During my last blog post I explained how to installed a MABS. Now that your infrastructure is setup you will be able to protect the workload of your Hyper-V Virtual Machines.
You have first to create a new protection group. This group will contain one or more VMs which will share the same backup configuration for retention, synchronization and recovery.
Protection is managed as follow:
- DPM create a copy of the selected data on the DPM server
- Those copies are synchronized with the data source and recovery point are created on a regular basis
- Double backup protection via DPM:
- disk based: data replicas are stored on disk and periodic full backups are created
- online protection: regular backups of the protected data are done to Azure Backup
Go to the protection tab and select New, once done select Servers as you want to backup file and application servers where you already installed DPM protection agent. Those servers should be online during this protection process to be able to select the resources you want to backup:
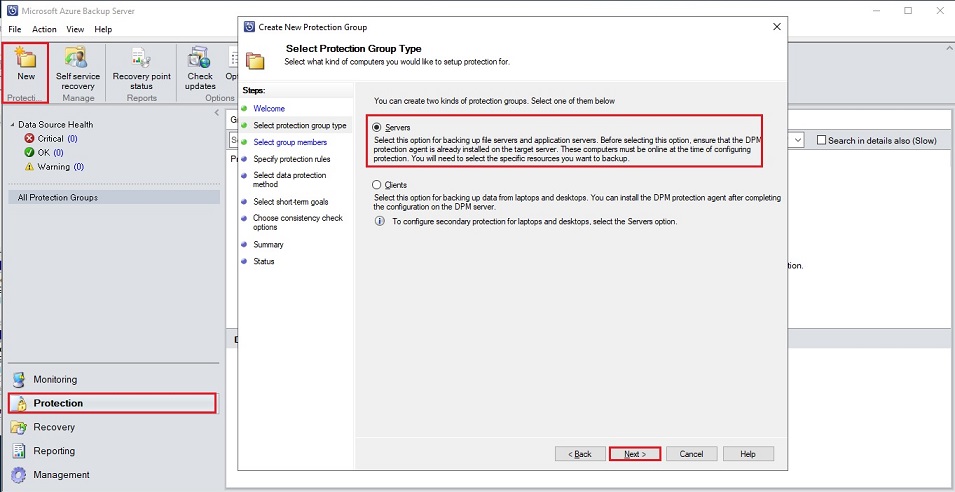
Here I will select for my two Virtual machines a BMR (Bare Metal Recovery) & a System State to have all the necessary files to recover my VM in case of failure. Also for my SQL Server instance thor1\vienne the workload for the AdventureWordsDW2014 database and on instance thor2\vienne the complete SQL Server instance:
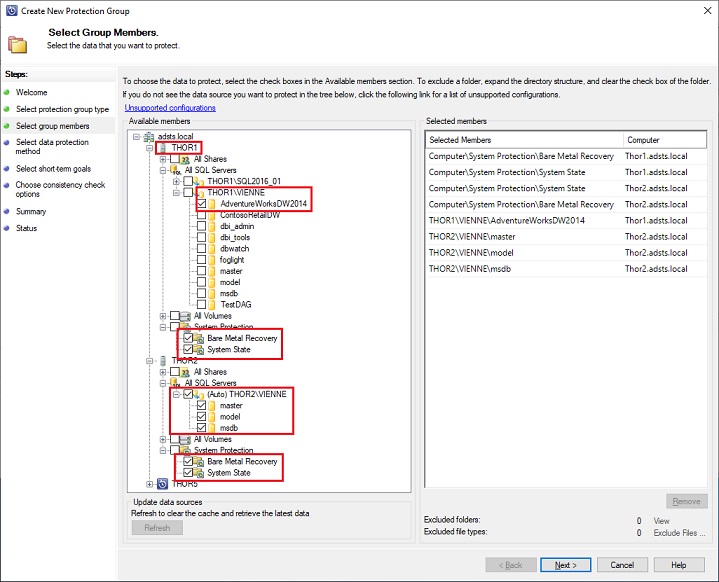
Next step is to give a name to your protection group and define the method to store your backup:
- locally with short term protection using disk (mandatory if you select also online protection)
- Online with Azure Backup
You can select both here to have your backups protected also on Azure:
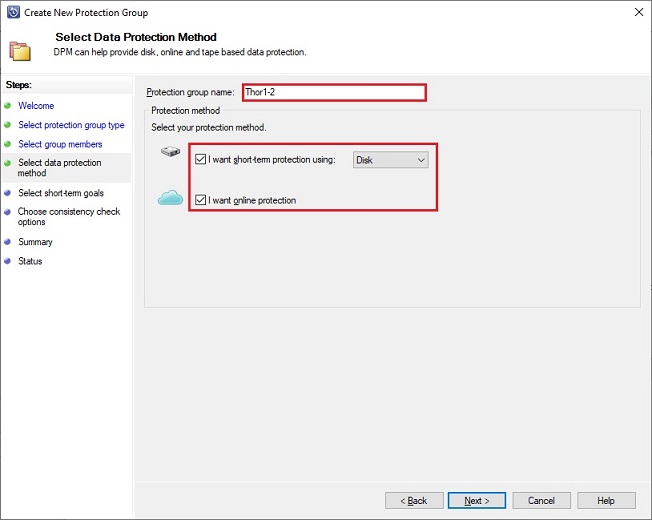
Once done a retention period has to be defined for disk-based backups with a synchronization frequency, here 3 retention days on disk and incremental every fifteen minutes. You can also schedule an express full backup for application like SQL Server, here every day at 8PM. It will provide a recovery point for applications, either based on incremental backups or on express full backup:
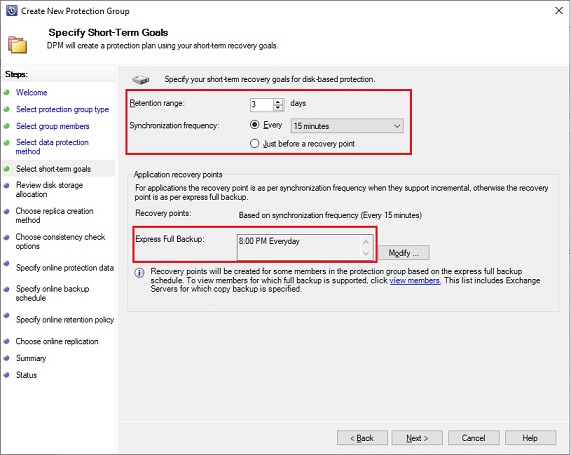
Based on your prior selections DMP gives an overview of the disk space needed for your protection and lists the available disks:
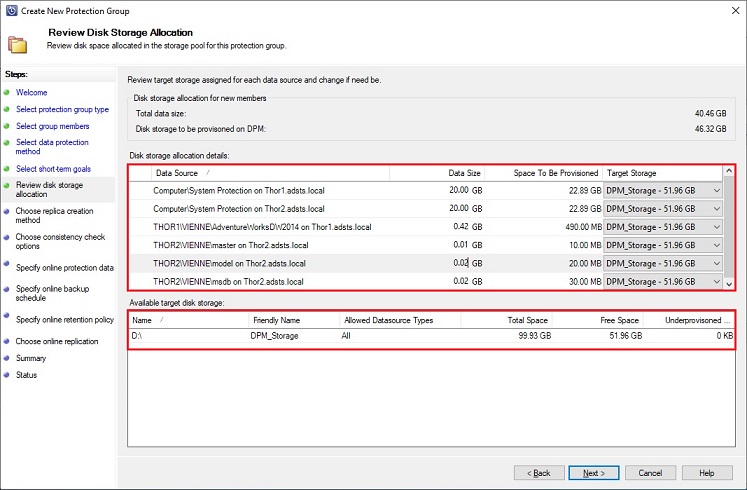
You need to select the replica creation method you want to use to create the initial copy of your protected data to the MABS. By default, it will be over the network. If you use this method take care to do it during off-peak hours. Otherwise select manually to perform this transfer using removable media:
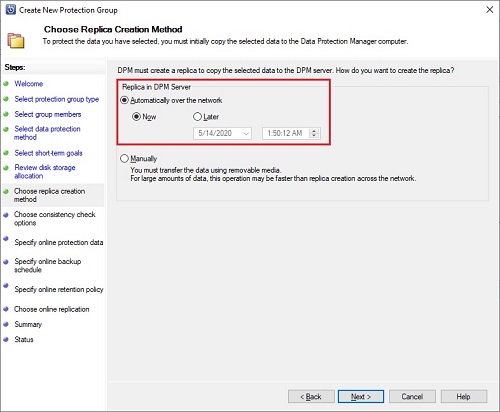
Select the way you want that DPM runs consistency check over replica copy. By default, it is done automatically but you can also schedule it. Same as before take care to do it during off-peak hours as it could require CPU and disk resources:
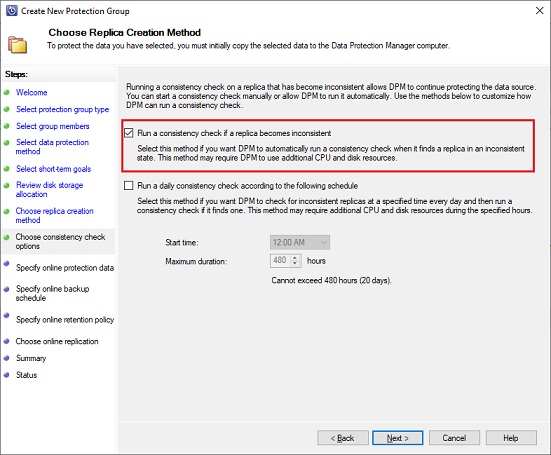
