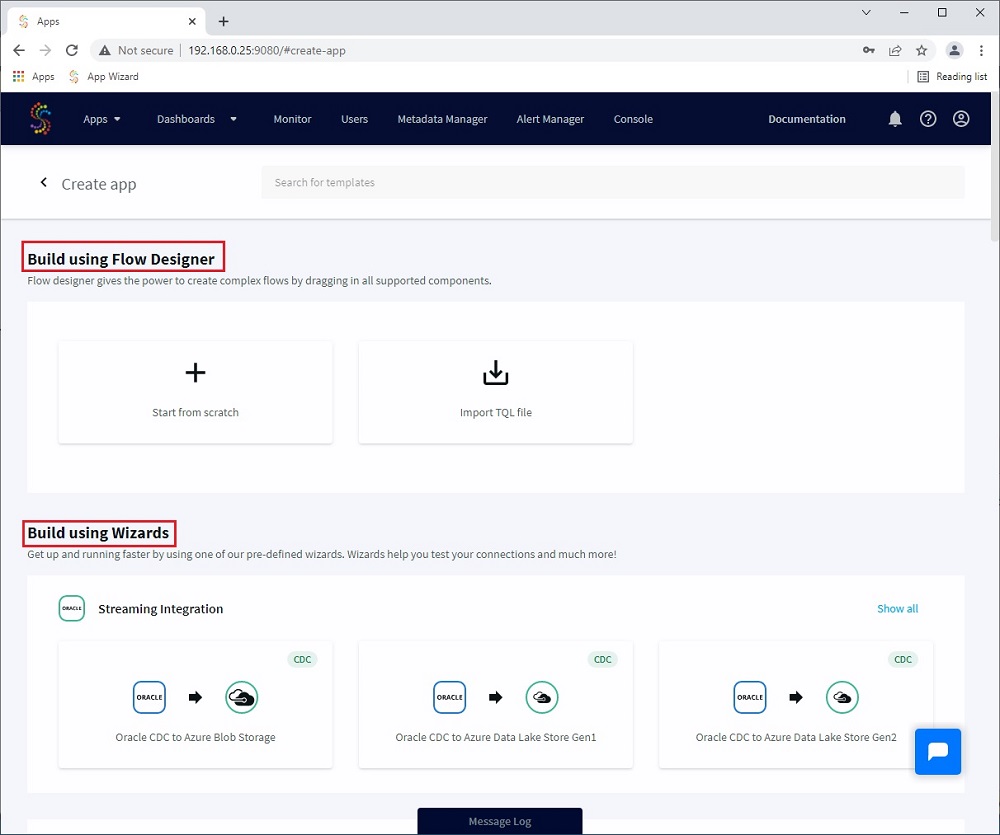
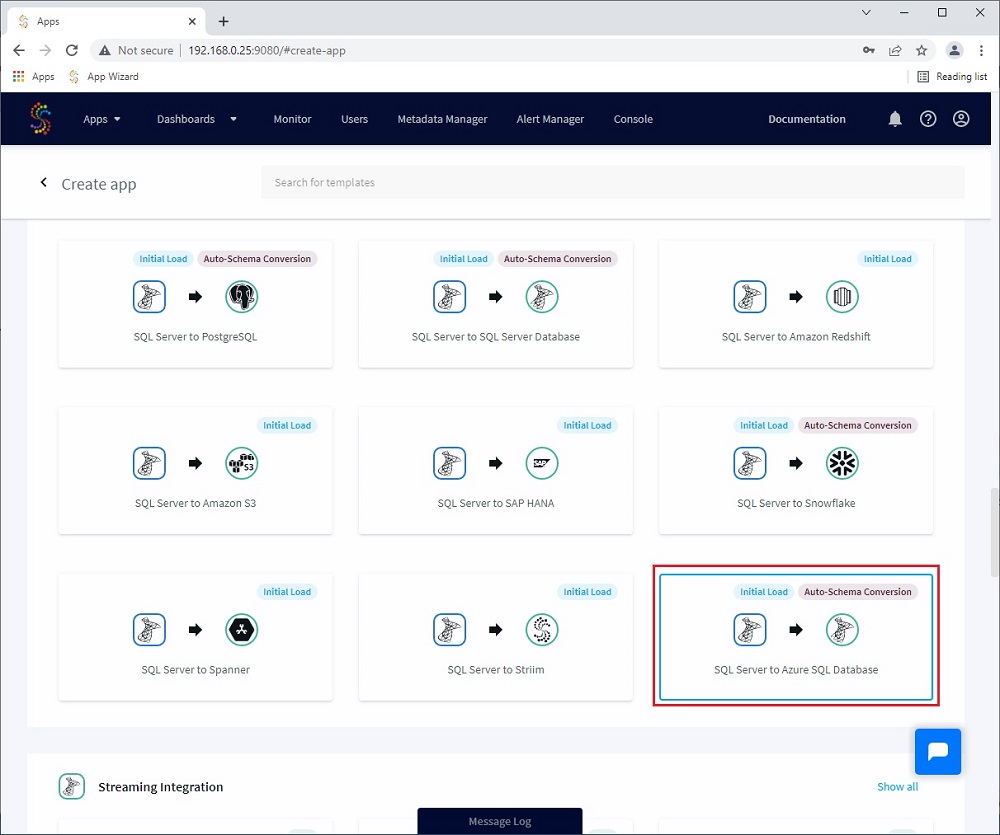
I will use a Wizard for this example as the first task I need to perform is a first initial load on my Azure SQL Database.
Name your initial load:
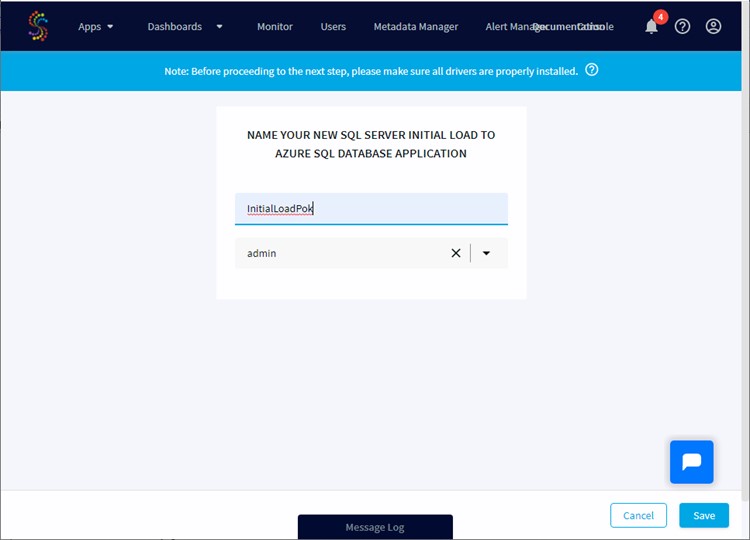
