In the first and second post in this series we did the basic pgpool setup including the watchdog configuration and then did a simple setup for automatically failover from a PostgreSQL master instance in case it goes down for any reason. In addition we told pgpool how an old master instance can be reconfigured as a new standby instance that follows the new master. In this post we’ll add another standby instance and then teach pgpool how a standby can be made aware of a new master when the master fails. Sound interesting? Lets go…
As reminder this is how the system looks like right now:
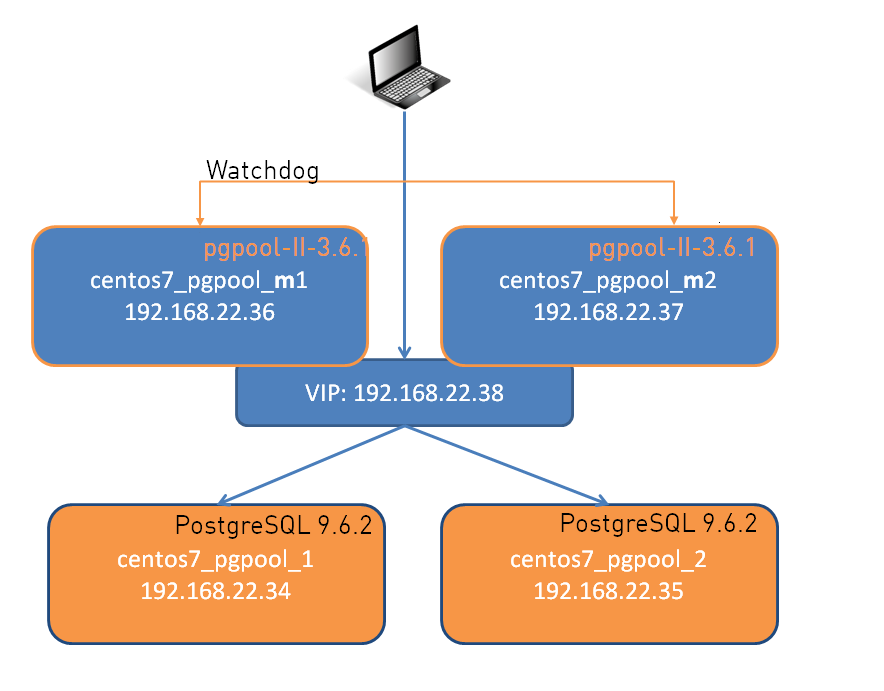
What we want to have is:
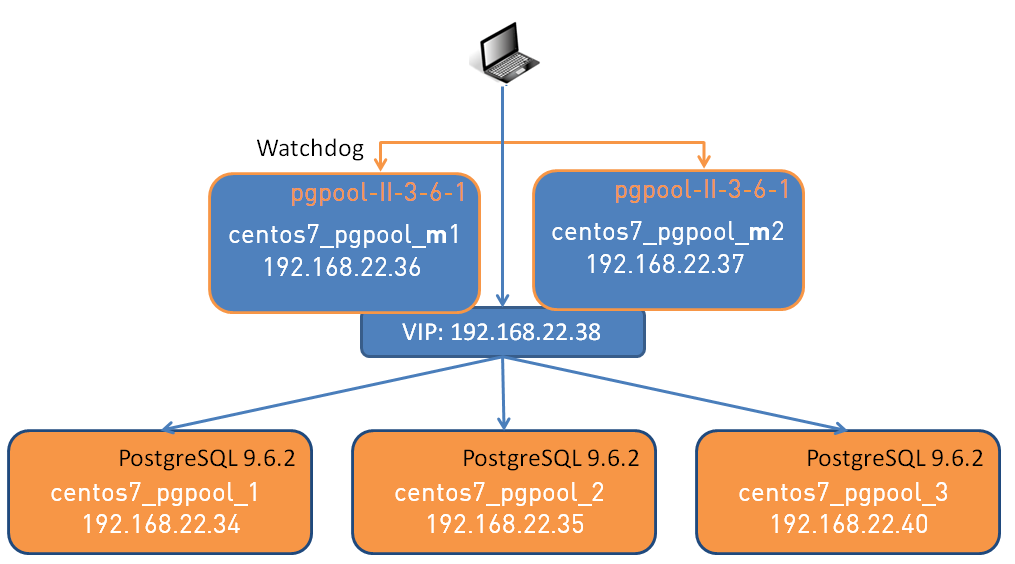
The idea behind a third node is that we always will have at least one standby server up and running in case the master node goes down. What do we need to do to bring in another instance? Once the operating system is up and running, PostgreSQL is installed it is actually quite easy. As a first step lets create the new standby database on the third node using exactly the same layout as on the other nodes:
postgres@pgpool3:/home/postgres/ [pg962] mkdir -p /u02/pgdata/PG1
postgres@pgpool3:/home/postgres/ [pg962] cd /u02/pgdata/PG1
postgres@pgpool3:/u02/pgdata/PG1/ [pg962] pg_basebackup -h 192.168.22.34 -x -D /u02/pgdata/PG1/
postgres@pgpool3:/u02/pgdata/PG1/ [pg962] echo "standby_mode = 'on'
primary_conninfo = 'host=pgpool1 user=postgres'
primary_slot_name = 'standby2'
recovery_target_timeline = 'latest'
