After my first two blogs about cloud witness and domain-less dependencies features shipped with Windows Server 2016, it’s time to talk about another pretty cool feature of the WSFC : site awareness that will also benefit to our SQL Server FCIs and availability groups.
But before to talk further about the potential benefits of this new feature, let’s go back to the previous and current version of Windows Server that is 2012 R2. Firstly, let’s assume we have a Windows failover cluster environment that includes 4 nodes spread evenly across two data centers and a FSW on a third datacenter as well.
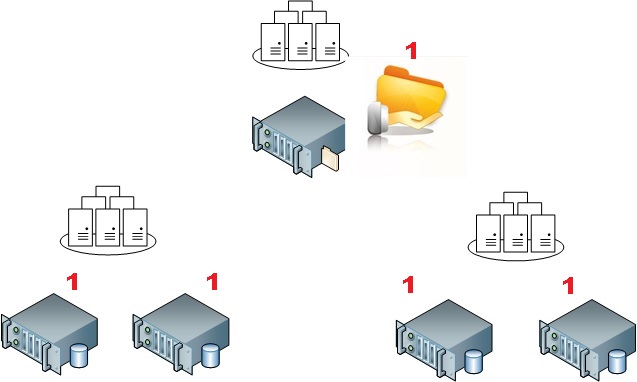
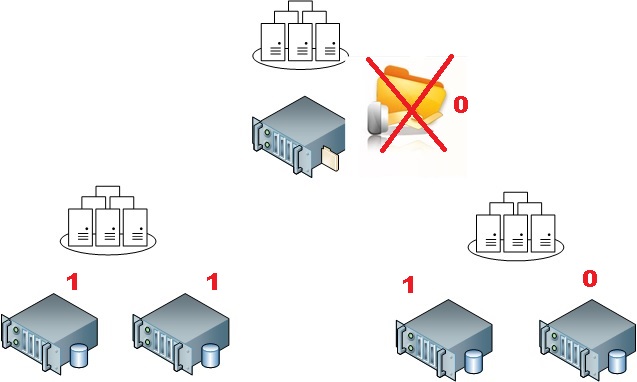
Assuming we use the dynamic quorum feature, all the node members and the FSW as well will get a vote in this specific context. If we lose the FSW, the system is intended to reevaluate dynamically the situation and it has to drop weight for a cluster node. We are able to influence its behaviour by configuring the LowerQuorumPriorityNodeID property (please refer the end of my blog here). For example, if we want to maximize the availability of the Windows failover cluster on the first datacenter (on the left), we have to change the quorum priority of one of the cluster node on the second datacenter (on the right) as shown below:
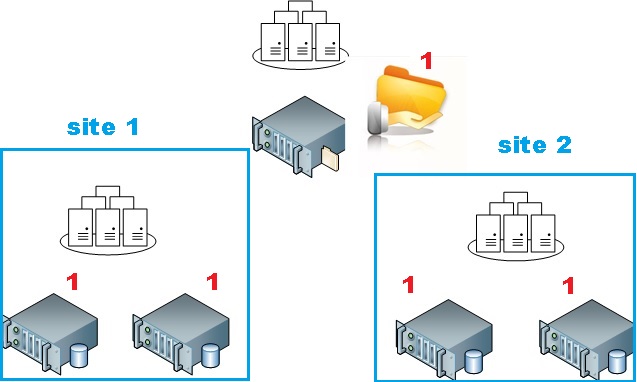
Now, with Windows Server 2016, this property is deprecated and the site awareness feature will replace it. We will able to define and group cluster member nodes into sites. So let’s assume we want to achieve the same design than previously. To meet the same requirements, we have to define two sites and give the priority to the first site (on the left).
Actually, sites and site preference may be configured only by using PowerShell and the new property site by using the following syntax:
(Get-ClusterNode –Name <node>).Site=<site number>
For example, on my test lab, I have configured two sites at the cluster node level to reflect the situation shown on the above.

Then, I have configured my preferred site at the cluster level in order to prioritize my first datacenter to survive to the 50/50 failure scenario (by changing the PreferredSite property):
(Get-Cluster).PreferredSite=<site number>
Now let’s simulate we face a failure of the FSW and let’s take a look at the new node weight configuration
- Cluster nodes