Once done, a popup tells me that the new application has been created and I can start to enter information about my source database. For this example I will use a local instance where a database named Pokemon is available and connect with a specific SQL user:
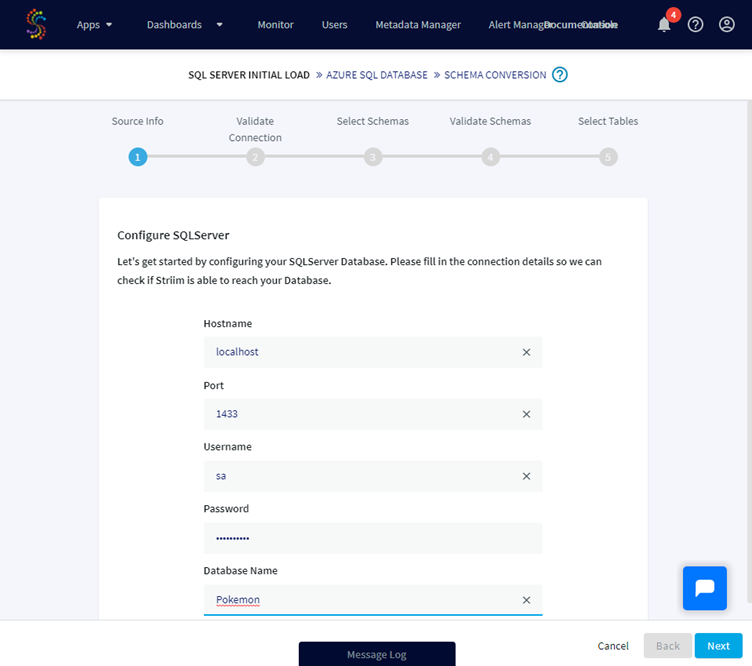
