In the last posts (1, 2, 3, 4, 5) I looked at PostgreSQL in Amazon RDS. Another option you have if you want to go to the cloud is to use the The Postgres Plus® Cloud Database offered by EnterpriseDB.
I will not go through the whole setup here as this is described in detail here.
So once you went through the registration and setup process you should be able to login. The login URL is depending on the region you selected so this link will not work for you if you not selected a region in the EU (Ireland, in my case):
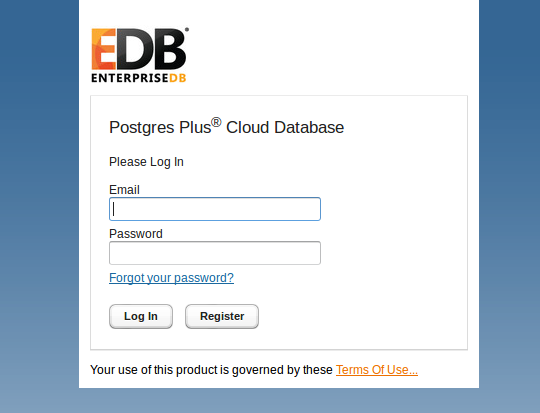
You’ll land at the EnterpriseDB console after a successful login:
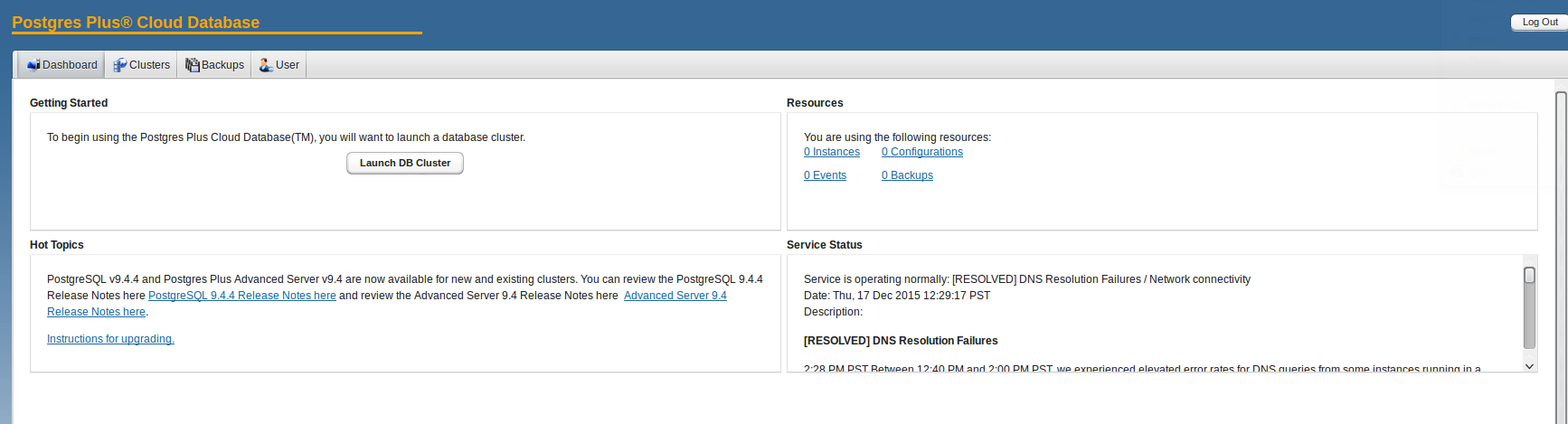
Obviously we want to bring up our first cluster, so lets go. You’ll have the choice between community PostgreSQL and Postgres Plus Advanced Server. The other values are more or less the same than those of the Amazon RDS service:
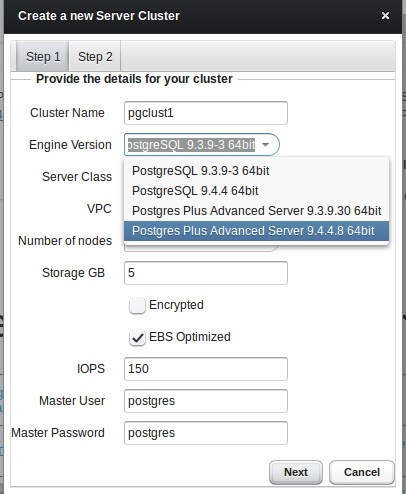
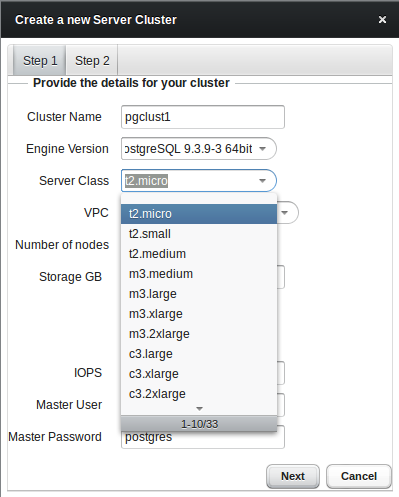
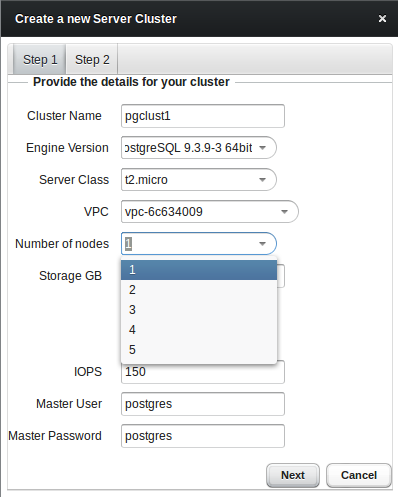
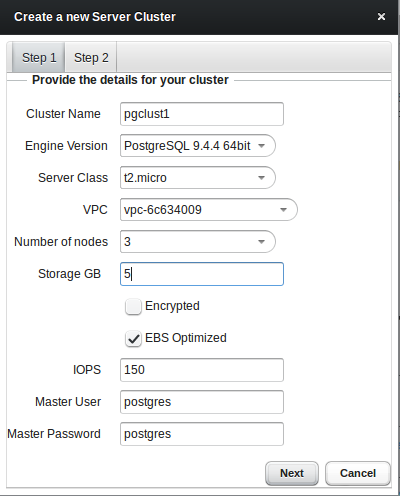
As soon as you choose continuous archiving a storage container for holding all the archived wal files will be created automatically:
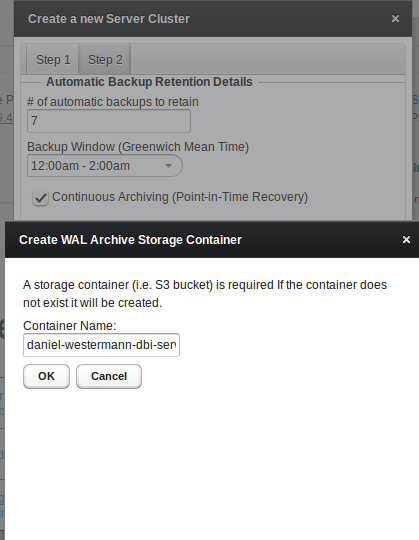
As soon as the creation of the storage finished an email should arrive in your inbox:
From: [email protected] To: "daniel westermann" Sent: Wednesday, January 13, 2016 2:16:18 PM Subject: WAL Archive Storage Container Created A storage container (bucket) named xxxxx-ppcd has been created. All Postgres Plus Cloud Database clusters configured for Continuous Archiving (Point-in-Time Recovery) will use this location to store archived WAL files. This container should not be deleted once created as it will cause WAL archiving to stop functioning.
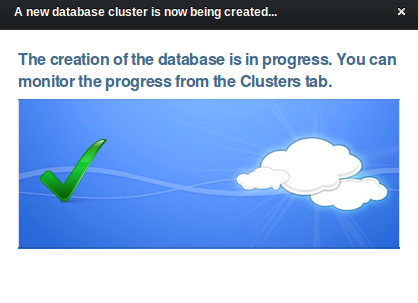
Waiting a few minutes for the process to complete and the new PostgreSQL cluster will be ready:


As with the storage container you’ll receive notification emails once an instance is ready:
From: [email protected] To: "daniel westermann" Sent: Wednesday, January 13, 2016 2:32:09 PM Subject: Database State Changed to RUNNING i-7ce1b6f1 t2.micro The Master database server ec2-52-18-219-36.eu-west-1.compute.amazonaws.com in cluster pgclust1 is now RUNNING in location eu-west-1a using port 1234.
From: [email protected] To: "daniel westermann" Sent: Wednesday, January 13, 2016 2:40:44 PM Subject: Database State Changed to RUNNING i-9e4c7d15 t2.micro The Replica database server ec2-52-48-111-239.eu-west-1.compute.amazonaws.com t2.micro in cluster pgclust1 is now RUNNING in location eu-west-1c.