trigger_file='/u02/pgdata/PG1/failover_trigger'" > recovery.conf
postgres@pgpool3:/u02/pgdata/PG1/ [pg962] psql -h pgpool1 -c "select * from pg_create_physical_replication_slot('standby2')" postgres
postgres@pgpool3:/u02/pgdata/PG1/ [PG1] pg_ctl -D /u02/pgdata/PG1/ start
Now we have one master instance with two standby instances attached. Lets configure the third instance into pool (the configuration change needs to be done on both pgpool nodes, of course). The lines we need to add to pgpool.conf are:
backend_hostname2 = '192.168.22.40' backend_port2 = 5432 backend_weight2 = 1 backend_data_directory2 = '/u02/pgdata/PG1' backend_flag2 = 'ALLOW_TO_FAILOVER'
Reload pgpool (a stop is not necessary) and check the current status:
[postgres@centos7_pgpool_m1 etc]$ pgpool reload [postgres@centos7_pgpool_m1 etc]$ psql -h 192.168.22.38 -c "show pool_nodes" postgres node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay ---------+---------------+------+--------+-----------+---------+------------+-------------------+------------------- 0 | 192.168.22.34 | 5432 | up | 0.333333 | primary | 0 | true | 0 1 | 192.168.22.35 | 5432 | up | 0.333333 | standby | 0 | false | 0 2 | 192.168.22.40 | 5432 | up | 0.333333 | standby | 0 | false | 0 (3 rows)
We have a second standby database which is used to load balance read requests. In case the master fails now what we want is that one of the standby instances gets promoted and the remaining standby instance should be reconfigured to follow the new master. What do we need to do?