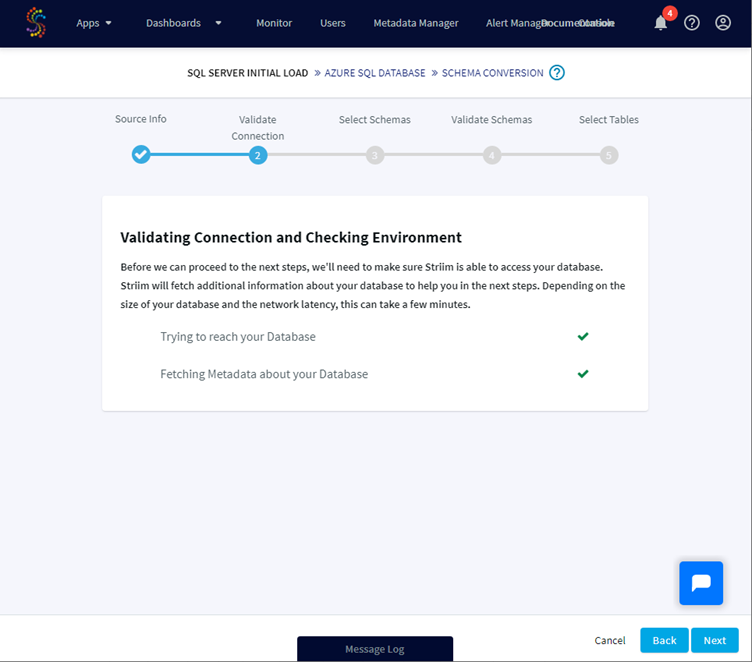
A validation check is done based on your connection details and if Striim can connect to the source database you can go ahead:
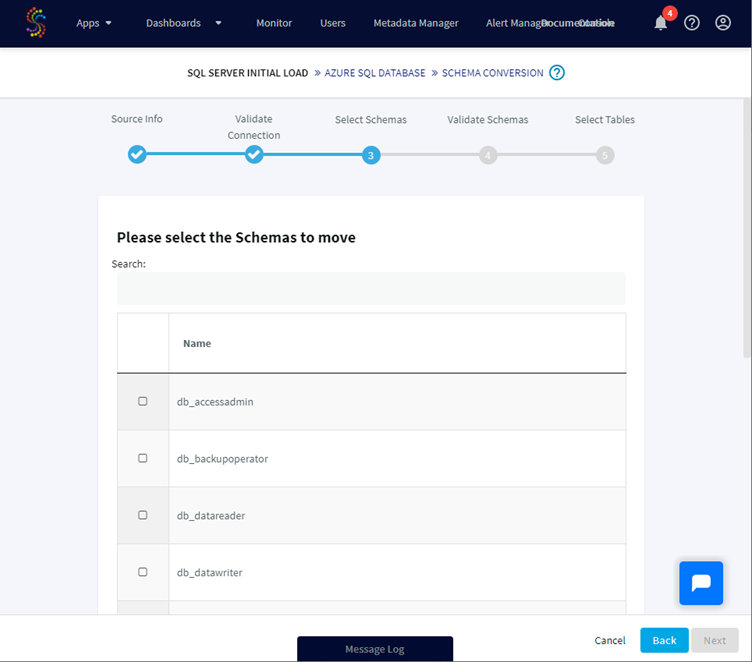
We have now to select which schemas to move, I will select just dbo.
