By Franck Pachot
.
There are good reasons for NoSQL and semi-structured databases. And there are also many mistakes and myths. If people move from RDBMS to NoSQL because of wrong reasons, they will have a bad experience and this finally deserves NoSQL reputation. Those myths were settled by some database newbies who didn’t learn SQL and relational databases. And, rather than learning the basics of data modeling, and capabilities of SQL for data sets processing, they thought they had invented the next generation of persistence… when they actually came back to what was there before the invention of RDBMS: a hierarchical semi-structured data model. And now encountering the same problem that the relational database solved 40 years ago. This blog post is about one of those myths.
Myth: adding a column has to scan and update the whole table
I have read and heard that too many times. Ideas like: RDBMS and SQL are not agile to follow with the evolution of the data domain. Or: NoSQL data stores, because they are loose on the data structure, makes it easier to add new attributes. The wrong, but unfortunately common, idea is that adding a new column to a SQL table is an expensive operation because all rows must be updated. Here are some examples (just taking random examples to show how this idea is widely spread even with smart experts and good reputation forums):
A comment on twitter: “add KVs to JSON is so dramatically easier than altering an RDBMS table, especially a large one, to add a new column”
Right, but what they are more referring to is being able to add KVs to JSON is so dramatically easier than altering an RDBMS table, especially a large one, to add a new column. If you choose to create a new one and move the data over that sucks in a different way.
— Kirk Kirkconnell (@NoSQLKnowHow) April 23, 2020
A question on StackOverflow: “Is ‘column-adding’ (schema modification) a key advantage of a NoSQL (mongodb) database over a RDBMS like MySQL” https://stackoverflow.com/questions/17117294/is-column-adding-schema-modification-a-key-advantage-of-a-nosql-mongodb-da/17118853. They are talking about months for this operation!
An article on Medium: “A migration which would add a new column in RDBMS doesn’t require this Scan and Update style migration for DynamoDB” https://medium.com/serverless-transformation/how-to-remain-agile-with-dynamodb-eca44ff9817.
Those are just examples. People hear it. People repeat it. People believe it. And they don’t test. And they don’t learn. They do not crosscheck with documentation. They do not test with their current database. When it is so easy to do.
Adding a column in SQL
Actually, adding a column is a fast operation in the major modern relational databases. I’ll create a table. Check the size. Then add a nullable column without default. Check the size. Then add a column with a default value. Check the size again. Size staying the same means no rows updated. Of course, you can test further: look at the elapsed time on a large table, and the amount of reads, and the redo/WAL generated,… You will see nothing in the major current RDBMS. Then you actually update all rows and compare. There you will see the size, the time, the reads, and the writes and understand that, with an explicit update the rows are actually updated. But not with the DDL to add a column.
PostgreSQL
Here is the example in PostgreSQL 12 in dbfiddle:
https://dbfiddle.uk/?rdbms=postgres_12&fiddle=9acf5fcc62f0ff1edd0c41aafae91b05
Another example where I show the WAL size:
And @postgresql is also very smart about adding columns: does not touch the tuples. size doesn't change even when adding a value to existing tuples: pic.twitter.com/FT2H7KuLIp
— Franck Pachot (@FranckPachot) April 23, 2020
Oracle Database
Here is the example in Oracle Database 18c in dbfiddle:
https://dbfiddle.uk/?rdbms=oracle_18&fiddle=b3a2d41636daeca5f8e9ea1d771bbd23
Another example:
When was your Oracle experience?
It has always (at least since Oracle7, 24 years ago) been immediate to add a nullable column. Same with not null columns (with default) since 12c (7 years ago): pic.twitter.com/pmoPFX9Q7o— Franck Pachot (@FranckPachot) April 23, 2020
Yes, I even tested in Oracle7 where, at that time, adding a not null column with a default value actually scanned the table. The workaround is easy with a view. Adding a nullable column (which is what you do in NoSQL) was already a fast operation, and that’s 40 years ago!