Quite easy. A very good features is that a load balances will be added automatically which listens on port 9999:
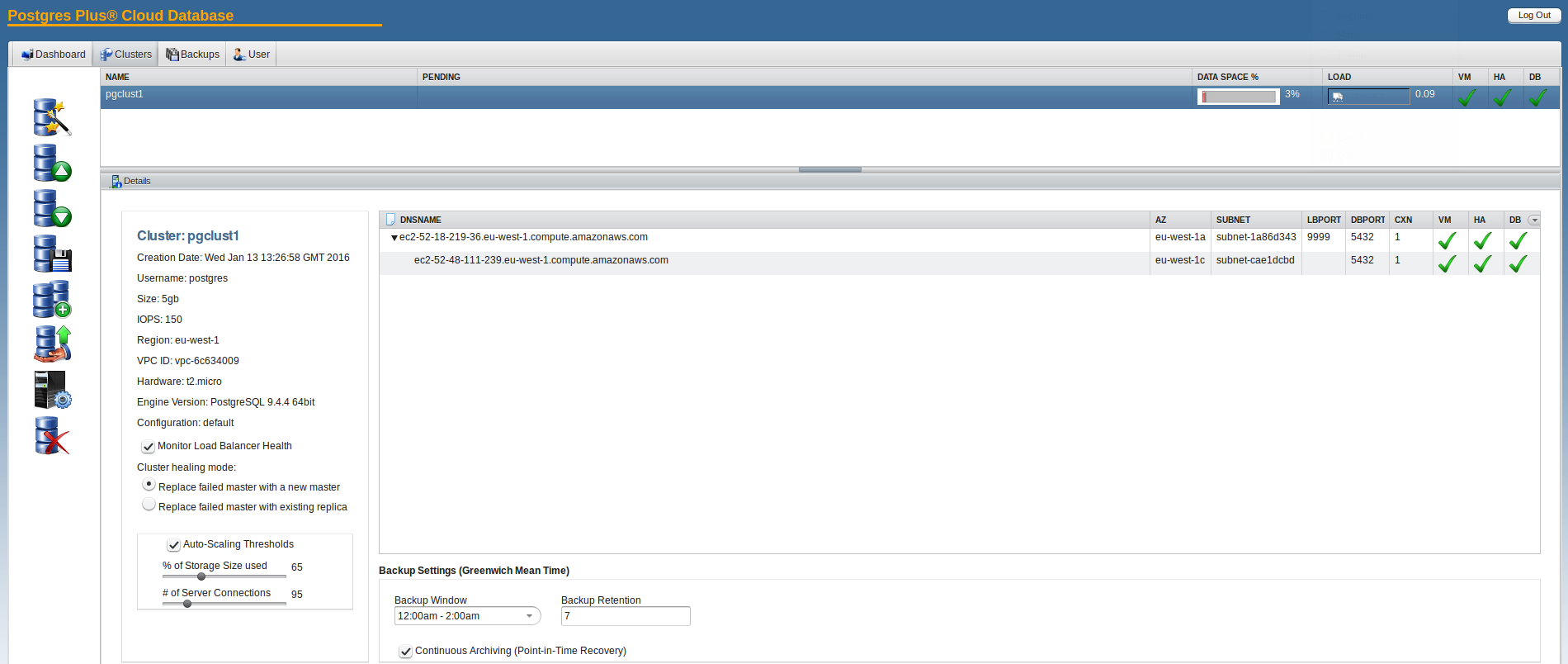
Lets see if we can connect to the load balancer:
dwe@dwe:~$ psql -h ec2-52-18-219-36.eu-west-1.compute.amazonaws.com -p 9999 -U postgres postgres
Password for user postgres:
psql (9.3.10, server 9.4.4)
WARNING: psql major version 9.3, server major version 9.4.
Some psql features might not work.
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+------------+------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 |
template0 | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=#
In contrast to the Amazon RDS service we have full control over the cluster as we are able to connect with the postgres superuser.