Once done Striim is validating the selected schema(s):
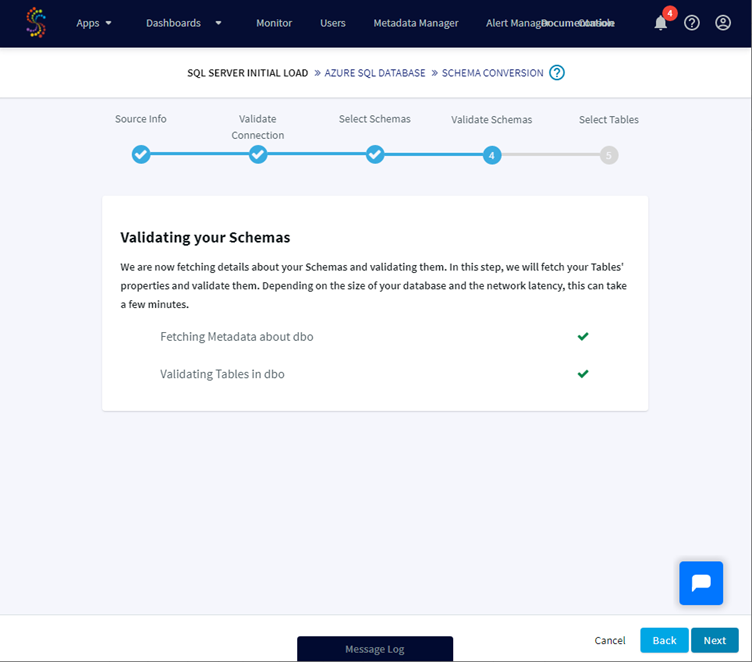
For the selected schema(s), we can now select the tables we would like to load. Some tables can be not selectable due to the error: “table cannot be moved due to incompatible Datatypes”, for example tables containing uniqueidentifier are not supported. Please check this compatibility matrix to know more about it and unsupported types.
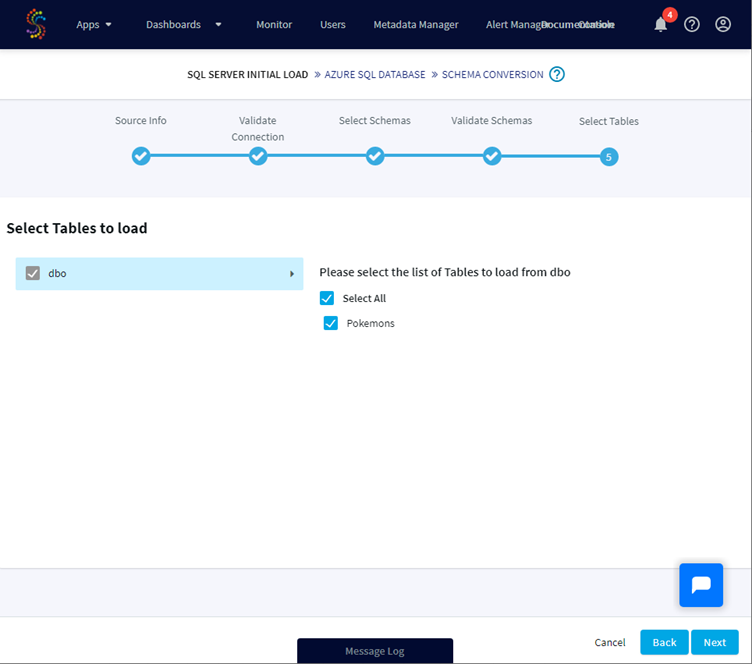
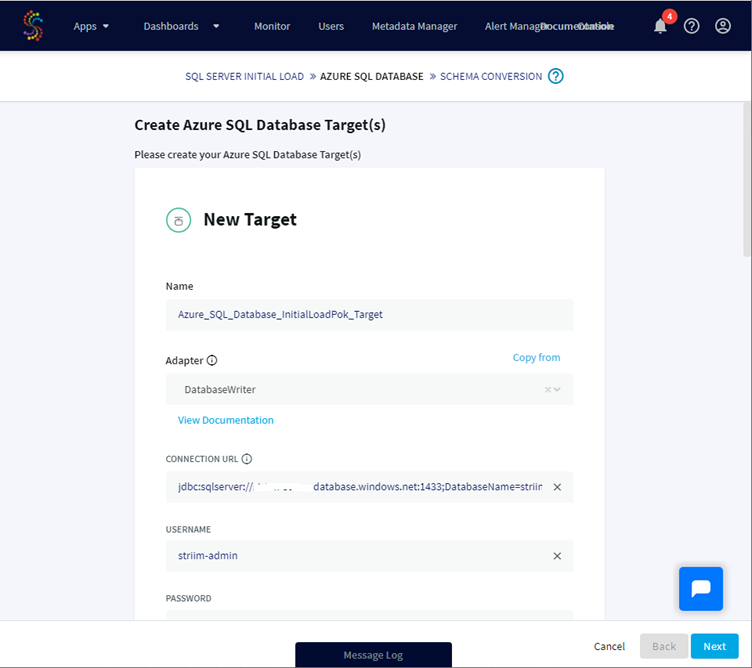
Now that the source is configured, we will enter the required information for our Target database, here an Azure SQL Database.