MySQL
Here is the example in MySQL 8 in dbfiddle:
https://dbfiddle.uk/?rdbms=mysql_8.0&fiddle=8c14e107e1f335b505565a0bde85f6ec
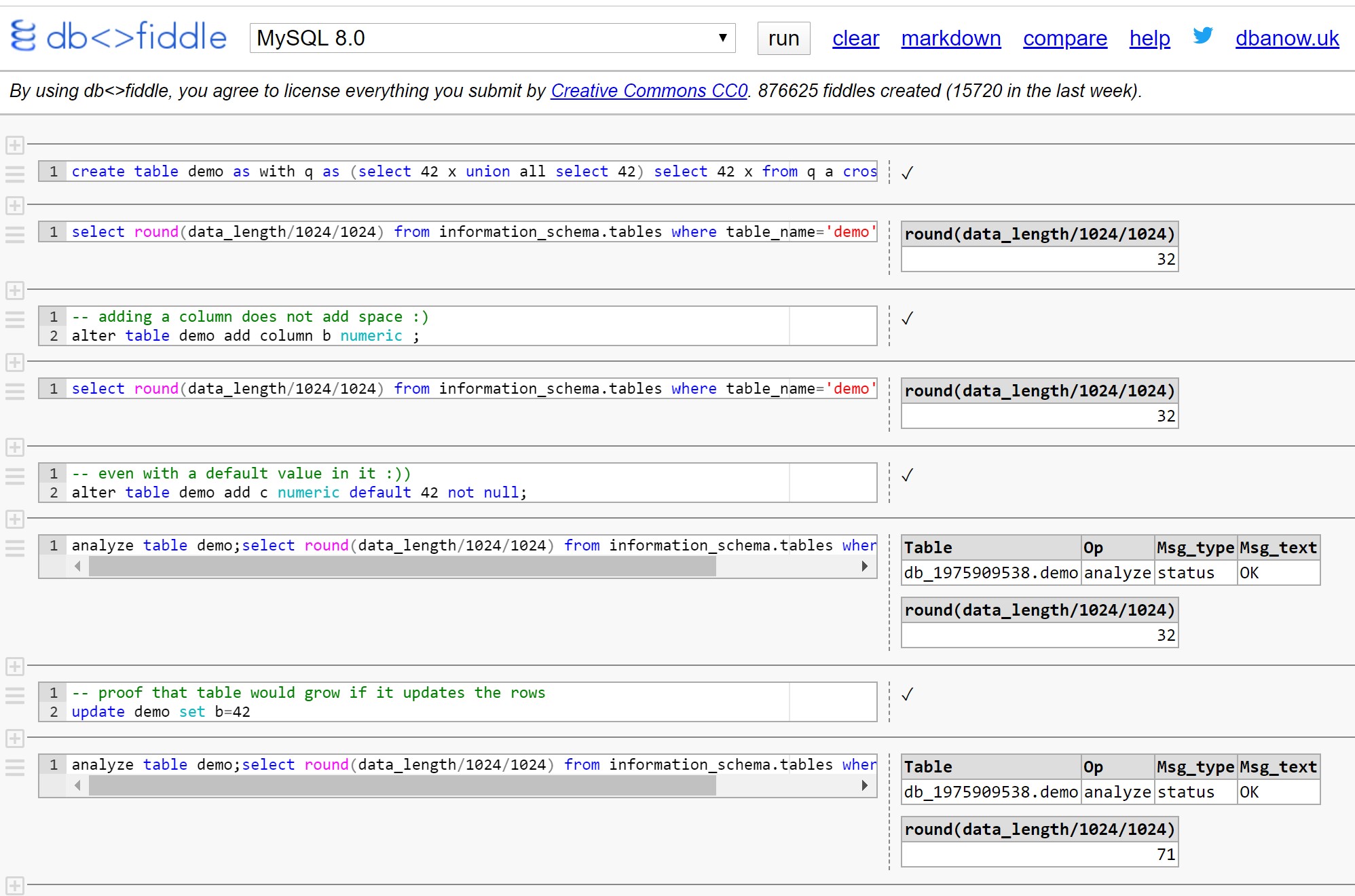
Microsoft SQL Server
It seems that the table I use is too large for dbfiddle but I’ve run the same on my laptop:
1> set statistics time on;
2> go
1> create table demo (x numeric);
2> go
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 2 ms, elapsed time = 2 ms.
1> with q as (select 42 x union all select 42)
2> insert into demo
3> s join q j cross join q k cross join q l cross join q m cross join q n cross join q o cross join q p cross join q r cross join q s cross join q t cross join q u;
4> go
SQL Server parse and compile time:
CPU time = 11 ms, elapsed time = 12 ms.
SQL Server Execution Times:
CPU time = 2374 ms, elapsed time = 2148 ms.