Once done you can select the data source which will be added to online protection within Azure, here I select all:
Next step is to specify how often incremental backups to Azure will occur. For each backup a recovery point is created in Azure from the copy of the backup data located on DPM disk.
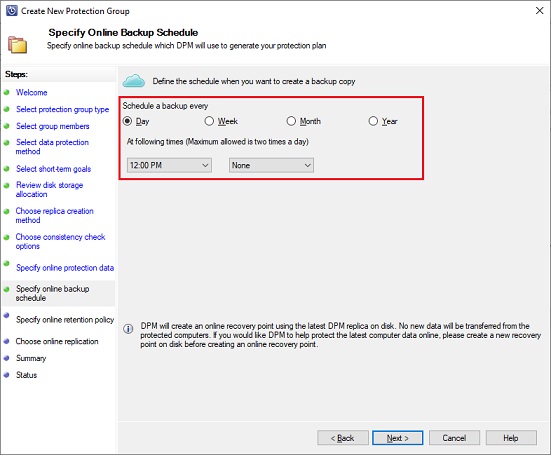
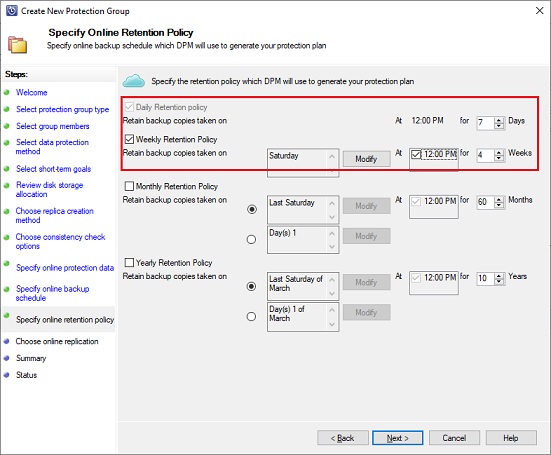
A retention policy must be defined. It will configure how much time backups must be retained in Azure:
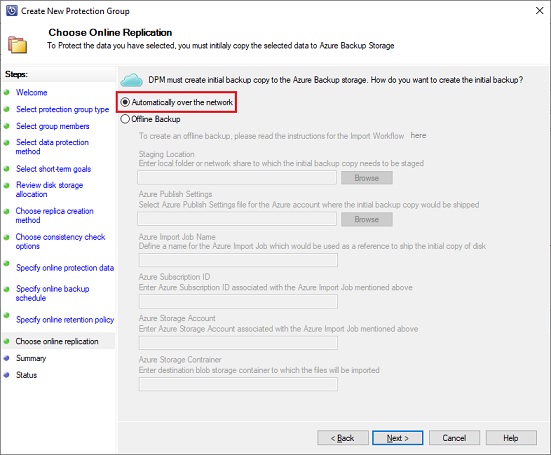
An initial copy of the protected data must be created to the Azure Backup storage. By default, it’s done over the network but in case of really big amount of data it could be done offline using import Azure feature:
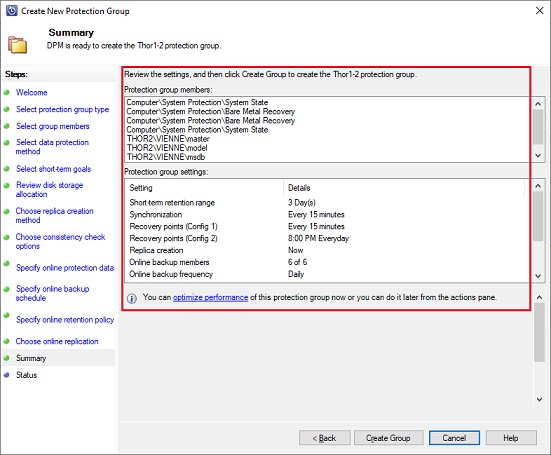
DPM is ready to create the protection group. You can review the information and validate the creation:
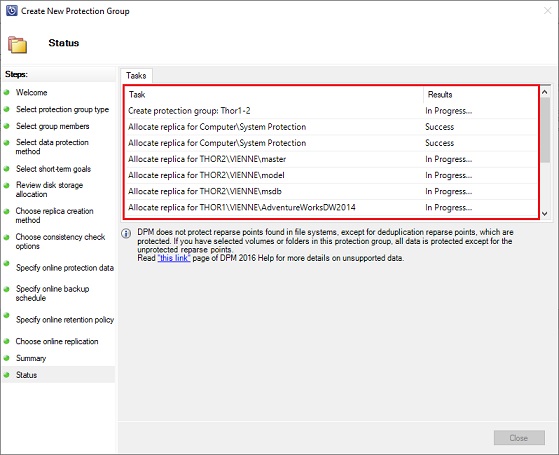
You can review the creation of the protection group progress under Status:
Now that your workload are protected you are able to restore it in case of issue.
For example if you drop by error a table in one of your protected databases you can restore it from your Azure Service Vault.
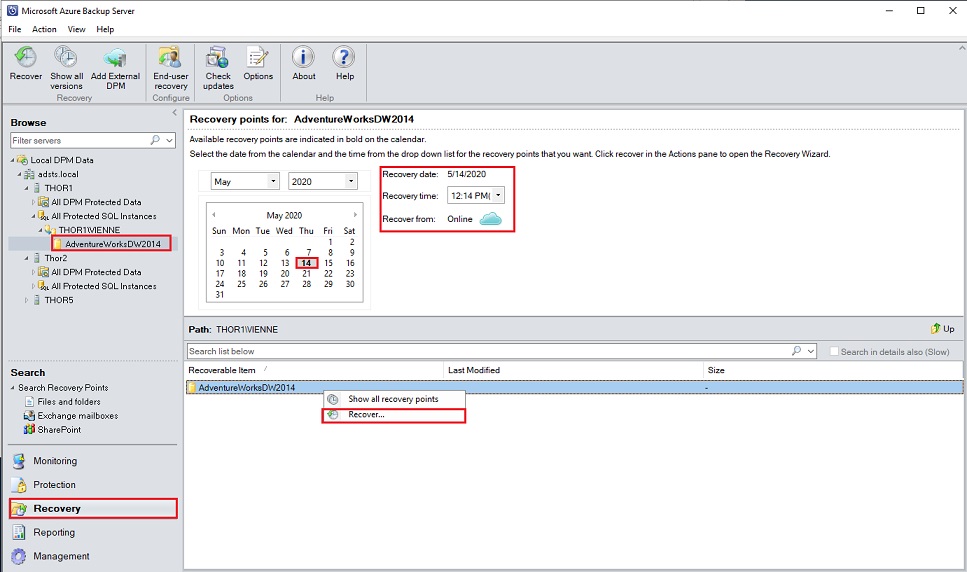
Go to Recovery tab, browse the protection group up to the database you want to restore, select the recovery date and time you would like (here an online restore) and finally right click on the database name and select Recover:
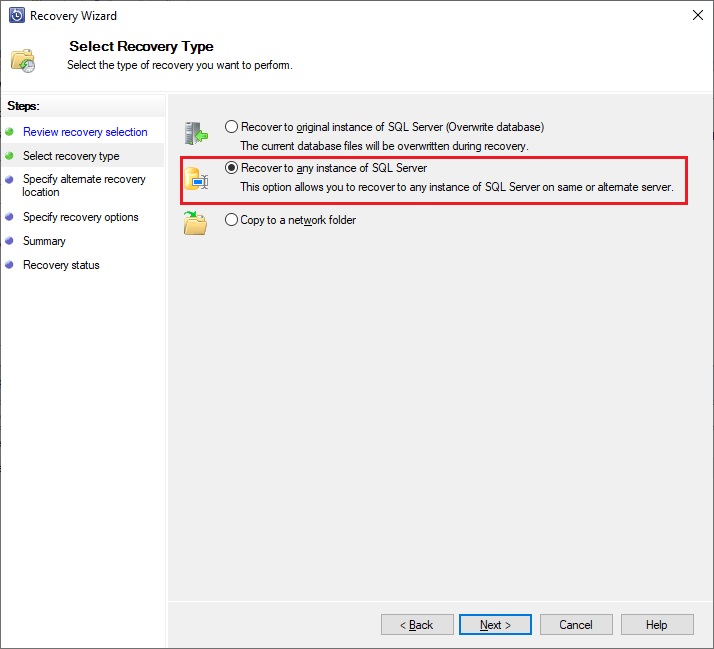
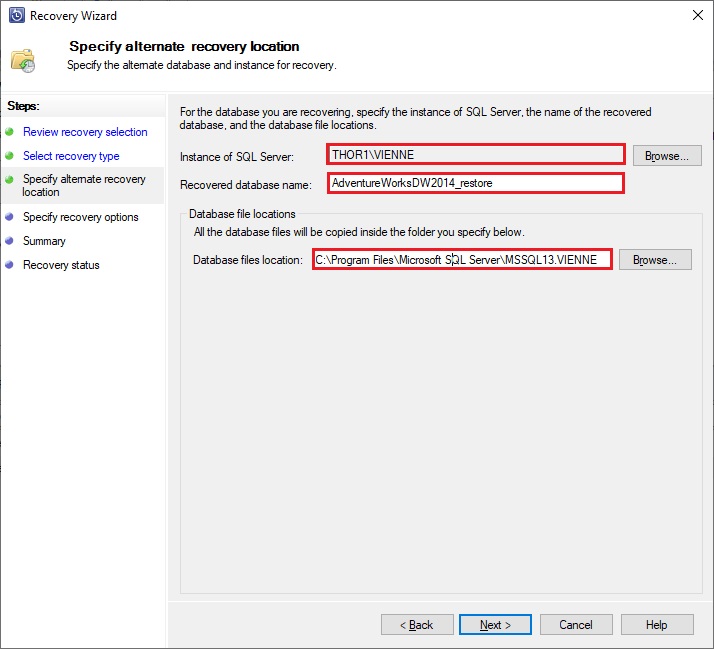
Review the information of the items you want to recover and select which type of recover you want. Here I don’t want to overwrite my database so I will restore it to the same instance but with another name. I need also to specify where my database files will be located, you cannot here specify a different location for mdf and ldf files:
You can also specify some recover option:
- throttle the network bandwidth depending on the time the recovery is running