The connection URL must have this format jdbc:sqlserver://targetservername:1433;DatabaseName=dbname.
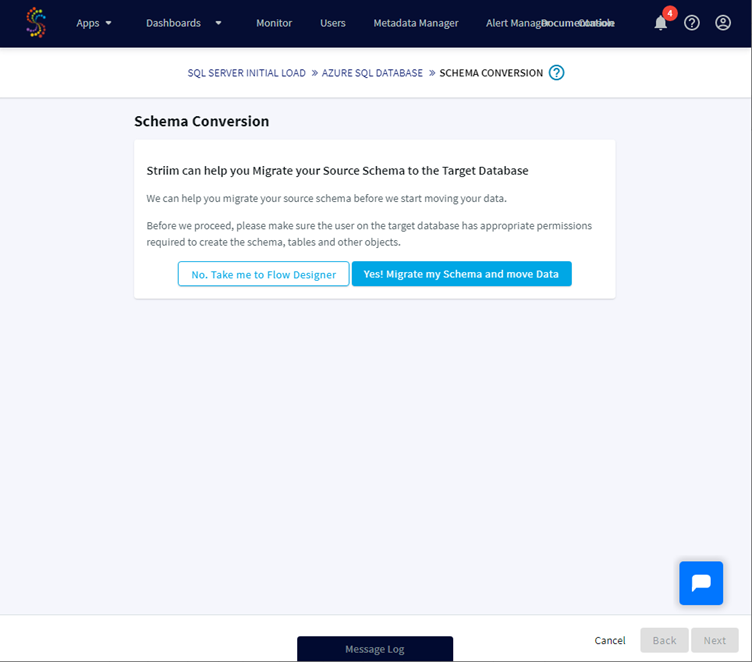
Striim can help us to migrate the source schema to the target database and also to move the data. Let’s agree with that and continue this process:
Striim is now validating information for the target connection.
if the connection is possible the schema(s) will be created on the