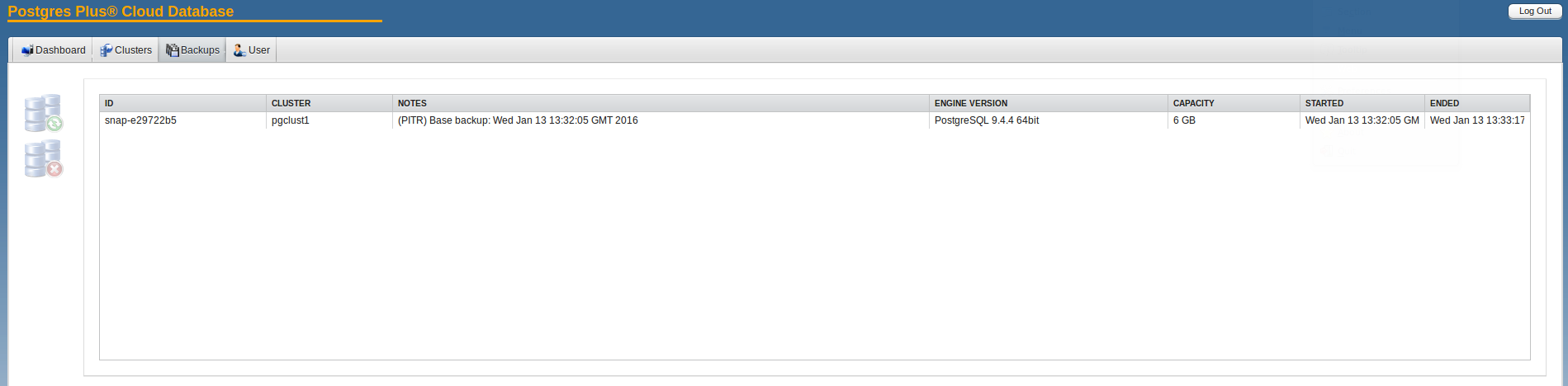
When the cluster was created an initial backup was created automatically:
Another interesting feature is auto scaling:
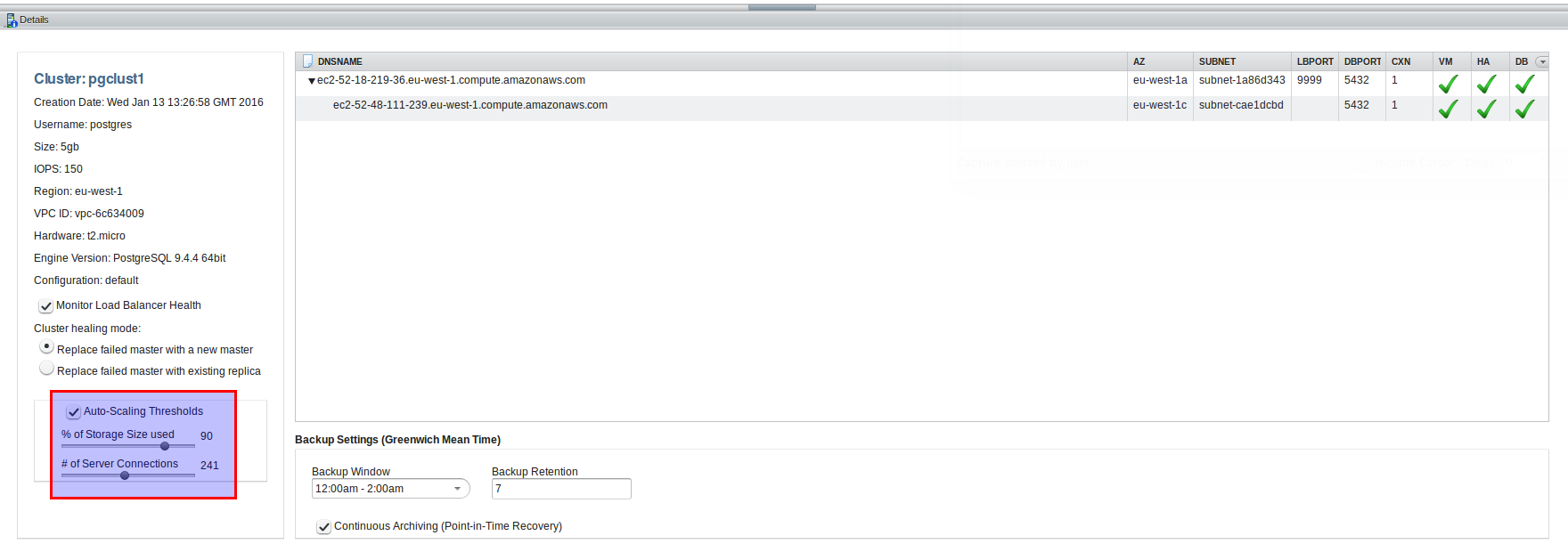
You have two options there: Auto scale the cluster when a specified threshold for storage usage is reached or auto scale the cluster when a specified threshold on concurrent connections is reached. But keep in mind that this will increase costs as well.