- FSW
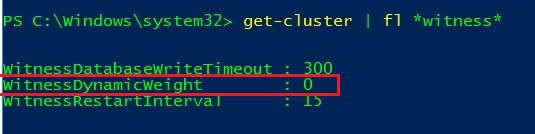
Ok, my configuration seems to work correctly and the FSW has played its role (tie break) by dropping a weight for the WIN20164 node. Go ahead and let’s simulate a failure of the second datacenter (WIN20163 and WIN20164 down) to check if the first will survive…
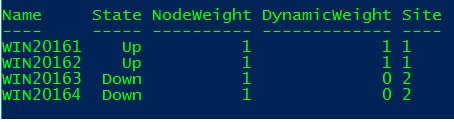
Great job! And the system has automatically reevaluate the overall node weight configuration (the system has dropped the weight for the failed nodes). We may also notice the action taken by the Windows Failover Cluster in the cluster log as shown below:

At the first glance, I guess you are saying “ok but this is just a replacement of the old LowerQuorumPriorityNodeID … nothing more …” but fortunately there are more. Keep reading the next part of this blog post 🙂
The second interesting topic concerns the ability to better predict the next role’s location during failover events. Indeed, with Windows 2012 and previous versions, you had to play manually with the preferred owners list to control the failover order of the corresponding role. Fortunately, Windows 2016 introduces another parameter preferred site that tends to make this task easier.
Let’s say I added two SQL Server FCIs (INST1 and INST3) to my previous environment and now I want to prioritize the INST1 instance on the datacenter1 and the INST2 instance on the datacenter2 (aka multi master datacenters). In other words, I want the INST1 and INST2 instances fail over first to their respective cluster nodes in the same site before the others.
We have to define the preferred site at the role level as follows:
(Get-ClusterGroup –Name <group name>).PreferredSite =<site number>

My initial scenario consists in starting each instance in their respective preferred site with INST1 on the node 1 and INST2 on the node 3.
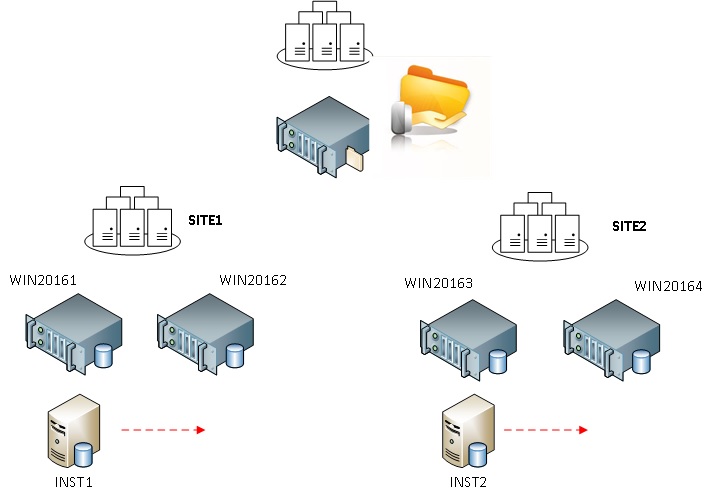
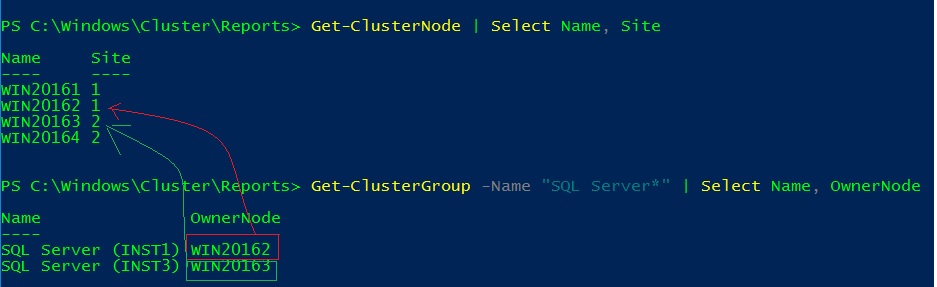
Then I simulated a failure of the node WIN20163 and I expected to see the INST2 instance to failover to the WIN20164 node and this is exactly what it happened and vis vers ca (failure of the WIN20164 cluster node). Of course if no cluster nodes are available from the preferred site, the concerned role will failover to the next other available node.