target, the Striim application deployed and the data copied from the source to the target:
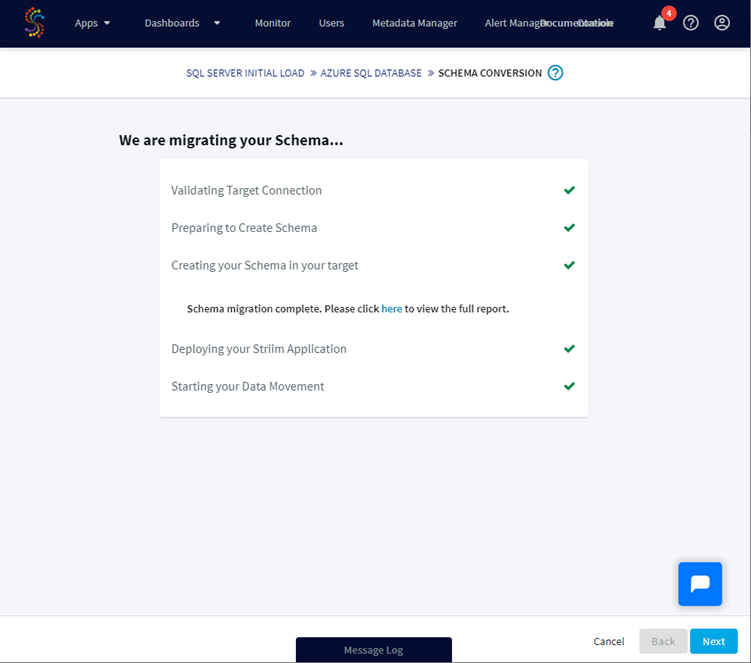
Clicking the Next button will give a resume of the application progress with information like the number of transferred rows, the rate…
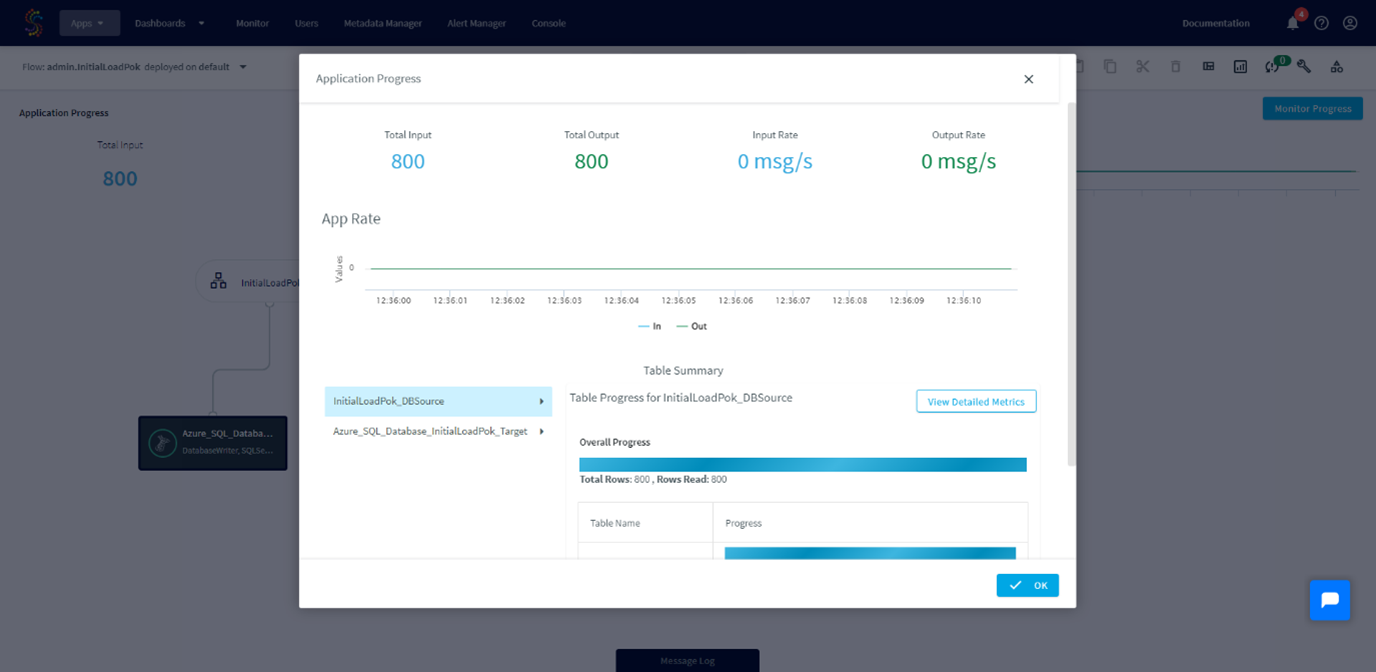
Execution of the application is now completed.
We can view the source, the target and the stream we have just created.