(1048576 rows affected)
1> alter table demo add b numeric ;
2> go
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 3 ms.
1> alter table demo add c numeric default 42 not null;
2> go
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 1 ms, elapsed time = 2 ms.
2> go
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
x b c
-------------------- -------------------- --------------------
42 NULL 42
42 NULL 42
42 NULL 42
(3 rows affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
3> go
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 3768 ms, elapsed time = 3826 ms.
(1048576 rows affected)
2 milliseconds for adding a column with a value, visible on all those million rows (and it can be more).
YugaByte DB
In a distributed database, metadata must be updated in all nodes, but this is still in milliseconds whatever the table size is:
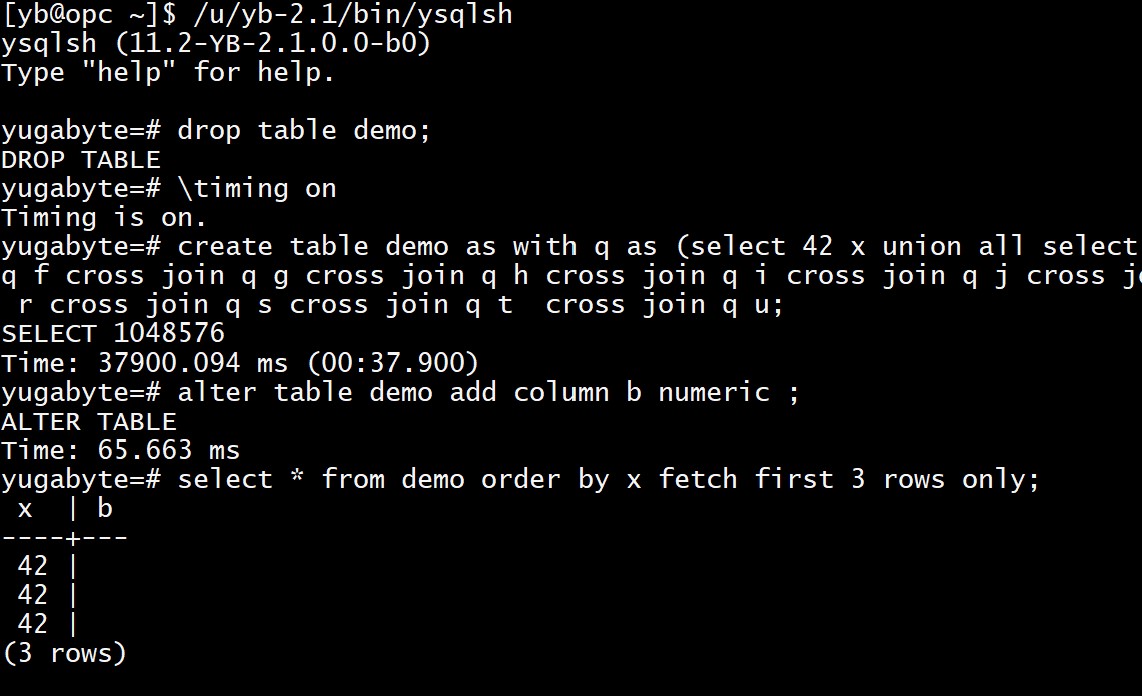
I didn’t show the test with not null and default value as I encountered an issue (adding column is fast but default value not selected). I don’t have the latest version (YugaByte DB is open source and in very active development) and this is probably an issue going to be fixed.