You even can choose what happens when there is a major issue on the master:
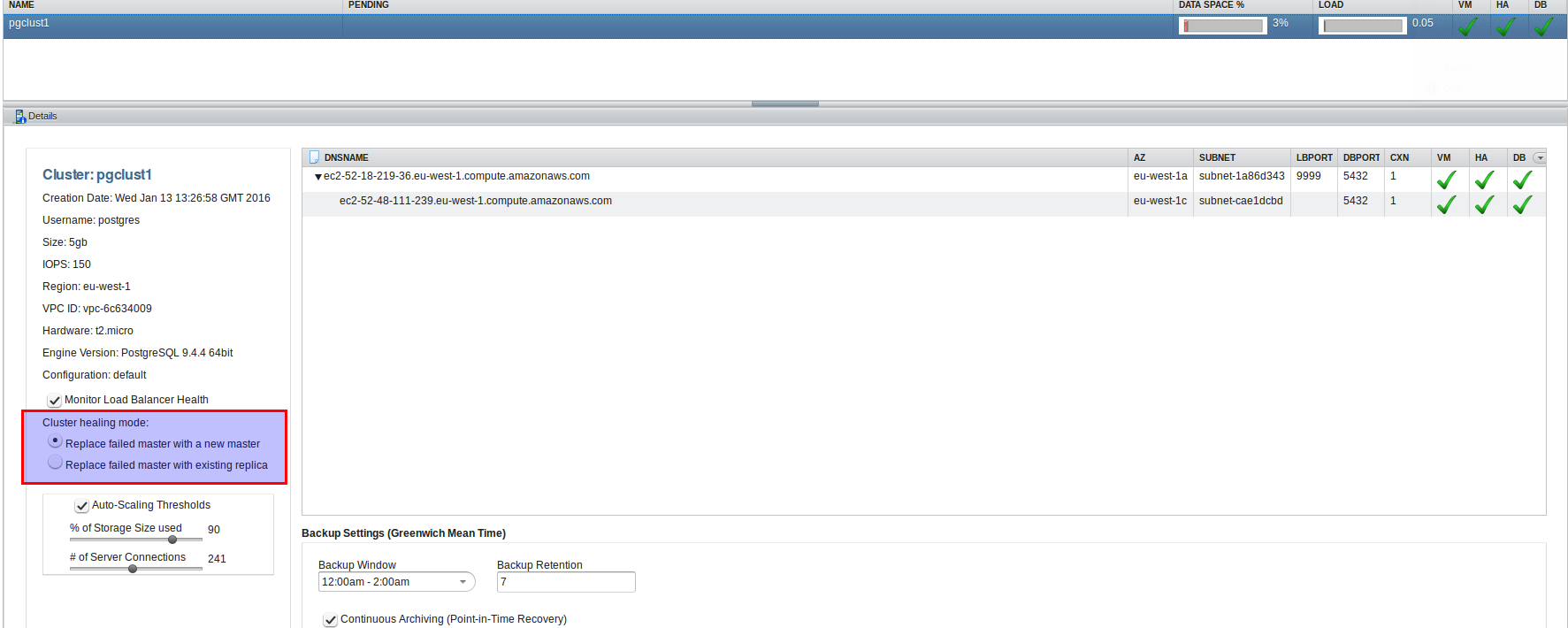
Do you want to replace the master with a new master or do you want to promote to a replica? Promoting to a replica is faster but you might loose transactions as replication in this case is asynchronous. In case the master is replaced with a new master the storage