 F
F
I wrote a blog post some time ago about using a file share witness with a minimal windows failover cluster configuration that consists of two cluster nodes. In this blog post, I told I was reluctant to use a witness in this case because it introduces a weakness in the availability process. Indeed, the system is not able to adjust node weight in this configuration but it does mean that we don’t need a witness in this case and this is what I want to clarify here. I admit myself I was wrong on this subject during for some time.
Let’s set the scene with a pretty simple Windows failover cluster architecture that includes two nodes and with dynamic quorum but without a configured witness. The node vote configuration is as follows:

At this point the system will affect randomly a node weight to the current available nodes. For instance, in my context the vote is affected to the SQL143 node but there is a weakness in this configuration. Let’s first say the node SQL141 goes down in an unplanned scenario. In this case the cluster stays functioning because the node SQL143 has the vote (last man standing). Now, let’s say this time the node SQL143 goes down in an unplanned scenario. In this case the cluster will lost the quorum because the node SQL141 doesn’t have the vote to survive. You will find related entries in the cluster event log as shown to the next picture with two specific event ids (1135 and 1177).
![]()
However in the event of the node SQL143 is gracefully shutdown, the cluster will able to remove the vote of the node SQL143 and give it to the node SQL141. But you know, I’m a follower of the murphy law: anything that can go wrong, will go wrong and it is particularly true in IT world.
So we don’t have the choice here. To protect from unplanned failure with two nodes, we should add a witness and at this point you may use either a disk or a file share witness. My preference is to promote first the disk quorum type but it is often not suitable with customers especially for geo cluster configuration. In this case using file share witness is very useful but it might introduce some important considerations about quorum resiliency. First of all, I want to exclude scenarios where the cluster resides on one datacenter. There are no really considerations here because the loose of the datacenter implies the unavailability of the entire cluster (and surely other components).
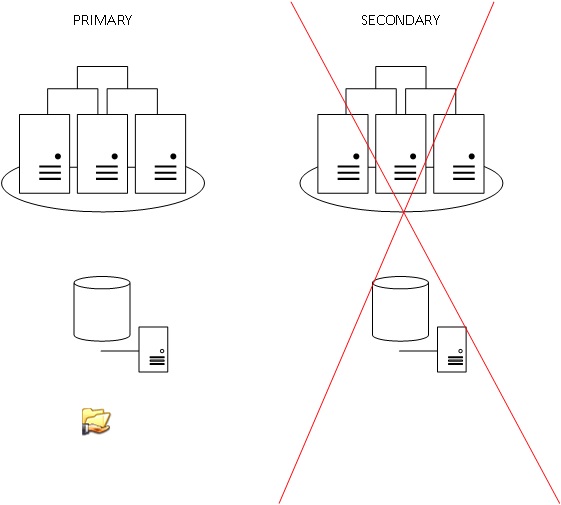
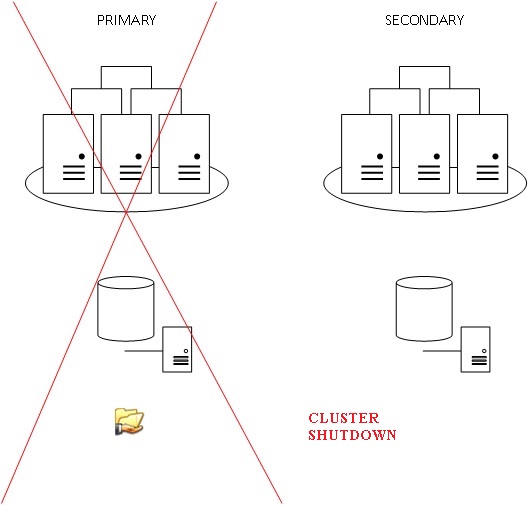
Let’s talk about geo location clusters often used with SQL Server availability groups and where important considerations must be made about the file share witness localization. Indeed, most of my customers are dealing only with two datacenters and in this case the 100$ question is where to place it? Most of time, we will place the witness in the location of what we can call the primary datacenter. If the connectivity is lost between the two datacenters the service stays functioning in the primary datacenter. However a manual activation will be required in the event of full primary data center failure.
 |
 |
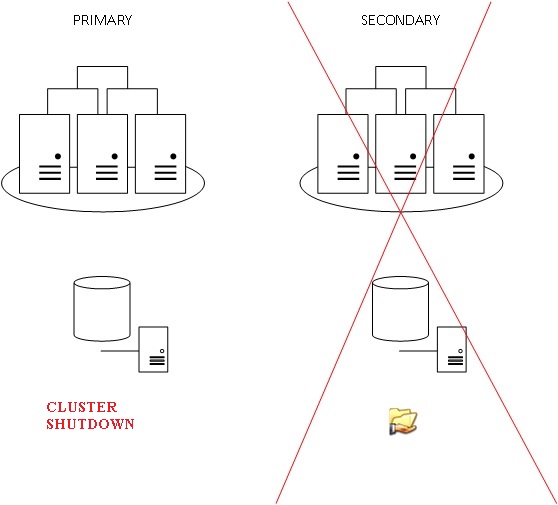
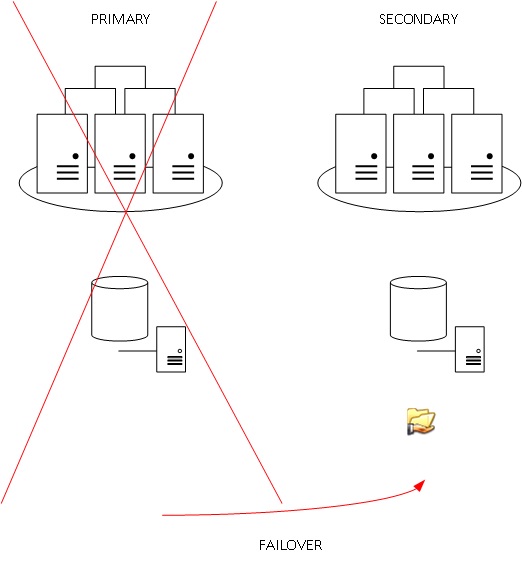
Another scenario consists in placing the witness on the secondary datacenter. Unlike our first scenario, a network failure between the two datacenters will trigger an automatic failover of the resources to the secondary datacenter but if in the event of a complete failure of the secondary datacenter, the cluster will lost the quorum (as a reminder the remaining node is not able to survive).
 |
 |
As you can see, each of aforementioned scenario have their advantages and drawbacks. A better situation would be to have a third datacenter to host the witness. Indeed, in the event of network failure between the two datacenters that host the cluster nodes, the vote will be assigned to the node which will first successfully lock the file share witness this time.
Keep in mind that even in this third case, losing the witness because either of a network failure between the two main datacenters and the third datacenter or the file share used by the witness deleted accidently by an administrator, can compromise the entire of the cluster availability in case of a node failure (one who has the vote). So be aware to monitor correctly this critical resource.
So, I would finish by a personal think. I always wondered why in the case of a minimal configuration (only 2 cluster nodes and a FSW), the cluster was not able to perform weight adjustment. Until now, I didn’t get the response from Microsoft but after some time, I think this weird behavior is quite normal. Let’s image the scenario where your file share witness resource is in failed state and the cluster is able to perform weight adjustment. Which of the nodes it may choose? The primary or the secondary? In fact it doesn’t matter because in the both cases, the next failure of the node which has the vote will also shutdown the cluster. Finally it is just delaying an inevitable situation …
Update 09.05.2017
Finally, this behavior is fully described here by Microsoft.
Happy clustering !
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)