Tibero
Tibero is a database with very high compatibility with Oracle. I’ve run the same SQL. But this version 6 seems to be compatible with Oracle 11 where adding a non null column with default had to update all rows:
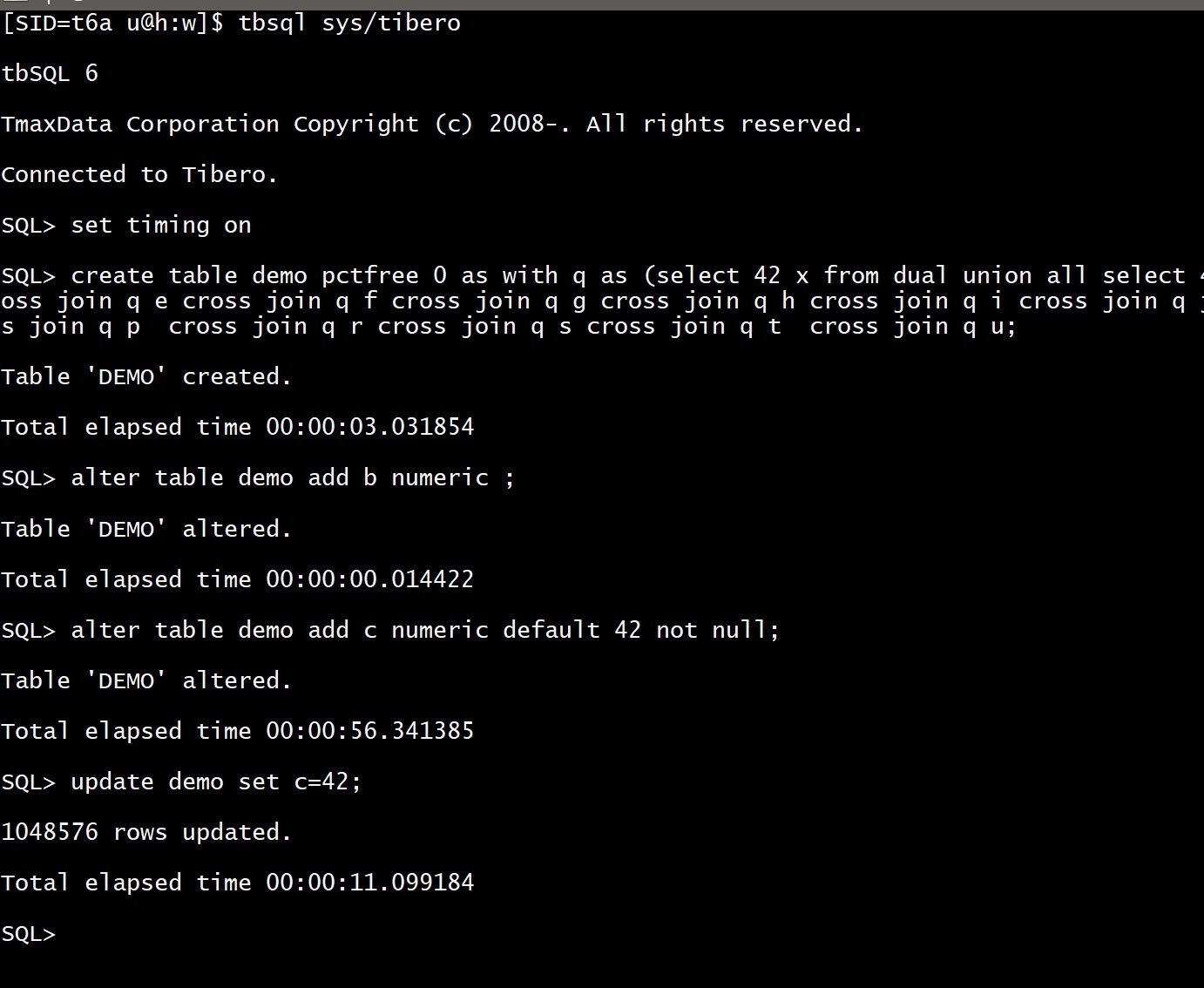
You can test on any other databases with a code similar to this one:
-- CTAS CTE Cross Join is the most cross-RDBMS I've found to create one million rows
create table demo as with q as (select 42 x union all select 42) select 42 x from q a cross join q b cross join q c cross join q d cross join q e cross join q f cross join q g cross join q h cross join q i cross join q j cross join q k cross join q l cross join q m cross join q n cross join q o cross join q p cross join q r cross join q s cross join q t cross join q u;
-- check the time to add a column
alter table demo add b numeric ;
-- check the time for a column with a value set for all existing rows
alter table demo add c numeric default 42 not null;
-- check that all rows show this value
select * from demo order by x fetch first 3 rows only;
-- compare with the time to really update all rows
update demo set c=42;
and please don’t hesitate to comment this blog post or the following tweet with you results:
If I hear one more time that NoSQL semi-structured data stores are more agile than RDBMS I write a blog post about SQL add column and Codd rule #9.
— Franck Pachot (@FranckPachot) May 7, 2020
NoSQL semi-structured
The myth comes from old versions of some databases that did no implement the ALTER TABLE .. ADD in an optimal way. And the NoSQL inventors probably knew only MySQL which was late in this area. Who said that MySQL evolution suffered from its acquisition by Oracle? They reduce the gap with other databases, like with this column adding optimisation.