volumes are switch to the new master so no transaction will be lost but this will take longer than promoting a replica.
Configuring the instances is almost the same as in Amazon RDS. You’ll have to create a new configuration and then attach it to a running instance. Additionally you may configure pgpool, which is the load balancer from above:
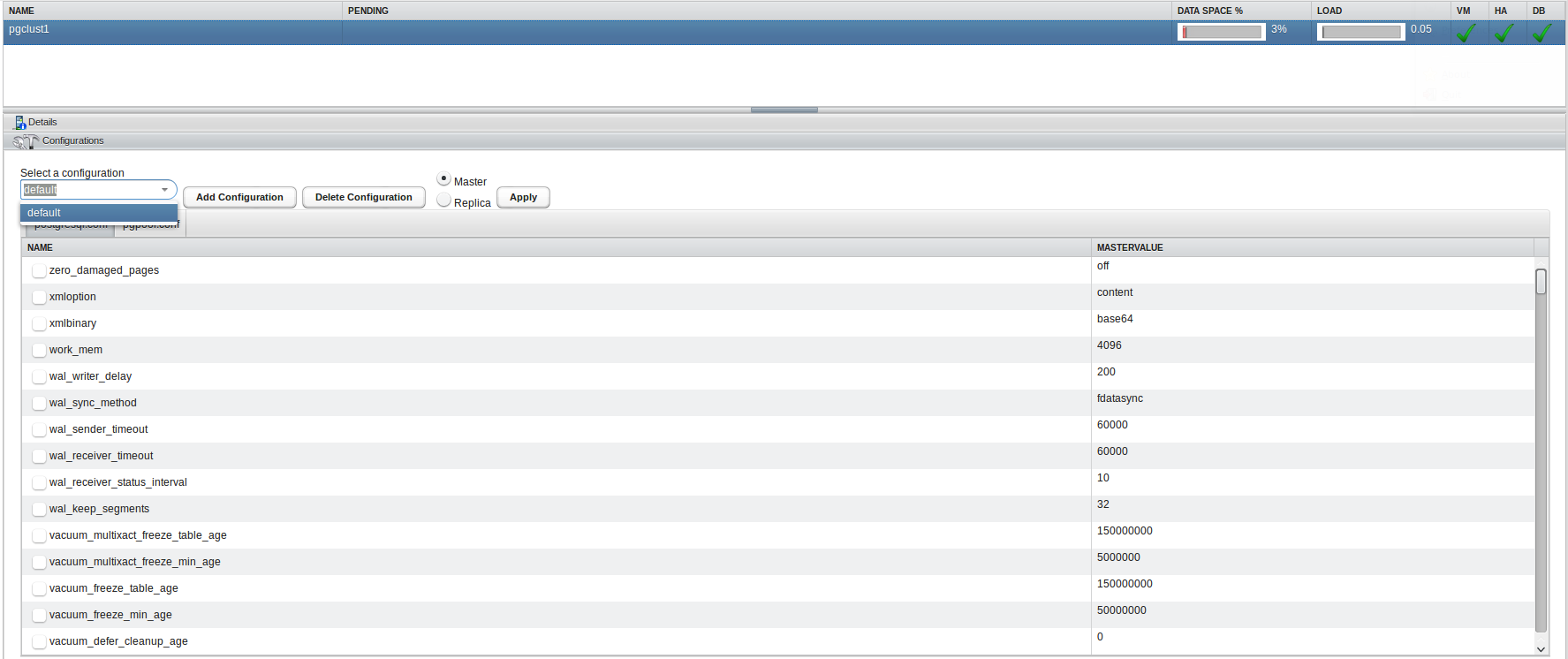