As we are using replication slots in this setup we need a way to make the failover scripts independent of the name of the replication slot. The first script that we need to change is “promote.sh” on all the PostgreSQL nodes because currently there is a hard coded request to create the replication slot:
#!/bin/bash
PGDATA="/u02/pgdata/PG1"
PATH="/u01/app/postgres/product/96/db_2/bin/:$PATH"
export PATH PGDATA
pg_ctl promote -D ${PGDATA} >> /var/tmp/failover.log
psql -c "select * from pg_create_physical_replication_slot('standby1')" postgres >> /var/tmp/failover.log
The easiest way to do this is to create as many replication slots as you plan to add standby instances, e.g.:
#!/bin/bash
PGDATA="/u02/pgdata/PG1"
PATH="/u01/app/postgres/product/96/db_2/bin/:$PATH"
export PATH PGDATA
pg_ctl promote -D ${PGDATA} >> /var/tmp/failover.log
psql -c "select * from pg_create_physical_replication_slot('standby1')" postgres >> /var/tmp/failover.log
psql -c "select * from pg_create_physical_replication_slot('standby2')" postgres >> /var/tmp/failover.log
psql -c "select * from pg_create_physical_replication_slot('standby3')" postgres >> /var/tmp/failover.log
psql -c "select * from pg_create_physical_replication_slot('standby4')" postgres >> /var/tmp/failover.log
Of course this is not a good way to do it as you would need to adjust the script every time the amount of standby instances changes. One better way to do it is to centrally manage the amount of standby instances and the relation of the standby instances to the replication slots in a configuration in the $PGDATA directory of each PostgreSQL node and on each pgpool node in the HOME directory of the postgres user:
postgres@pgpool1:/u02/pgdata/PG1/ [PG1] cat pgpool_local.conf # the total amount of instances that # participate in this configuration INSTANCE_COUNT=3 # the mapping of the hostname to # to the replication slot it uses for # the PostgreSQL instance it is running # in recovery mode 192.168.22.34=standby1 192.168.22.35=standby2 192.168.22.40=standby3
Having this we can adjust the promote.sh script (sorry I have to use a screenshot as the source code destroys the formatting of this post. let me know if you want to have the script):
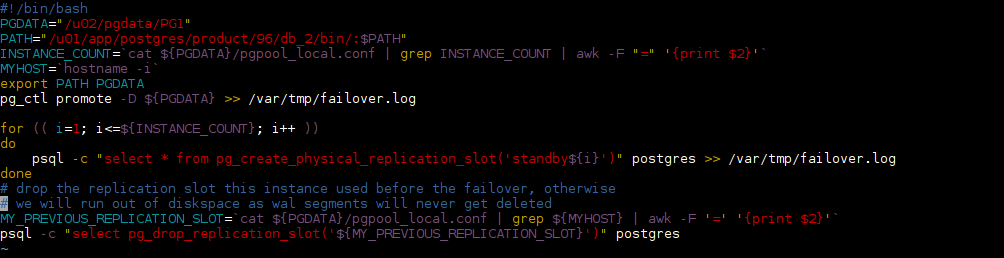
Now the script will create all the replication slots on a promoted instance and in addition drops the replication slot it used before being promoted. What else do we need? As we now have a third instance in the configuration there is another point we need to take care of: When the master fails a new standby is promoted, so far so good. But in addition we want the second standby to follow the new master automatically, don’t we? For this we need to tell pgpool to call another script which is executed on the active pgpool node after failover:
[postgres@centos7_pgpool_m1 ~]$ grep follow /u01/app/postgres/product/pgpool-II/etc/pgpool.conf follow_master_command = '/home/postgres/follow_new_master.sh "%h" "%H"'
This will be executed when there is failover (all pgpool nodes need to have this script)
#!/bin/sh
set -x
master_node_host_name=$2
detached_node_host_name=$1
tmp=/tmp/mytemp$$
trap "rm -f $tmp" 0 1 2 3 15
PGDATA="/u02/pgdata/PG1"
PATH="/u01/app/postgres/product/96/db_2/bin/:$PATH"
RECOVERY_NODE_REPLICATION_SLOT=`cat /home/postgres/pgpool_local.conf | grep ${detached_node_host_name} | awk -F '=' '{print $2}'`
export PATH PGDATA
# make sure the instance is down
ssh -T $detached_node_host_name /home/postgres/stop_instance.sh
cat > $tmp <<EOF
standby_mode = 'on'
primary_conninfo = 'host=$master_node_host_name user=postgres'
primary_slot_name = '${RECOVERY_NODE_REPLICATION_SLOT}'
recovery_target_timeline = 'latest'