- enable SAN based recovery using hardware snapshots
- send Email notification when the recovery is finished
After that you can review your recovery and start it:
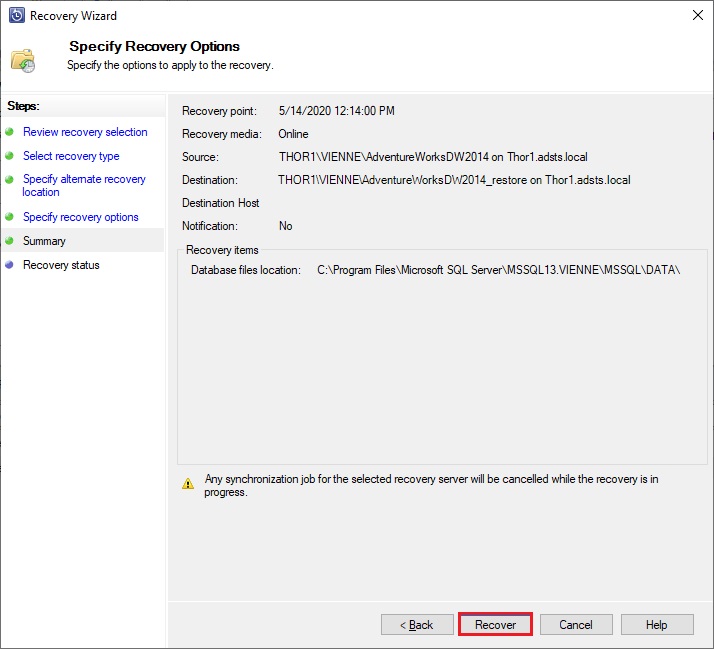
It fails… because I didn’t have previously set a staging folder to store my Azure backup during a recovery. Indeed before the Azure backup is restored to its final destination it is first saved in a staging folder which will be cleaned at the end of the process.
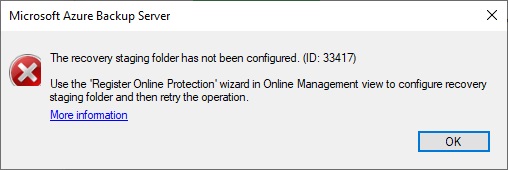
To define this folder you need to go to the Management Tab, select the Online option and click the configure icon. In the Recovery Folder Settings option select a folder with enough space to manage your future recoveries:
Enter a passphrase to encrypt all backups from the server, a PIN code (which has to be generated from your Azure Service Vault) and it’s done.
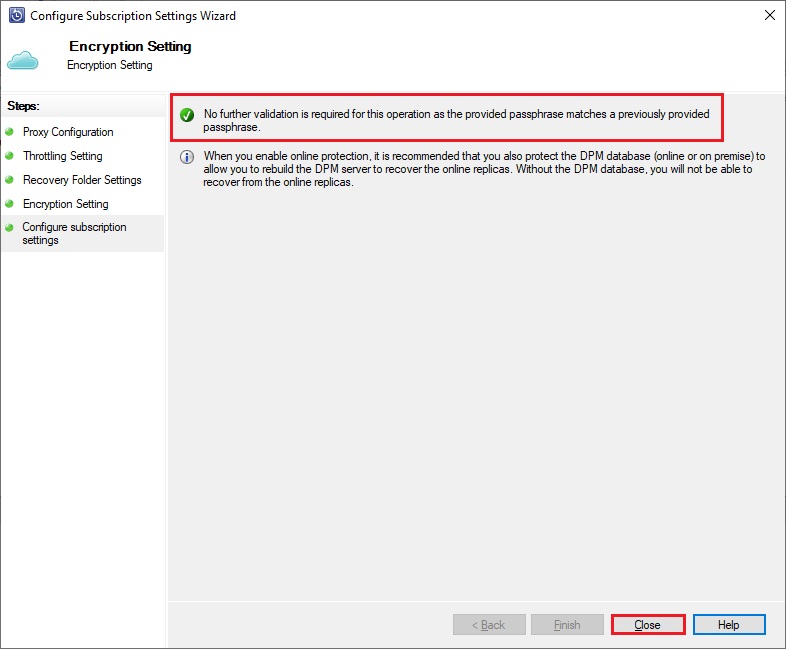
Once done, you can go back to your recovery and now the recovery process is running. You can close the wizard and go to the Monitoring Tab to check the status of the job if needed:
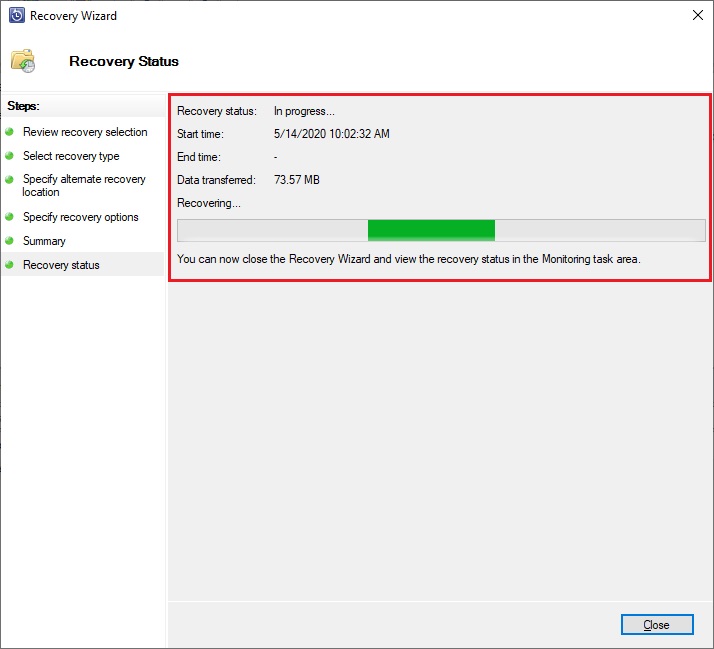
Once the recovery job is finished successfully, I have my restored database in my instance and I can restore the table dropped by mistake:
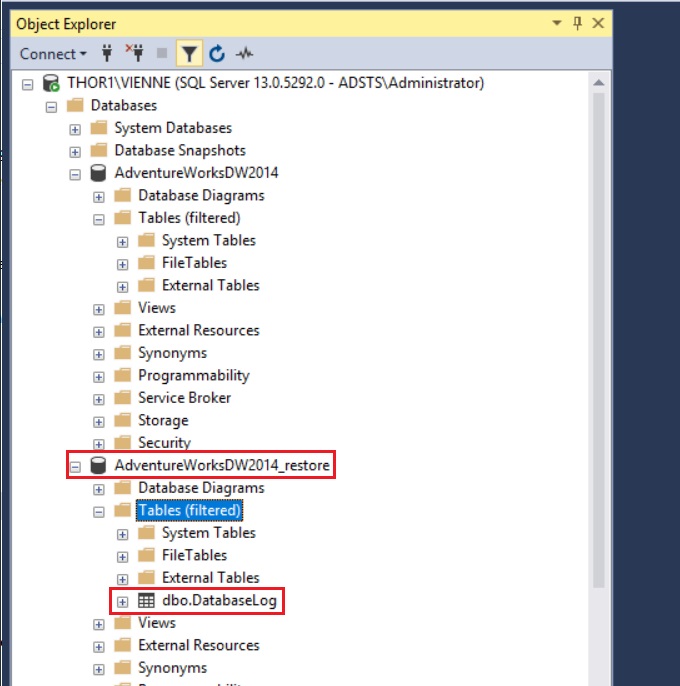
Of course, the restored database is consistent and can be used by an application.
Microsoft Azure Backup Server is a really good solution to backup SQL Server instances. If you have disk space issue in your data center and want to get rid off backup space usage which can be very space consumer or get .
Moreover by default Recovery Service Vault uses Geo-redundant storage. It means that your data are copied synchronously 3 times locally via LRS in the primary region then copied asynchronously to a secondary region where LRS create 3 copies locally.
No way to lose any data with all those replicas 😉
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/STS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)