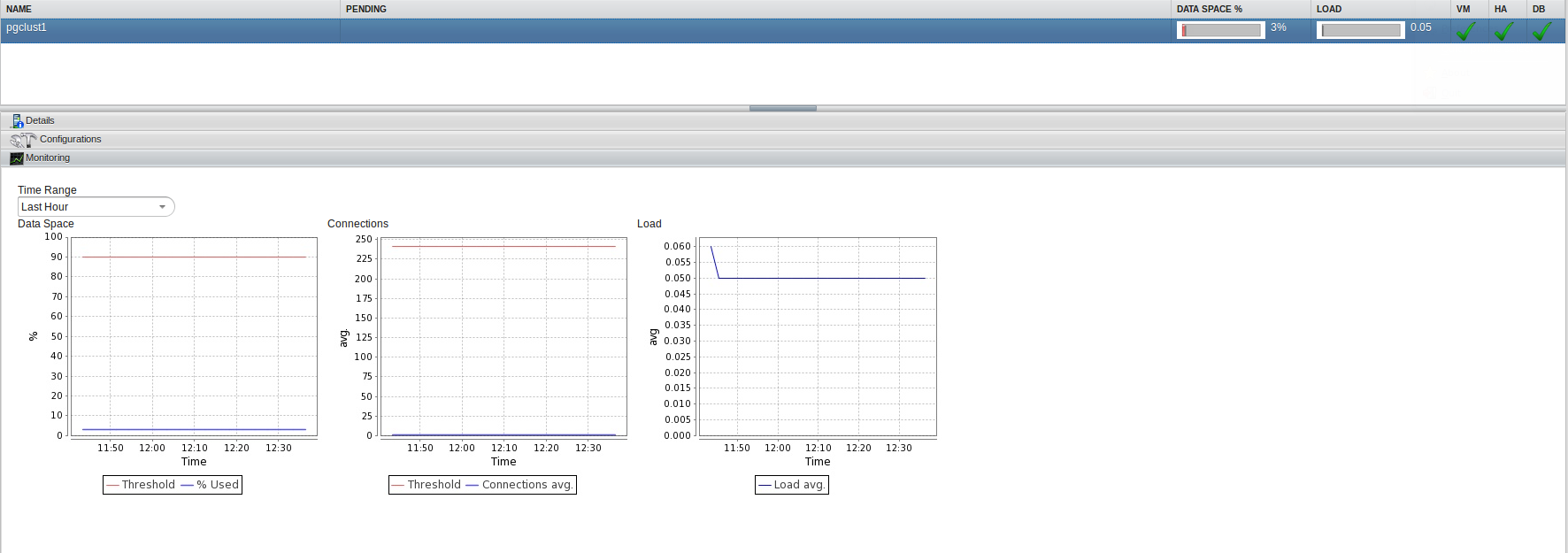
The monitoring part is slightly limited. You can take a look at the storage used, the amount of connections and the load. This help when defining the auto scaling options but does not replace a full monitoring solution:
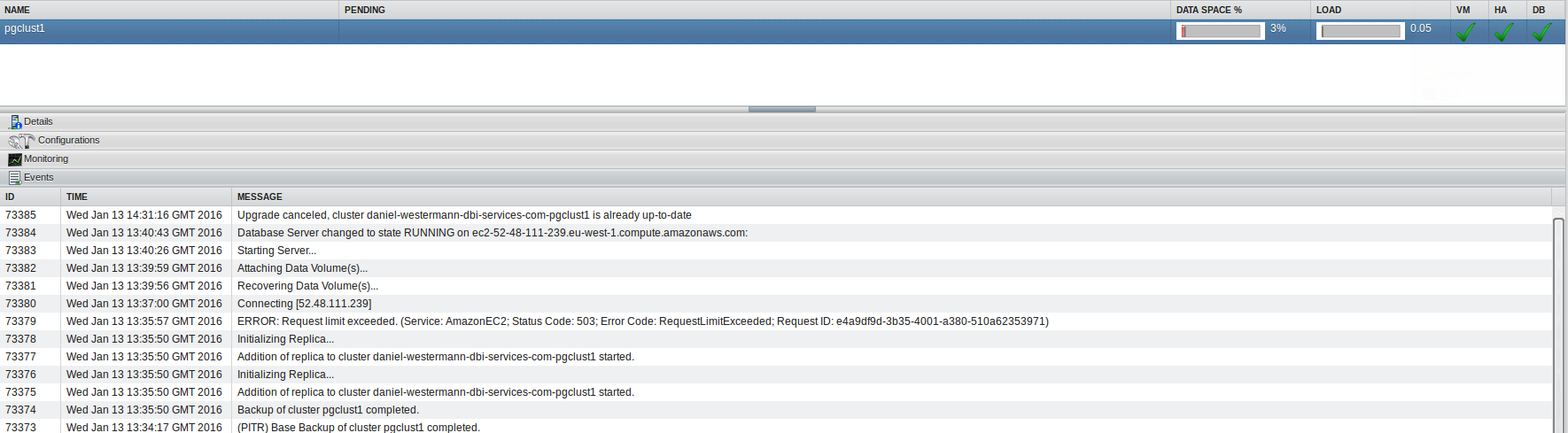
The events sections lists all events that happened to your cluster:
Let’s try to manually scale up our cluster by adding another replica:
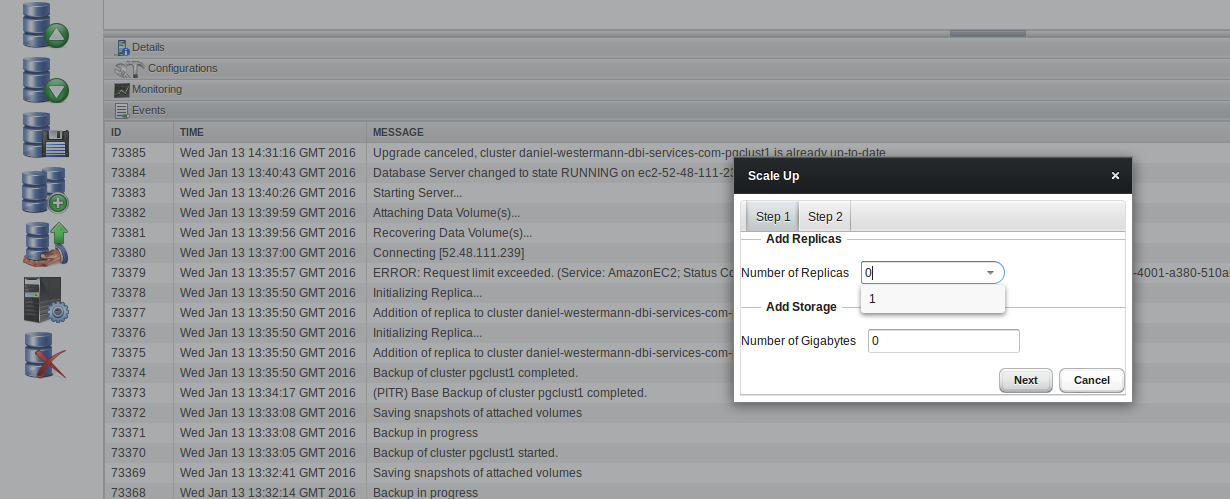
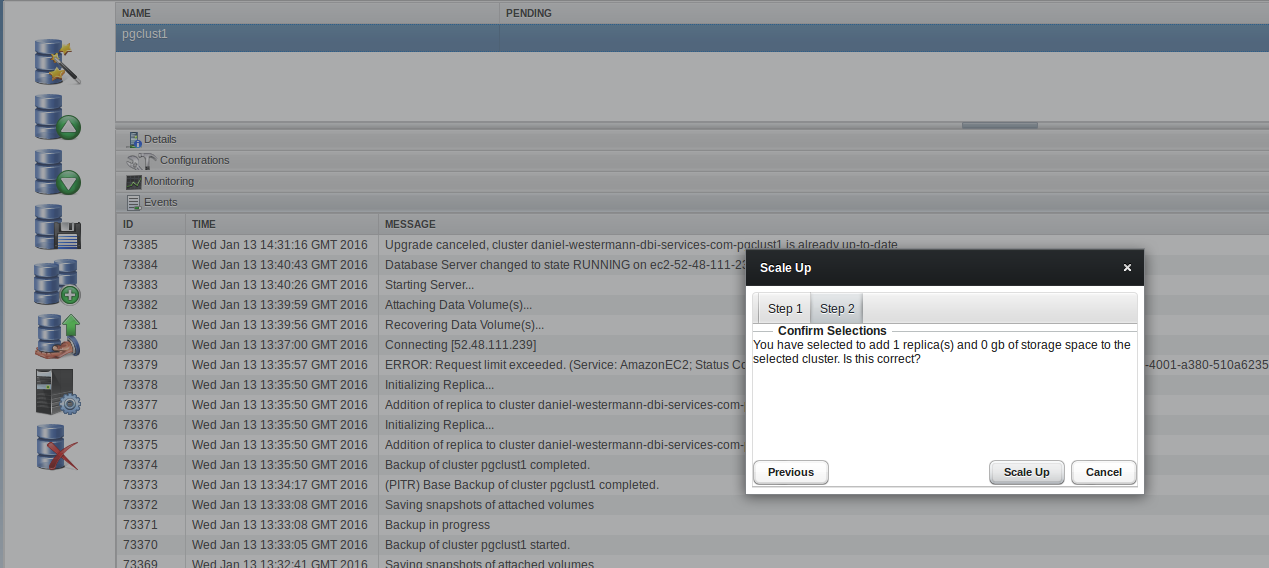
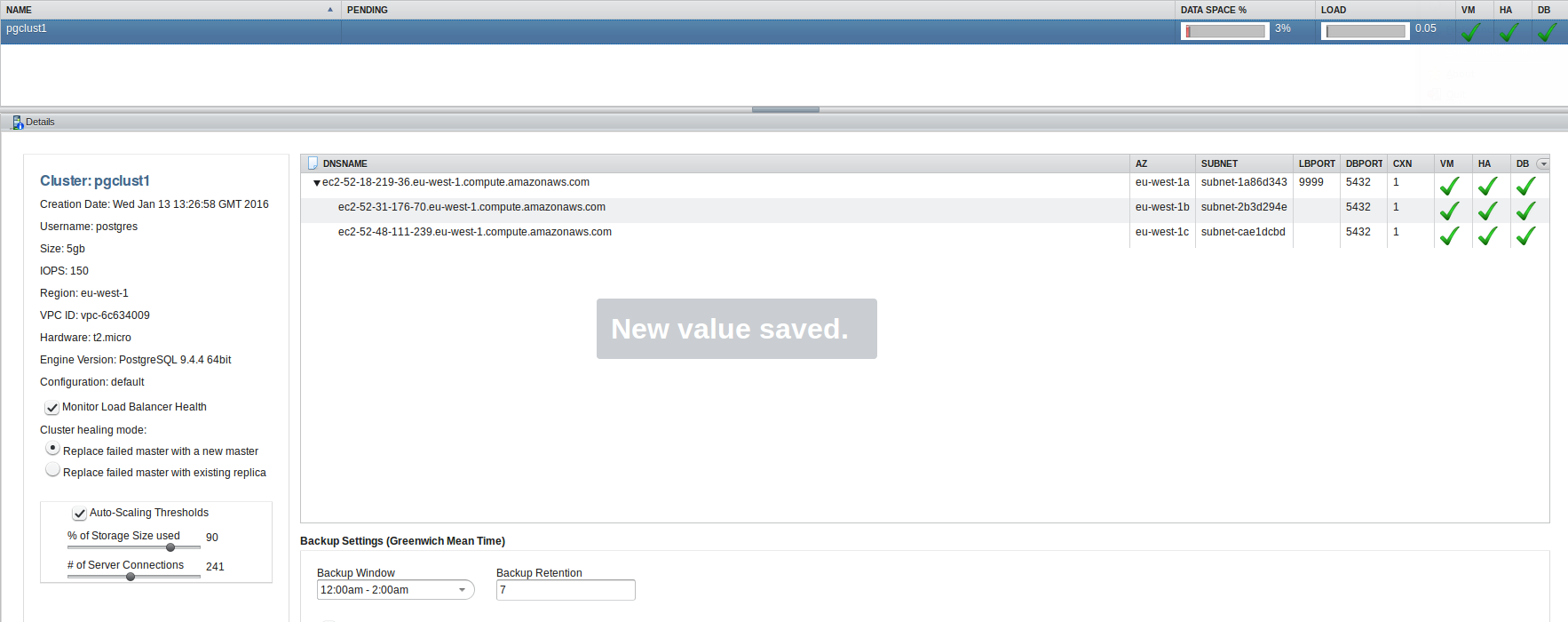
Quite easy as well. Now we have two replicas which replicate from the same master. So, in the end, this might be a solution to consider.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)