trigger_file='/u02/pgdata/PG1/failover_trigger'
EOF
scp $tmp $detached_node_host_name:$PGDATA/recovery.conf
ssh ${detached_node_host_name} /home/postgres/start_instance.sh
psql -c "select 'done'" postgres
So, this is the status now:
[postgres@centos7_pgpool_m1 ~]$ psql -h 192.168.22.38 -c "show pool_nodes" postgres node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_dela y ---------+---------------+------+--------+-----------+---------+------------+-------------------+----------------- 0 | 192.168.22.34 | 5432 | up | 0.333333 | primary | 4 | true | 0 1 | 192.168.22.35 | 5432 | up | 0.333333 | standby | 2 | false | 0 2 | 192.168.22.40 | 5432 | up | 0.333333 | standby | 0 | false | 0 (3 rows)
Lets shutdown the primary and see what happens:
postgres@pgpool1:/home/postgres/ [PG1] pg_ctl -D /u02/pgdata/PG1/ stop -m immediate waiting for server to shut down.... done server stopped
Pgpool is telling this:
[postgres@centos7_pgpool_m1 ~]$ psql -h 192.168.22.38 -c "show pool_nodes" postgres node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_dela y ---------+---------------+------+--------+-----------+---------+------------+-------------------+----------------- -- 0 | 192.168.22.34 | 5432 | down | 0.333333 | standby | 4 | false | 0 1 | 192.168.22.35 | 5432 | up | 0.333333 | primary | 4 | true | 0 2 | 192.168.22.40 | 5432 | down | 0.333333 | standby | 0 | false | 0 (3 rows)
Re-attach:
[postgres@centos7_pgpool_m1 ~]$ pcp_attach_node -w -n 0 pcp_attach_node -- Command Successful [postgres@centos7_pgpool_m1 ~]$ pcp_attach_node -w -n 2 pcp_attach_node -- Command Successful [postgres@centos7_pgpool_m1 ~]$ psql -h 192.168.22.38 -c "show pool_nodes" postgres node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_dela y ---------+---------------+------+--------+-----------+---------+------------+-------------------+----------------- -- 0 | 192.168.22.34 | 5432 | up | 0.333333 | standby | 4 | false | 0 1 | 192.168.22.35 | 5432 | up | 0.333333 | primary | 4 | true | 0 2 | 192.168.22.40 | 5432 | up | 0.333333 | standby | 0 | false | 0 (3 rows)
Perfect. The only pain point is that we need to manually re-attach the nodes, everything else is automated. But, luckily there is way to get around this: As we are on the pgpool nodes when the script is executed we can just use pcp_attach_node at the end of the follow_new_master.sh script (and pass the node id %d into the script):
[postgres@centos7_pgpool_m1 ~]$ grep follow /u01/app/postgres/product/pgpool-II/etc/pgpool.conf
follow_master_command = '/home/postgres/follow_new_master.sh "%h" "%H" %d'
[postgres@centos7_pgpool_m1 ~]$ cat follow_new_master.sh
#!/bin/sh
set -x
master_node_host_name=$2
detached_node_host_name=$1
detached_node_id=$3
tmp=/tmp/mytemp$$
trap "rm -f $tmp" 0 1 2 3 15
PGDATA="/u02/pgdata/PG1"
PATH="/u01/app/postgres/product/96/db_2/bin/:$PATH"
RECOVERY_NODE_REPLICATION_SLOT=`cat /home/postgres/pgpool_local.conf | grep ${detached_node_host_name} | awk -F '=' '{print $2}'`
export PATH PGDATA
# make sure the old master is down
ssh -T $detached_node_host_name /home/postgres/stop_instance.sh
cat > $tmp <<EOF
standby_mode = 'on'
primary_conninfo = 'host=$master_node_host_name user=postgres'
primary_slot_name = '${RECOVERY_NODE_REPLICATION_SLOT}'
recovery_target_timeline = 'latest'
trigger_file='/u02/pgdata/PG1/failover_trigger'
EOF
scp $tmp $detached_node_host_name:$PGDATA/recovery.conf
ssh ${detached_node_host_name} /home/postgres/start_instance.sh
psql -c "select 'done'" postgres
pcp_attach_node -w -n ${detached_node_id}
And now, when you shutdown the master everything is automatic. Hope this helps.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)