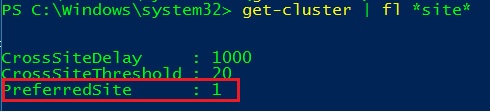
Finally the last topic concerns the new heartbeat settings that come with the new site awareness feature. When we define sites between cluster nodes we also have the ability to define new heartbeat properties as CrossSiteDelay and CrossSiteThreshold as shown below:
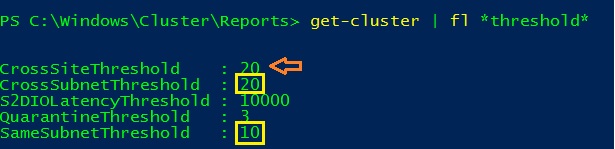
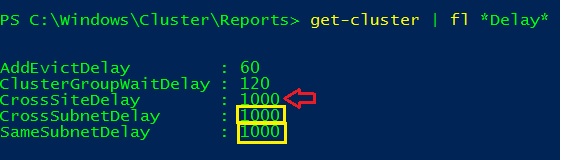
By default, the cross-site threshold is defined to 20s whereas the intra-site threshold (that corresponds to the same subnet threshold) is configured to 10s. According to the Microsoft blog here, CrossSiteDelay and CrossSiteThreshold may supersede other existing parameters regarding the scenario.
Thus in my case, I have to deal with two different thresholds (same subnet – 10s – and cross site – 20s-). I may confirm these two values by taking a look at the concerned cluster log record after the failover of both the WIN2013 and the WIN2014 nodes.
- WIN20131 (192.168.10.22) – WIN20164 (192.168.10.24) – same site

- WIN20131 (192.168.10.20) –WIN20163 (192.168.10.24) – cross-site

At this point, you may also wonder why introducing these two new site heartbeat parameters when you may already deal with the existing parameters as SameSubnet* and CrossSubnet*. Well the new site settings will provide us more flexibility to define heartbeats by using the site concept. Let’s demonstrate with the following (real) customer scenario that includes AlwaysOn availability groups that run on the top of the WSFC with 3 nodes spread on 3 different data centers and a stretch vlan.
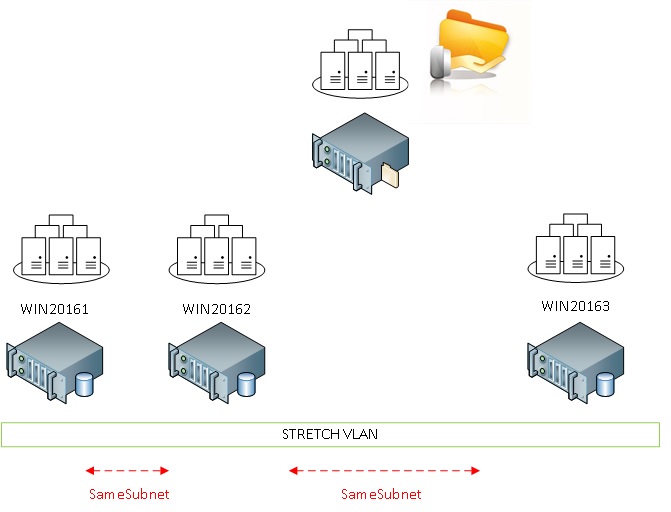
There is a high bandwidth network link between the two first data centers (with a low latency) and a less efficient network link between the third database and the others (heterogeneous configuration). In fact the third site was dedicated for DR in this context.
With Windows 2012R2, I may be limited by the only available parameter : SameSubnetThreshold regarding my scenario (all of the cluster nodes are on the same subnet here). This parameter may influence the hearbeat setting for all the nodes and I only want to get a more relaxed monitoring for the third node WIN2013.
With Windows 2016, the game will probably change and I would group WIN20161 and WIN20162 into the same “logical” site and leave WIN20163 alone into its own site. Thus, I could benefit to the cross-site parameters that will supersede the same subnet parameters between the [WIN20161-WIN20162] and [WIN20163] without influencing to the monitoring between WIN20161 and WIN20162 (that are in the same site). The new picture would be as follows:
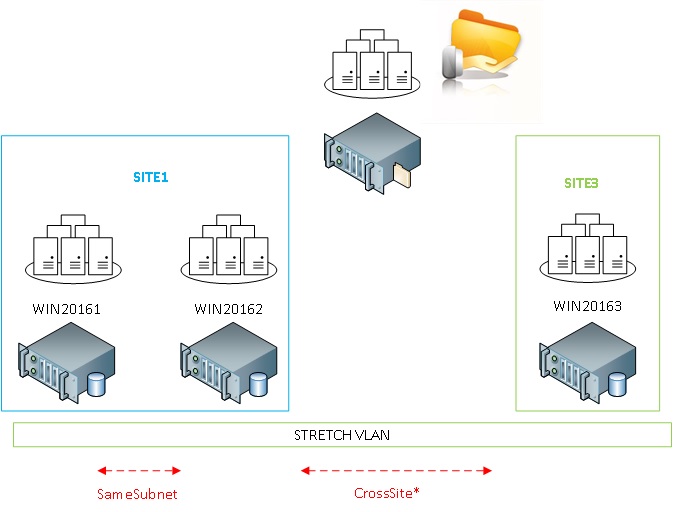
This new configuration will give me more flexibility to configure aggressive or relaxed monitoring between nodes on different sites but on the same subnet.
Happy clustering!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)