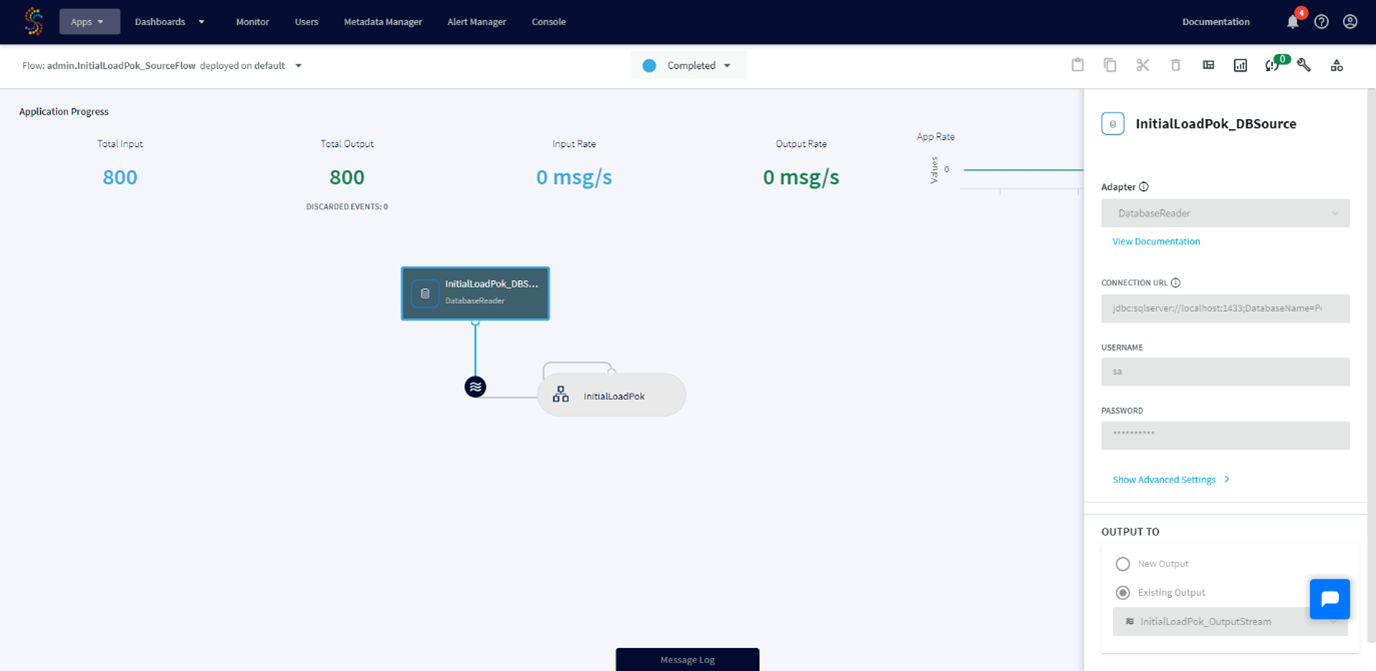
To be able to modify our application we have to undeploy it:
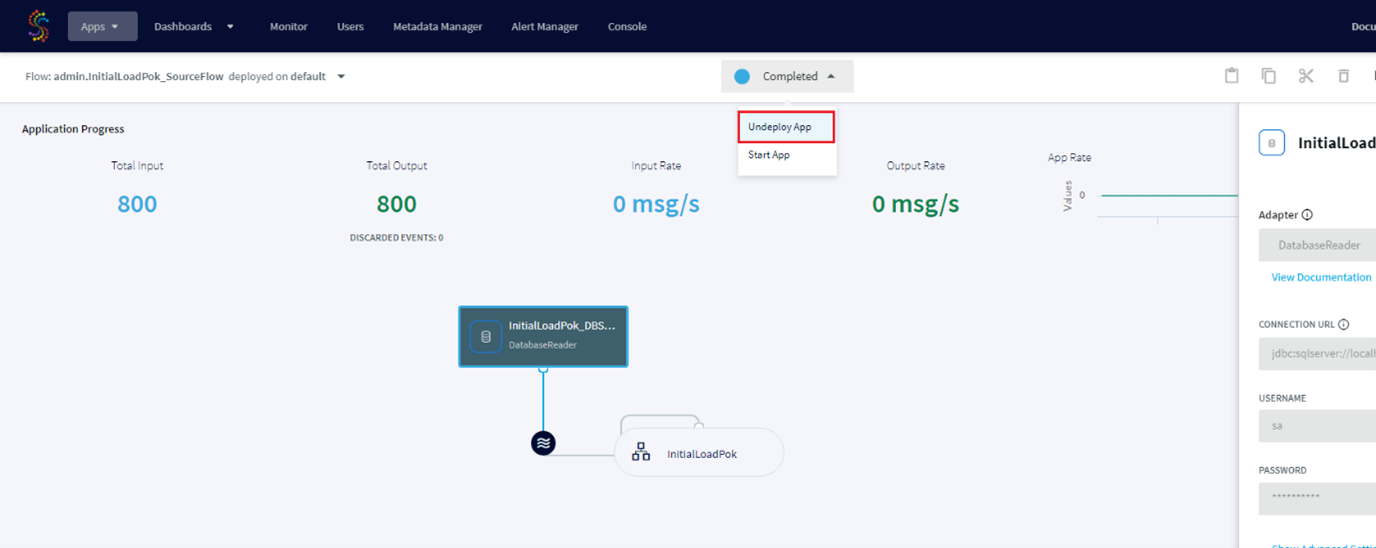
After modification if we want to rerun the application we have to Deploy it again.