If you stay with this outdated knowledge, you may think that NoSQL with semi-structured collections is more Agile, right? Yes, of course, you can add a new attribute when inserting a new item. It has zero cost and you don’t have to declare it to anyone. But what about the second case I tested in all those SQL databases, where you want to define a value for the existing rows as well? As we have seen, SQL allows that with a DEFAULT clause. In NoSQL you have to scan and update all items. Or you need to implement some logic in the application, like “if null then value”. That is not agile at all: as a side effect of a new feature, you need to change all data or all code.
Relational databases encapsulate the physical storage with a logical view. And in addition to that this logical view protects the existing application code when it evolves. This E.F Codd rule number 9: Logical Data Independence. You can deliver declarative changes to your structures without modifying any procedural code or stored data. Now, who is agile?
Structured data have metadata: performance and agility
How does it work? The RDBMS dictionary holds information about the structure of the rows, and this goes beyond a simple column name and datatype. The default value is defined here, which is why the ADD column was immediate. This is just an update of metadata. It doesn’t touch any existing data: performance. It exposes a virtual view to the application: agility. With Oracle, you can even version those views and deliver them to the application without interruption. This is called Edition Based Redefinition.
There are other smart things in the RDBMS dictionary. For example, when I add a column with the NOT NULL attribute, this assertion is guaranteed. I don’t need any code to check whether the value is set or not. Same with constraints: one declaration in a central dictionary makes all code safe and simpler because the assertion is guaranteed without additional testing. No need to check for data quality as it is enforced by design. Without it, how many sanity assumptions do you need to add in your code to ensure that erroneous data will not corrupt everything around? We have seen adding a column, but think about something even simple. Naming things is the most important in IT. Allow yourself to realize you made a mistake, or some business concepts change, and modify the name of a column for a more meaningful one. That can be done easily, even with a view to keep compatibility with previous code. Changing an attribute name in a large collection of JSON items is not so easy.
Relational databases have been invented for agility
Let me quote the reason why CERN decided to use Oracle in 1982 for the LEP – the ancestor of the LHC: Oracle The Database Management System For LEP: “Relational systems transform complex data structures into simple two-dimensional tables which are easy to visualize. These systems are intended for applications where preplanning is difficult…”
Preplanning not needed… isn’t that the definition of Agility in the 20th century words?
Another good read to clear some myth: Relational Database: A Practical Foundation for Productivity by E.F. Codd Some problems that are solved by relational databases are the lack of distinction between “the programmer’s (logical) view of the data and the (physical) representation of data in storage”, the “subsequent changes in data description” forcing code changes, and “programmers were forced to think and code in terms of iterative loops” because of the lack of set processing. Who says that SQL and joins are slow? Are your iterative loops smarter than hash joins, nested loops and sort merge joins?
Never say No
I’m not saying that NoSQL is good or bad or better or worse. It is bad only when the decision is based on myths rather than facts. If you want agility on your data domain structures, stay relational. If you want to allow any future query pattern, stay relational. However, there are also some use cases that can fit in a relational database but may also benefit from another engine with optimal performance in key-value lookups. I have seen tables full of session state with a PRIMARY KEY (user or session ID) and a RAW column containing some data meaningful only for one application module (login service) and without durable purpose. They are acceptable in a SQL table if you take care of the physical model (you don’t want to cluster those rows in a context with many concurrent logins). But a Key-Value may be more suitable. We still see Oracle tables with LONG datatypes. If you like that you probably need a key-value NoSQL. Databases can store documents, but that’s luxury. They benefit from consistent backups and HA but at the prize of operating a very large and growing database. Timeseries, or graphs, are not easy to store in relational tables. NoSQL databases like AWS DynamoDB are very efficient for those specific use cases. But this is when all access patterns are known from design. If you know your data structure and cannot anticipate all queries, then relational databases systems (which means more than a simple data store) and SQL (the 4th generation declarative language to manipulate data by sets) are still the best choices for agility.
Still in the NoSQL vs. RDBMS myths, here is a post about “joins don’t scale”: https://www.dbi-services.com/blog/the-myth-of-nosql-vs-rdbms-joins-dont-scale/ and still in the “Agility” of RDBMS an example where adding an index can scale a new use-case without any code change: https://www.dbi-services.com/blog/19c-scalable-top-n-queries/
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/05/open-source-author.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)