When we come back to the application dashboard, we can see a new application named InitialLoadPok_schemaMigration.
This application has been created automatically to manage the schema creation executed during the Schema Conversion step.
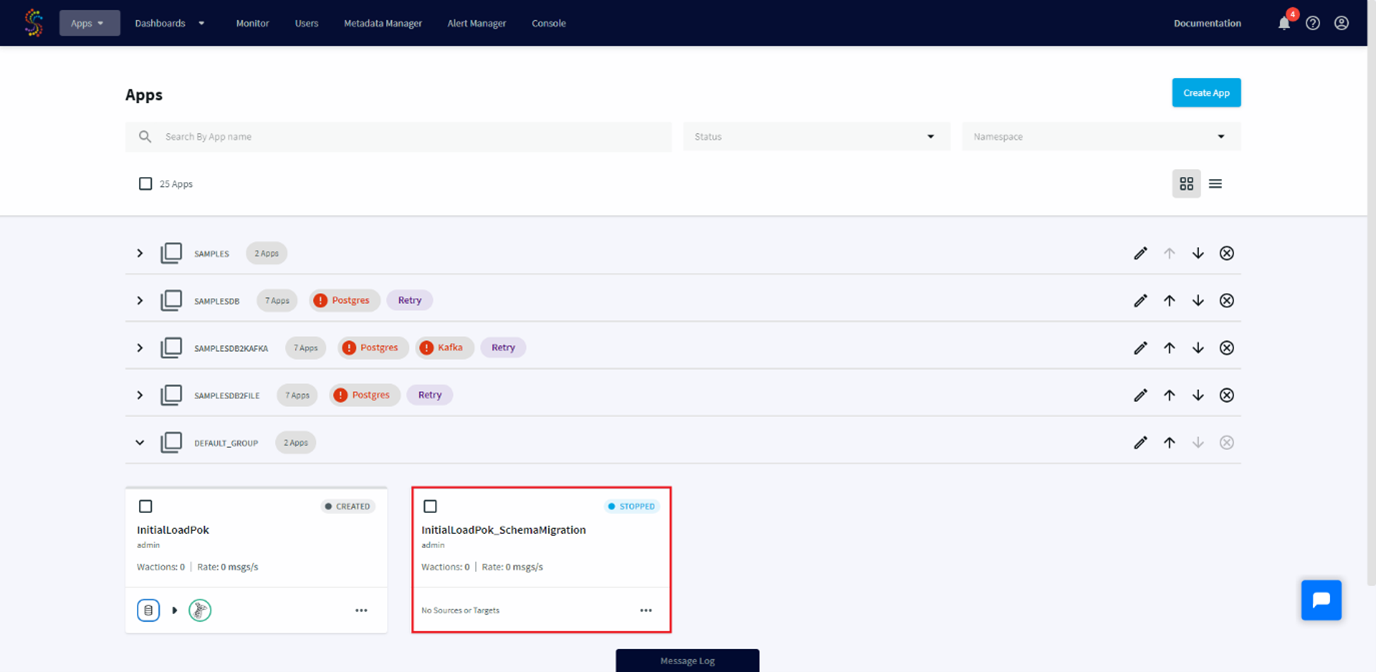
If we have some schemas changes between two Initial Load, we can drop tables on the targets and rerun this application which will recreate those tables with their new schemas.
The initial load is now configured, our process is ready to be executed when the situation will require it. The next step will be to create a Streaming Integration with CDC from our SQL Server on premise to our Azure SQL Database to execute real time DML on our target.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/STS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)